

Video semantic segmentation method based on convolutional neural network
A convolutional neural network and semantic segmentation technology, applied in the field of real-time video semantic segmentation of targets in the process of autonomous driving, can solve the problem of slow target segmentation processing speed, improve real-time performance and processing speed, improve segmentation accuracy, and reduce time. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
[0038] Specific implementation mode one: combine figure 1 To describe this embodiment,
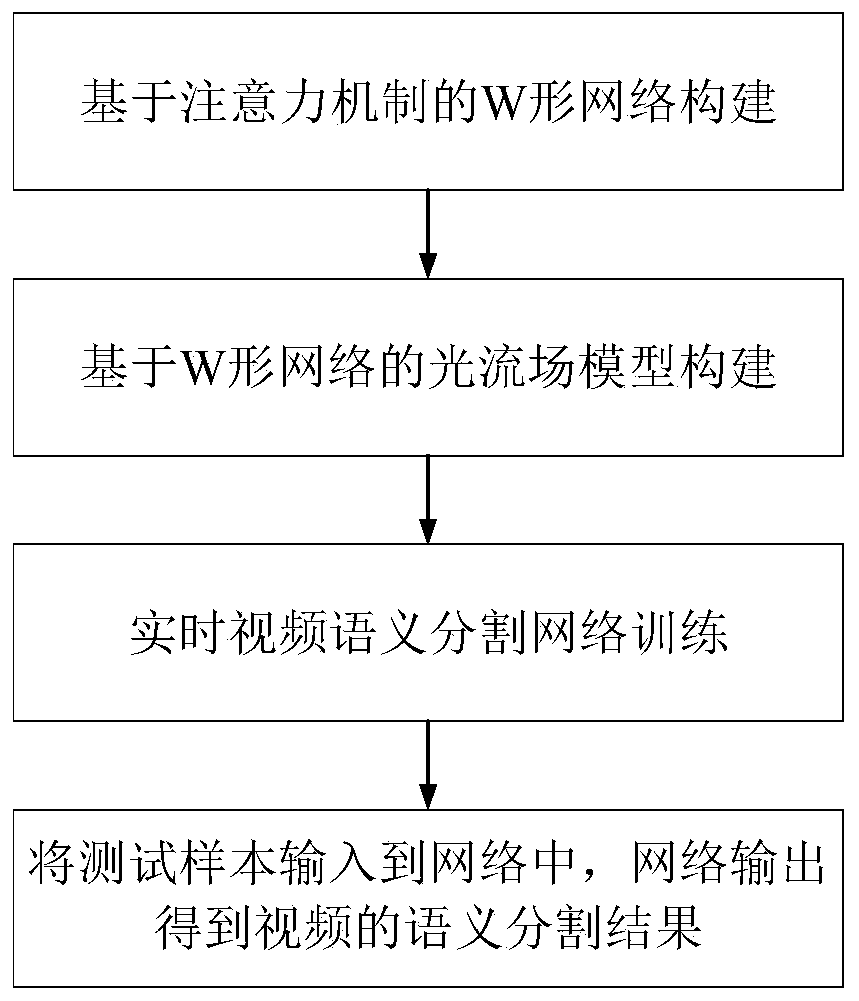
[0039] A video semantic segmentation method based on a convolutional neural network, comprising the following steps:
[0040] Step 1: Construct a W-shaped network model based on the attention mechanism. The entire model structure is composed of two branches, which can identify overall information and detailed information at the same time.
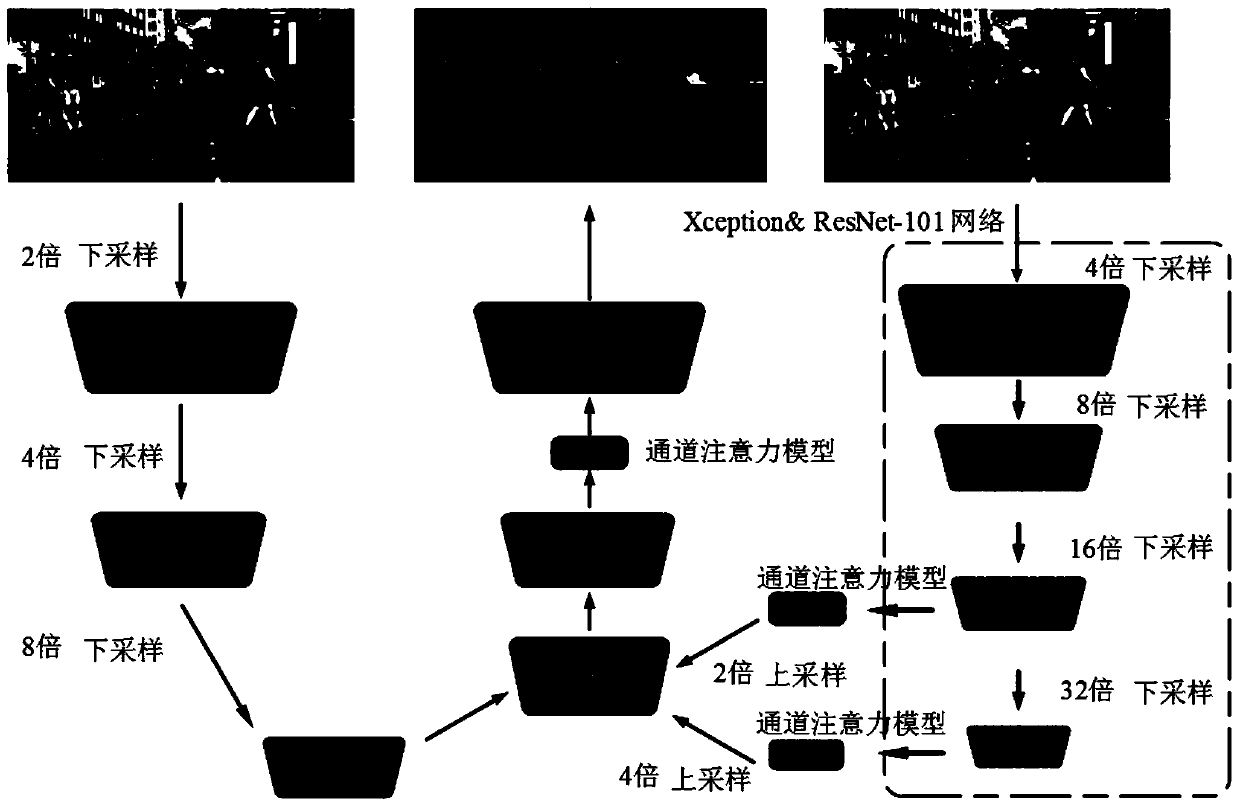
[0041] Such as image 3 As shown, the W-shaped network model includes two branches:
[0042] One branch is input from the image and undergoes three times of convolution to down-sample to obtain a feature map with one-eighth of the accuracy of the original image, preserving the details of the original image as much as possible;
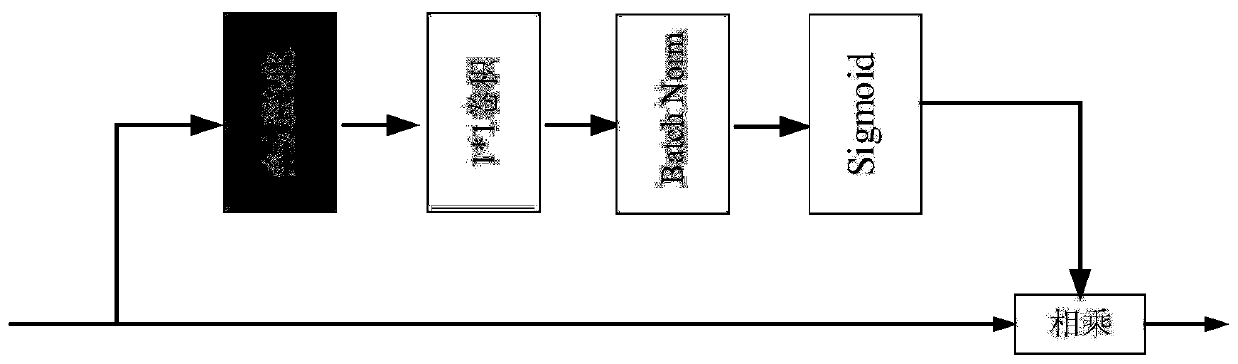
[0043] The other branch uses the Xception module or ResNet module to perform deep down-sampling, expand the receptive field, and obtain 16-fold and 32-fold down-sampled feature maps, respectively, after the two down-sampled f...
specific Embodiment approach 2
[0050] In step 2 of this embodiment, on the basis of the W-shaped network, the process of constructing an optical flow field algorithm to propagate and fuse features between frames is as follows:
[0051] Using the deep feature flow algorithm, which combines the propagation correspondence between features, only runs the computationally intensive deep convolutional network on sparse key frames, and transmits their deep feature maps to other networks through the optical flow field. frame. Compared with the entire deep convolutional network, the optical flow calculation method has less calculation and faster operation speed, so the algorithm has been significantly accelerated. Among them, the calculation of the optical flow field also uses the convolutional neural network model, so the whole framework realizes end-to-end training, thereby improving the recognition accuracy. Since the intermediate convolutional feature maps have the same spatial size as the input image, they pres...
specific Embodiment approach 3
[0056] One branch described in this embodiment is input from an image and undergoes three convolutions to perform down-sampling to obtain a feature map with one-eighth of the accuracy of the original image. The specific process is as follows:
[0057] The image is first processed by conv+bn+relu to achieve 2 times downsampling,
[0058] Then through conv+bn+relu processing to achieve 2 times downsampling, get 4 times downsampled feature map;
[0059] Then, through the above operation, 2 times downsampling is performed to obtain a feature map with one-eighth of the accuracy of the original image.
[0060] Other steps and parameters are the same as those in Embodiment 1 or 2.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More