

Dynamic mining method for distributed data streaming
A data flow and distributed technology, applied in the field of big data processing, can solve the problems of unclear technical details, high cost, and little research, so as to reduce the possibility of data being discarded, reduce data discarding, and reduce network transmission costs Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
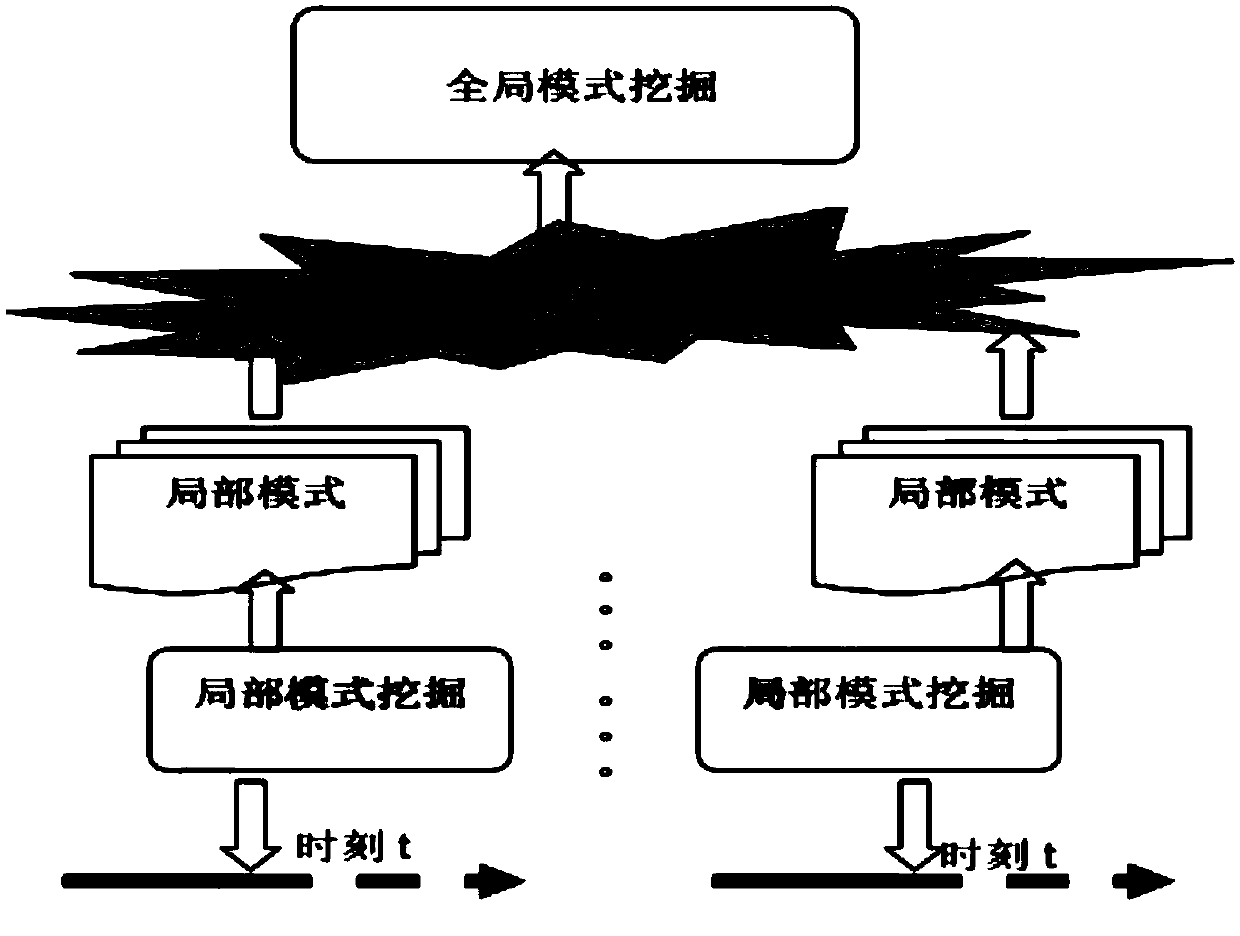
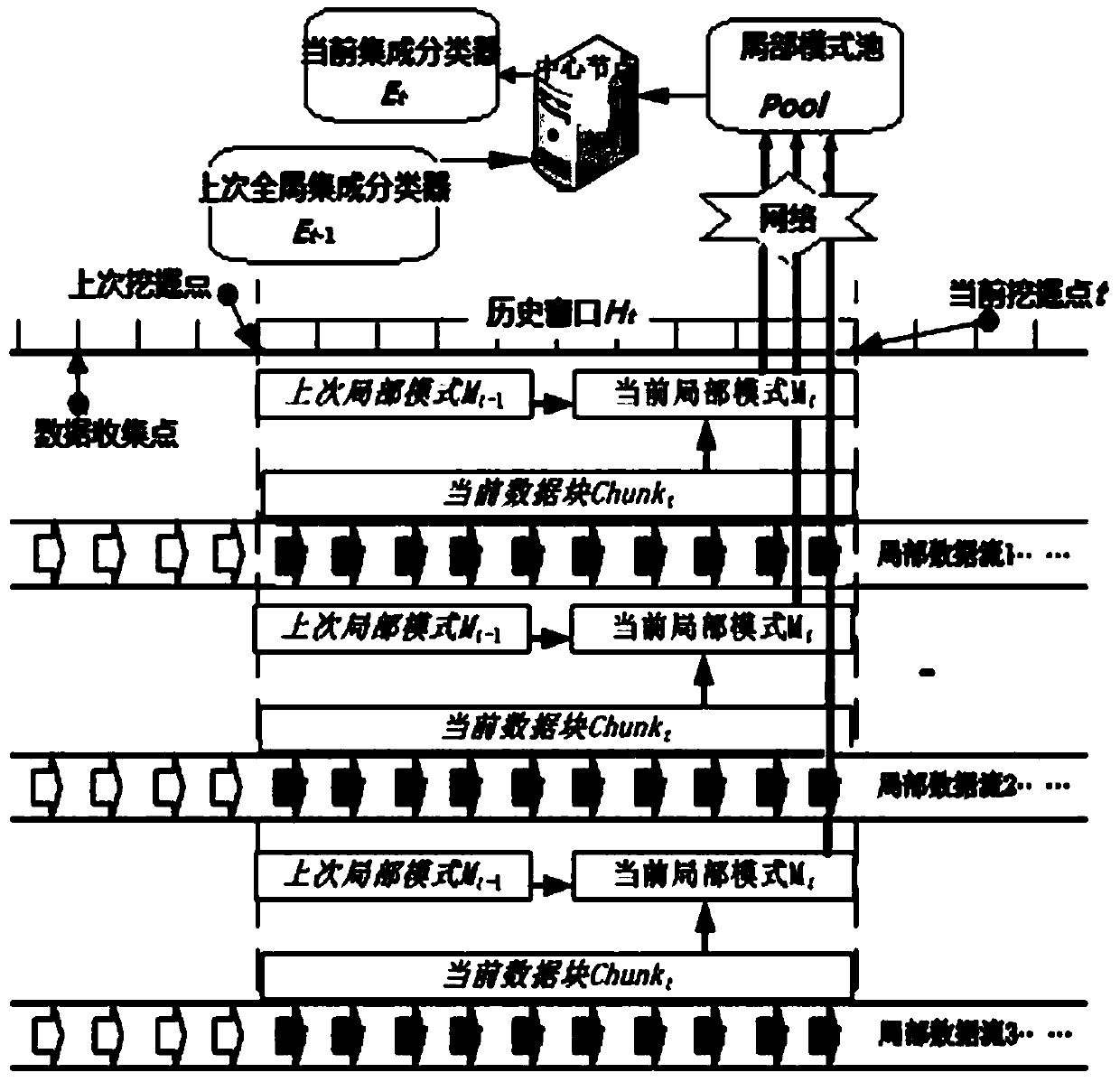
[0037] Such as figure 1 Or shown in 2, the present invention discloses a kind of dynamic mining method of distributed data flow, and it comprises the following steps:
[0038] Step 1, each local node collects the current data block at the current time t, and performs micro-cluster processing on the current data block of each local node;
[0039] Step 2, each local node performs incremental micro-cluster update of the local mode: each local node incrementally updates the current data block processed by the micro-cluster collected at time t and the local mode maintained at time t-1 to form t local patterns of time;
[0040] Step 3, local mode transmission stage: upload the local mode of each local node at time t to the central node;
[0041] Step 4, the central node reconstructs the global sample data set based on micro-clusters after receiving the local patterns of all local nodes at time t:
[0042] Step 5: The central node performs a newly learned basic learner based on th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More