Story data processing method and system for intelligent robot
An intelligent robot and data processing technology, applied in the computer field, can solve problems such as poor user experience and the inability to achieve real people's voice and emotion, and achieve the effect of improving user experience
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
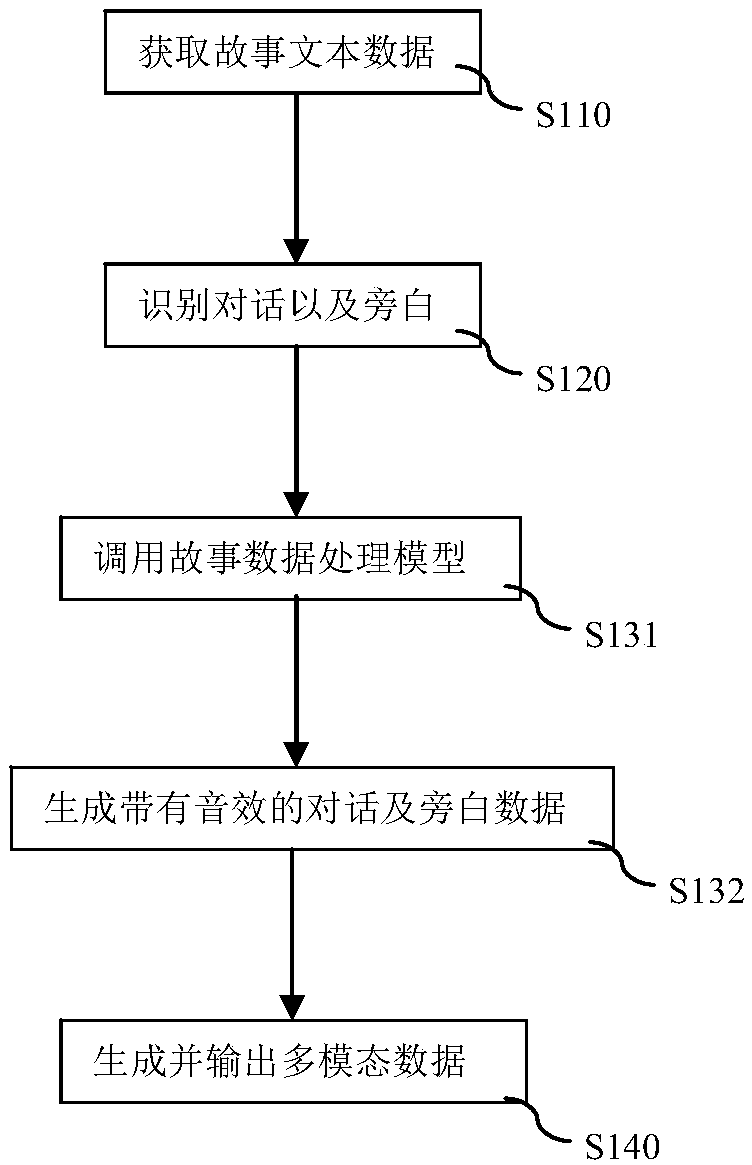
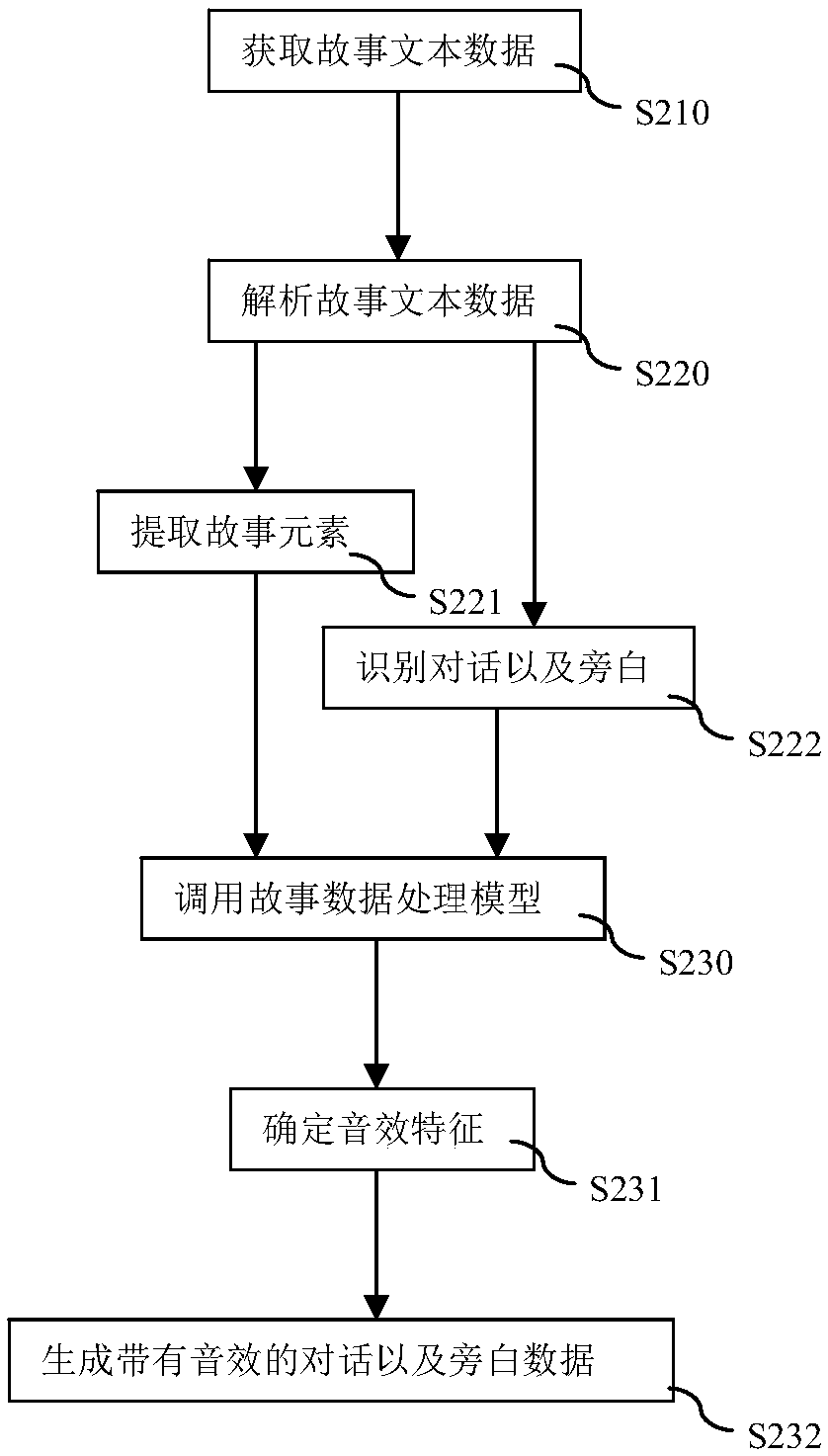
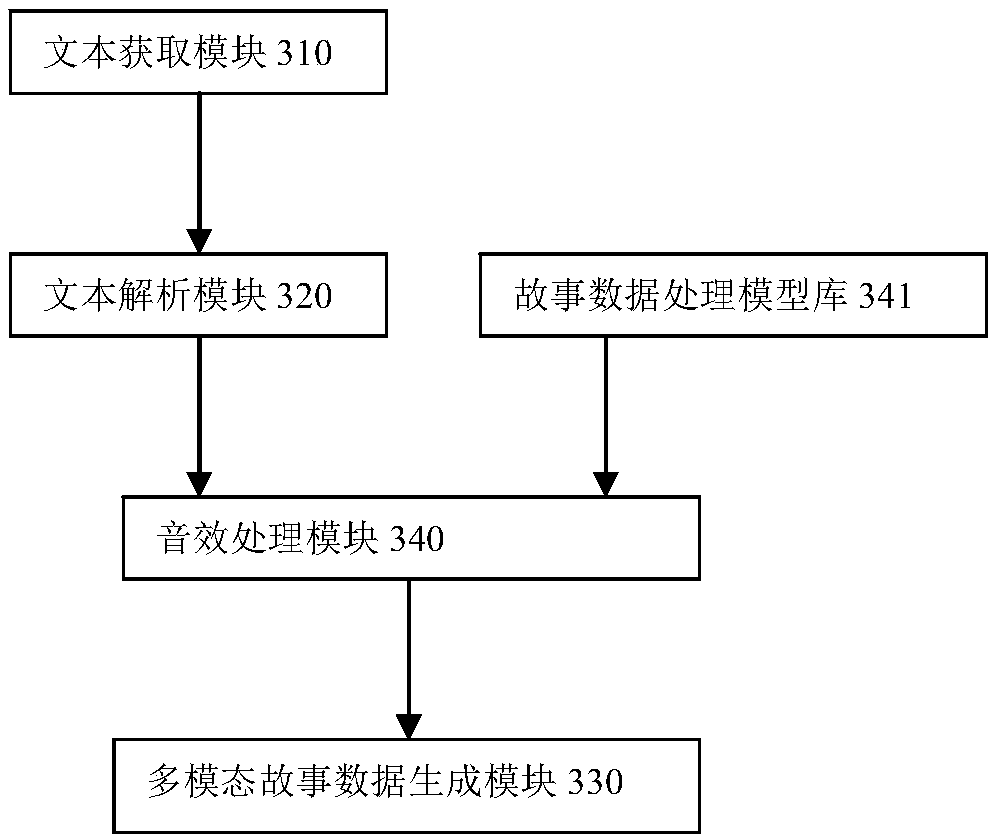
[0043] The implementation of the present invention will be described in detail below in conjunction with the accompanying drawings and examples, so that implementers of the present invention can fully understand how the present invention uses technical means to solve technical problems, and achieve the realization process of technical effects and according to the above-mentioned realization process The present invention is implemented concretely. It should be noted that, as long as there is no conflict, each embodiment and each feature in each embodiment of the present invention can be combined with each other, and the formed technical solutions are all within the protection scope of the present invention.
[0044] In traditional human daily life, text reading is the main way for people to appreciate literary works. However, in some specific scenarios, people also appreciate literary works through sound, for example, listening to storytelling, listening to recitations, etc. T...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



