

Voice call data processing method and device, storage medium, and mobile terminal
A technology for voice calls and mobile terminals, applied in the fields of voice call data processing methods, storage media, mobile terminals, and devices, can solve the problems of complex sound, affecting users' use, and prone to whistling, and achieve the effect of reducing inconvenience
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
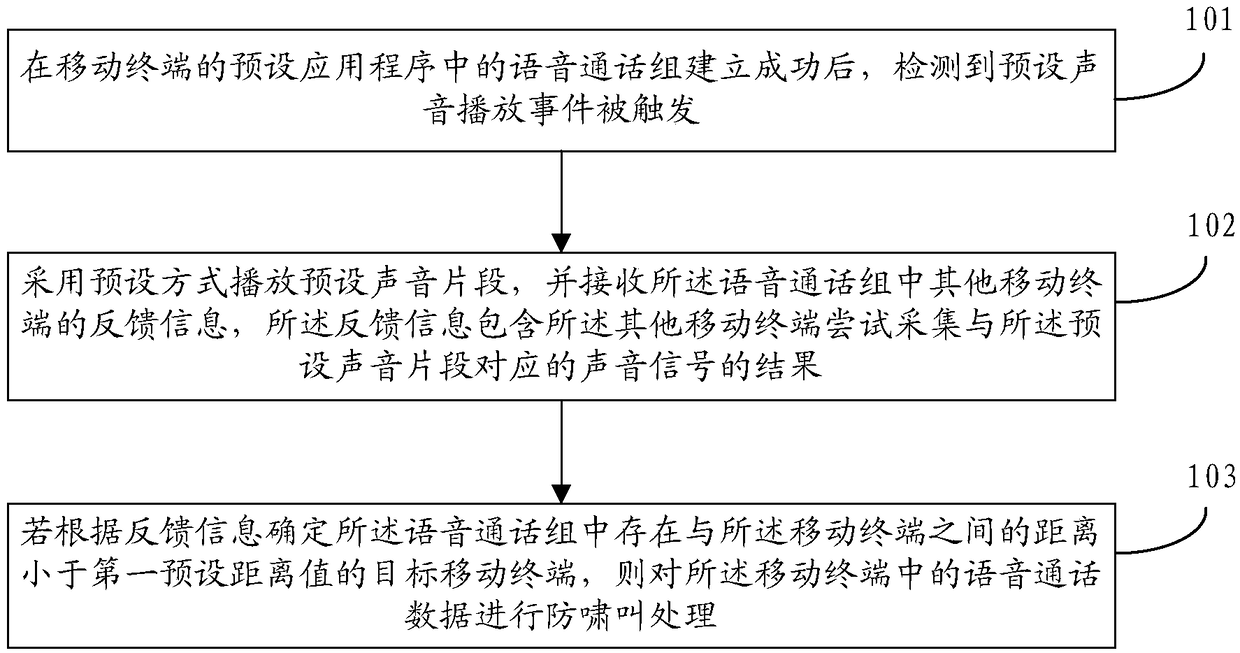
[0026] The technical solution of the present application will be further described below in conjunction with the accompanying drawings and through specific implementation methods. It should be understood that the specific embodiments described here are only used to explain the present application, but not to limit the present application. In addition, it should be noted that, for the convenience of description, only some structures related to the present application are shown in the drawings but not all structures.
[0027] Before discussing the exemplary embodiments in more detail, it should be mentioned that some exemplary embodiments are described as processes or methods depicted as flowcharts. Although the flowcharts describe the steps as sequential processing, many of the steps may be performed in parallel, concurrently, or simultaneously. Additionally, the order of steps may be rearranged. The process may be terminated when its operations are complete, but may also hav...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More