

Speaker identification method based on deep stack autoencoder network
A technology of speaker recognition and self-encoding network, applied in speech analysis, instruments, etc., can solve problems such as limiting model performance, achieve the effects of improving recognition performance, reducing system performance impact, and improving robustness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0034] In order to facilitate those of ordinary skill in the art to understand and implement the present invention, the present invention will be described in further detail below in conjunction with the examples. It should be understood that the implementation examples described here are only used to illustrate and explain the present invention, and are not intended to limit the present invention.
[0035] The present invention will be further explained below in conjunction with specific embodiments.
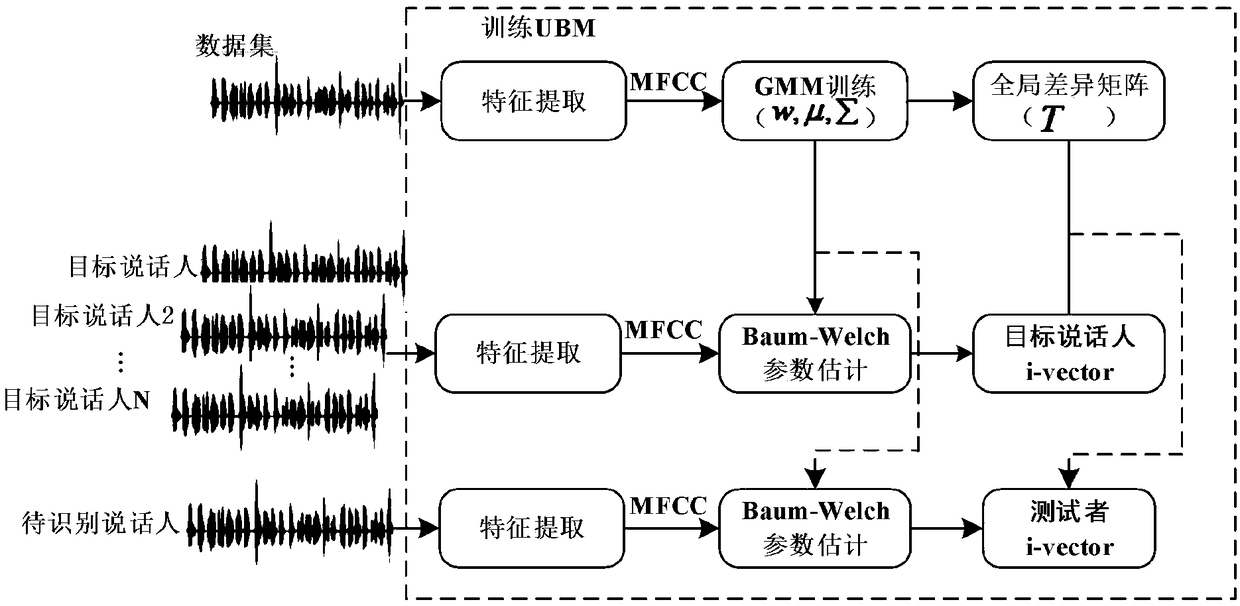
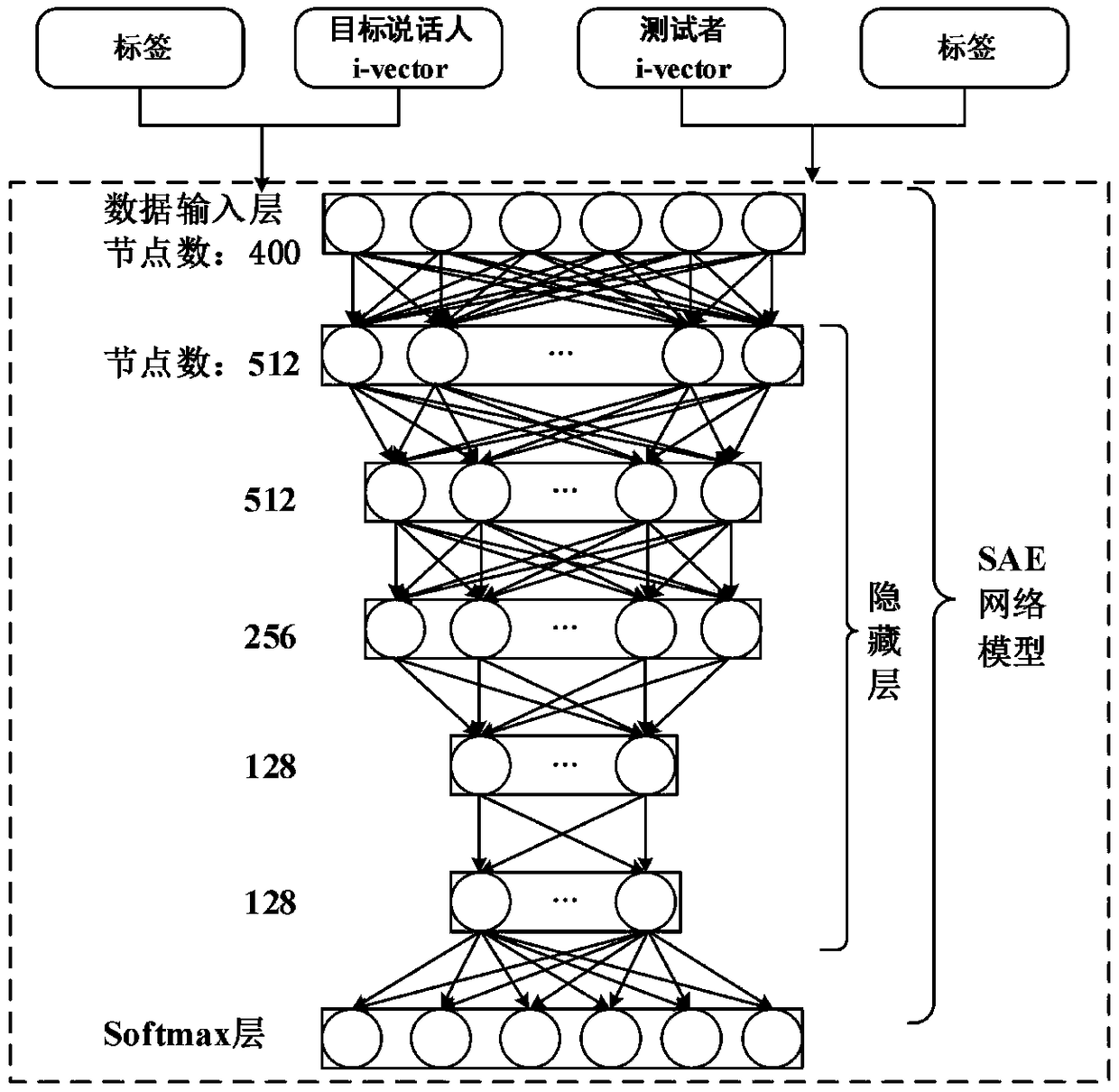
[0036] refer to Figure 1-4 , a speaker recognition method based on deep stack autoencoder network, which can be divided into three parts: 1) speaker feature extraction; 2) network design of stack autoencoder; 3) speaker recognition and decision (softmax) .
[0037] 1) Speaker feature extraction, the steps are as follows:
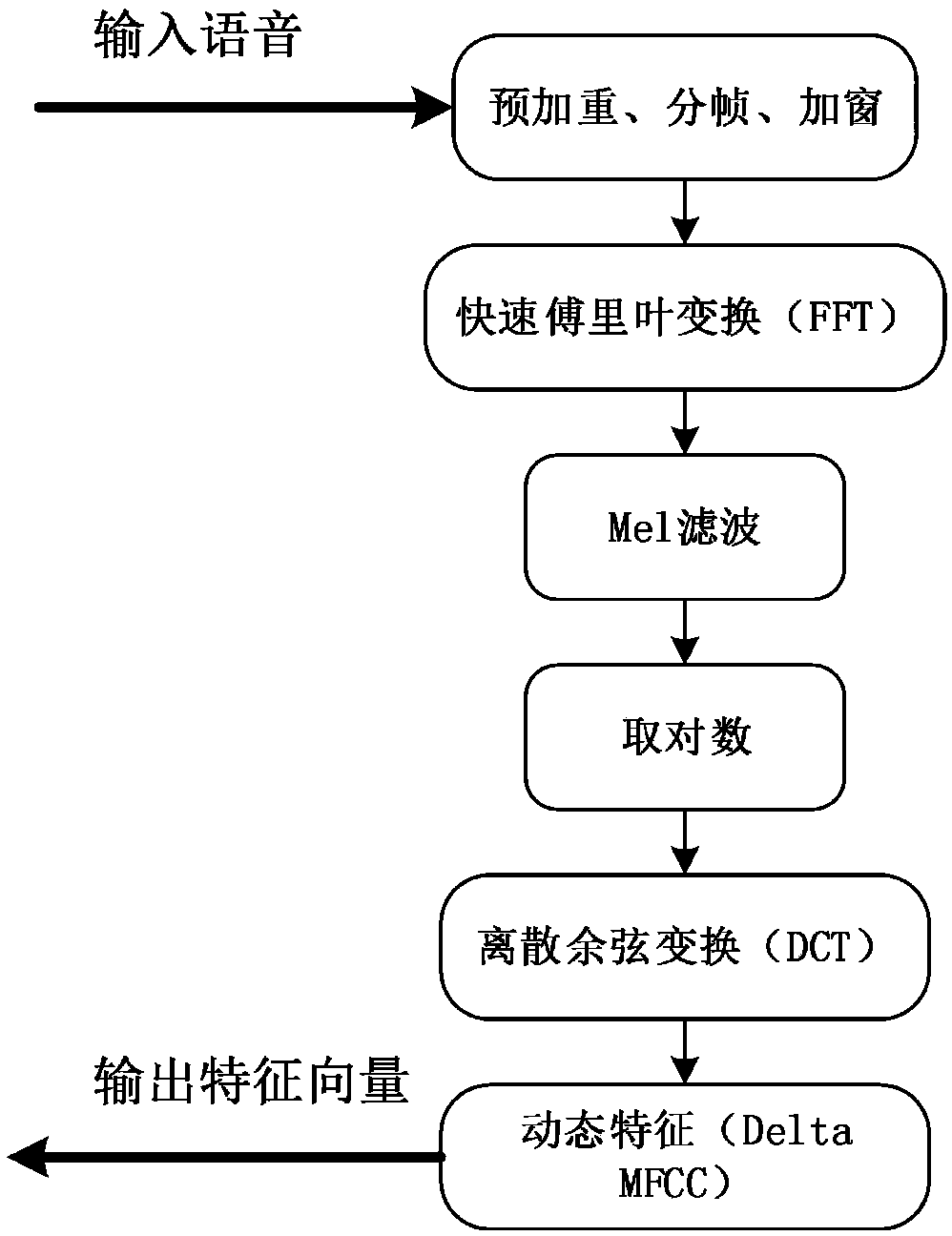
[0038] A. Collect the original voice signal and pre-emphasize, frame, window, fast Fourier transform (FFT), triangular window filter, logarithm, discrete ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More