

Speaker recognition method based on multi-stream hierarchical fusion transform features and long-short-term memory network
A long- and short-term memory and speaker recognition technology, applied in the field of speaker recognition, can solve the problems of not being able to characterize the differences in the deep characteristics of speakers from multiple aspects, the recognition results will become worse, and better results cannot be obtained.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

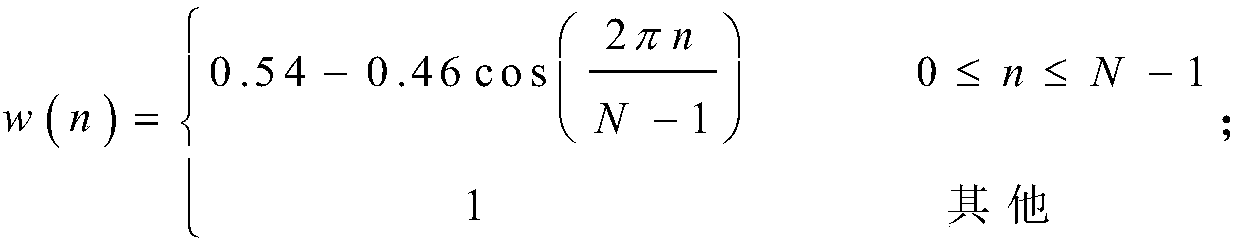
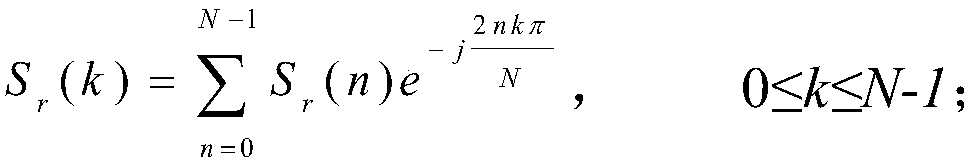
Examples
Embodiment
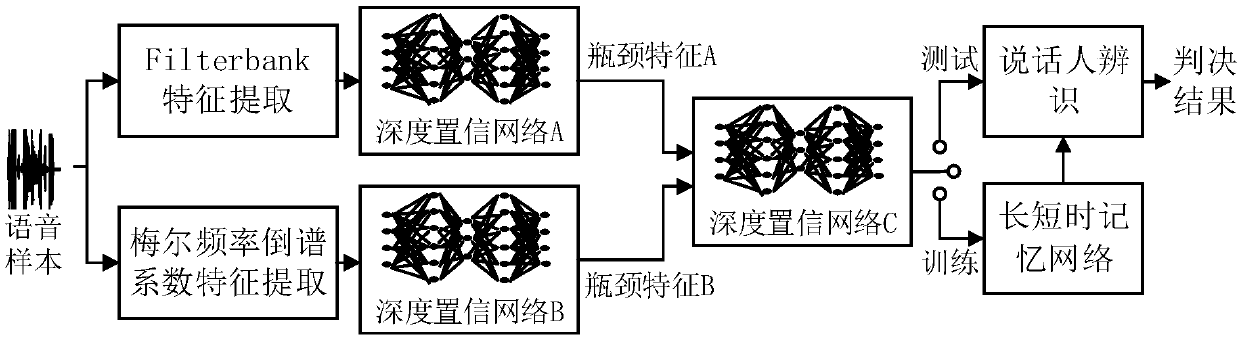
[0079] Such as figure 1 Shown is the flow chart of the embodiment of the present invention, and concrete steps are as follows:
[0080] S1. Acoustic feature extraction: Extracting Filterbank features and MFCC features from speech samples, specifically including the following steps:
[0081] S1.1. Pre-emphasis: f(z)=1-αz -1 Filter the input speech for the transfer function, where the value range of α is [0.9,1];
[0082] S1.2. Framing: After pre-emphasis, the voice is divided into voice frames of a specific length, and the frame length is L, the frame shift is S, and the voice of the rth frame is expressed as x r (n), where 1≤r≤R, 0≤n≤N-1, R and N represent the number of frames and the sampling points of each frame of speech respectively;
[0083] S1.3. Windowing: Multiply each frame of speech by the window function w(n), and the window function is a Hamming window, which is recorded as:
[0084]
[0085] S1.4. Extracting Filterbank features and MFCC features, the specif...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More