

Voice classification method and device, server and storage medium
A classification method and classifier technology, applied in the field of Internet technology applications, can solve the problems of ignoring the deep information of voice content, rough evaluation, etc., and achieve the effect of fast and effective classification processing.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
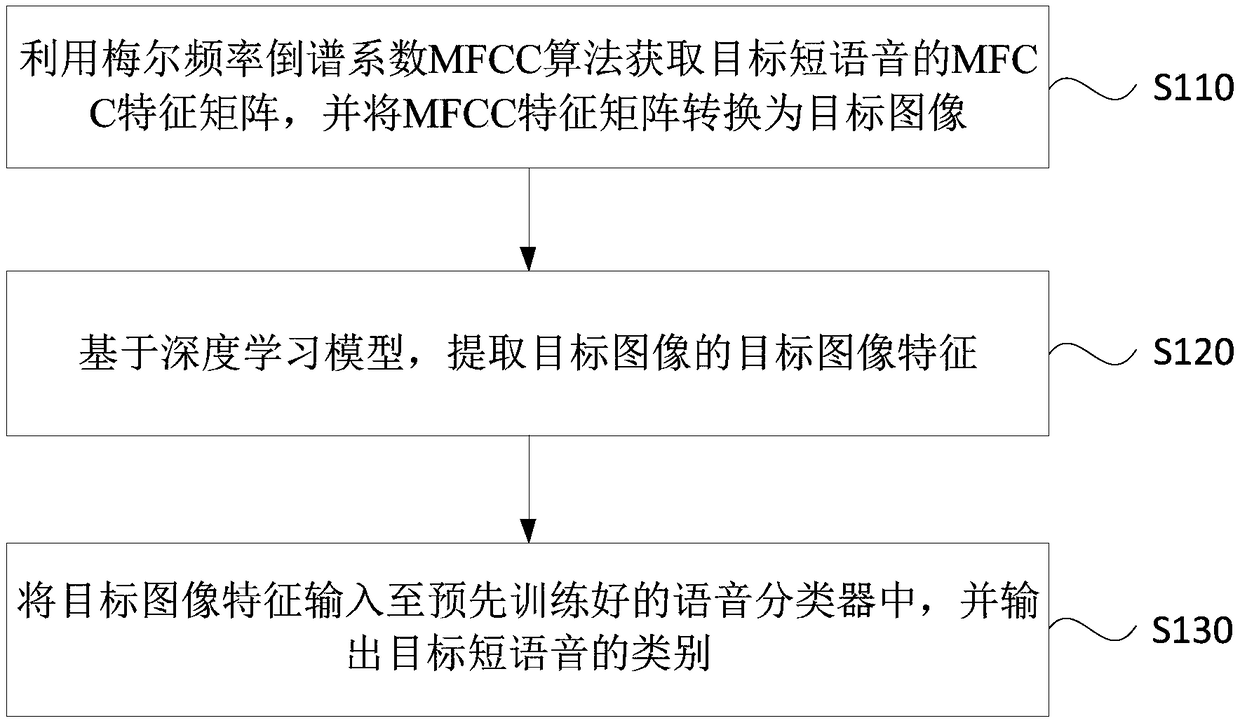
[0026] figure 1 It is a flow chart of a speech classification method provided by Embodiment 1 of the present invention. This embodiment is applicable to the situation where speech classification is implemented based on deep information of speech content among numerous speech data. This method can be implemented by a speech classification device Execution, wherein the device may be implemented by software and / or hardware. Such as figure 1 As shown, the method of this embodiment specifically includes:
[0027] S110. Obtain the MFCC feature matrix of the target short speech by using the MFCC algorithm of Mel-frequency cepstral coefficients, and convert the MFCC feature matrix into a target image.
[0028] Among them, the Mel frequency is proposed based on the auditory characteristics of the human ear, and has a nonlinear corresponding relationship with the HZ frequency. Among them, the auditory characteristic of the human ear is that the human ear has different perception capa...
Embodiment 2
[0074] figure 2 It is a flow chart of a speech classification method provided by Embodiment 2 of the present invention. In this embodiment, on the basis of the above-mentioned embodiments, the optional conversion of the MFCC feature matrix into a target image includes: adjusting the row-column ratio of the MFCC feature matrix according to a first preset rule, so that the row-column ratio It is the same as the preset aspect ratio of the target image; the MFCC feature matrix after adjusting the row-column ratio is converted into a grayscale image, wherein each element in the MFCC feature matrix after adjusting the row-column ratio corresponds to the A grayscale value in the grayscale image; converting the grayscale image into an RGB three-primary-color image, and using the RGB three-primary-color image as the target image. Further, before adjusting the ratio of rows and columns of the MFCC feature matrix according to the preset first rule, it is optional to further include: pe...
Embodiment 3
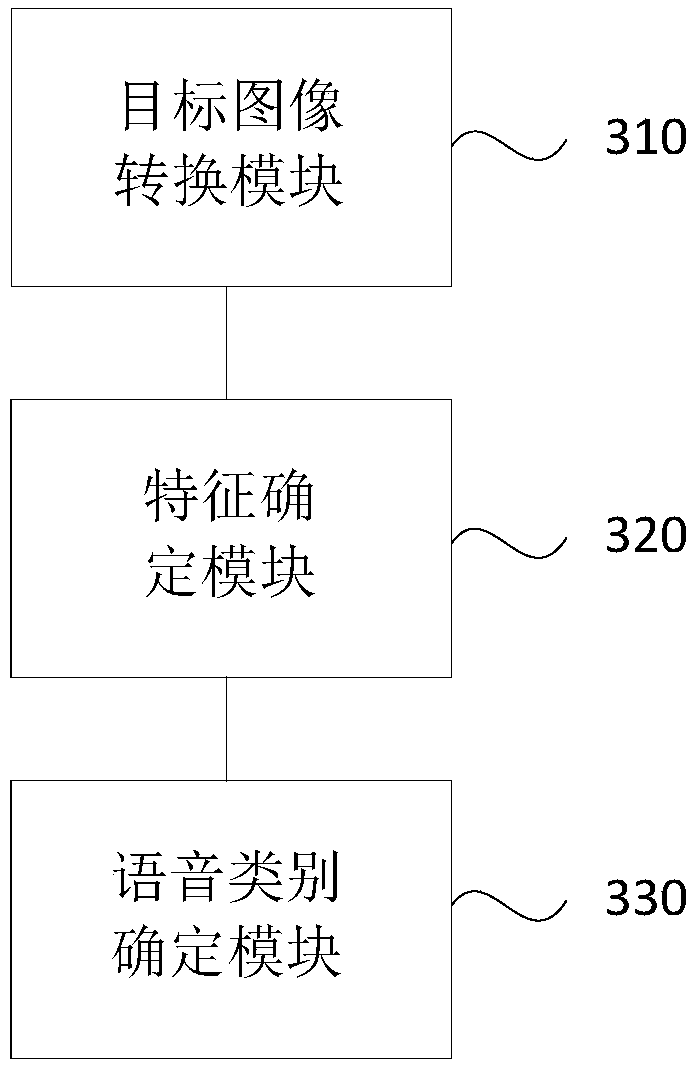
[0100] image 3 It is a structural schematic diagram of a speech classification device in Embodiment 3 of the present invention. Such as image 3 As shown, the voice classification device includes:
[0101] Target image conversion module 310, for utilizing Mel frequency cepstral coefficient MFCC algorithm to obtain the MFCC feature matrix of target short speech, and MFCC feature matrix is converted into target image;
[0102] The feature determination module 320 is used to extract the target image features of the target image based on the deep learning model;
[0103] The voice category determination module 330 is configured to input the features of the target image into a pre-trained voice classifier, and output the category of the target short voice.
[0104] The voice classification device that the embodiment of the present invention provides uses the MFCC algorithm to obtain the MFCC feature matrix of the target short speech through the target image conversion module,...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More