

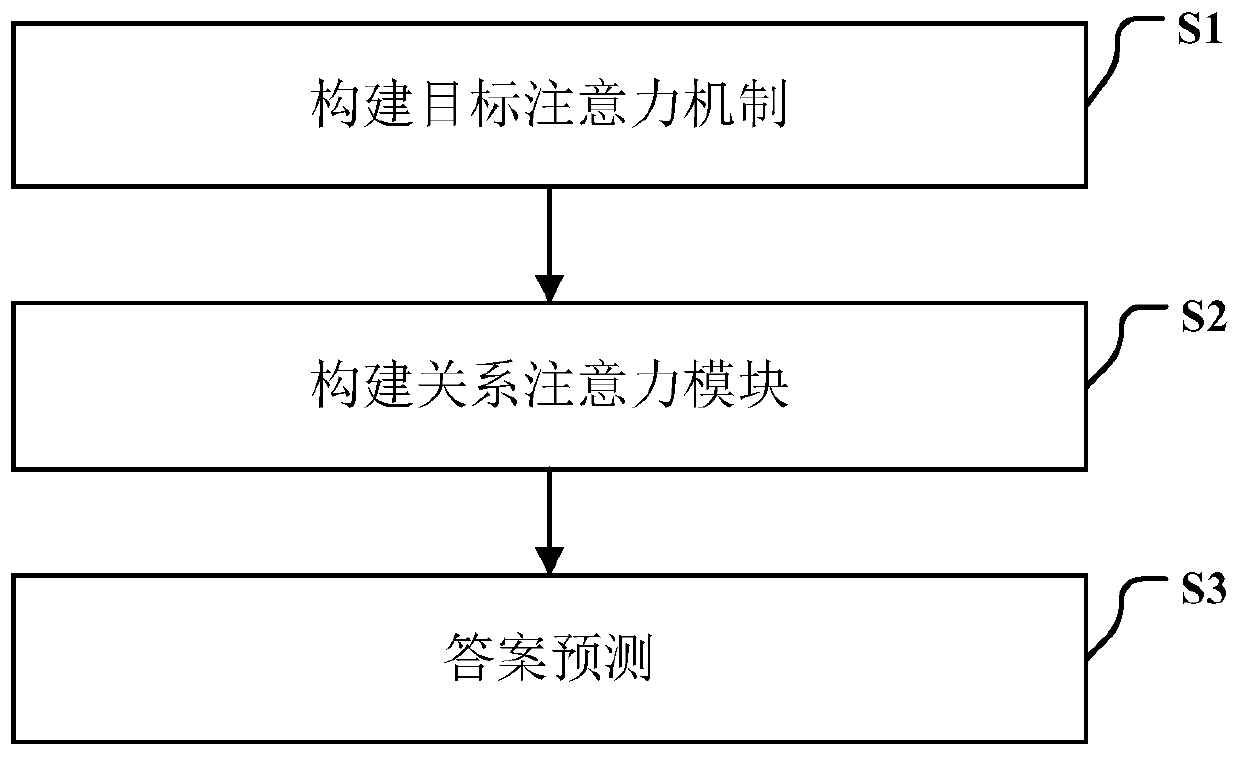
Visual question and answer method based on a combined relation attention network
A technology of combining relationships and attention, applied in the field of visual question answering, can solve problems such as the inability to integrate image features and relationship features well, insufficient visual relationships, and inaccurate answers to predicted questions.
Active Publication Date: 2019-09-10
成都澳海川科技有限公司
View PDF11 Cites 8 Cited by
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
[0006]
1. Existing visual question answering methods can only capture simple visual relationships, which are insufficient to answer complex textual questions;
[0007]
2. The existing visual question answering method uses the visual relationship features of the target to update the image features of the target. This method cannot well integrate the image features and relational features of the target in the image.
[0008]
The above deficiencies result in inaccurate answers to prediction questions
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View moreImage
Smart Image Click on the blue labels to locate them in the text.
Smart ImageViewing Examples


Examples
Experimental program
Comparison scheme
Effect test
example
[0076] In this embodiment, the effect of the present invention is tested on two large-scale benchmark data sets VQA-1.0 and VQA-2.0. From the experimental results, it can be seen that the visual question answering method based on the combined relational attention network of the present invention is better than the current one. There is a method of the highest level of technology.
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More PUM
 Login to View More
Login to View More Abstract
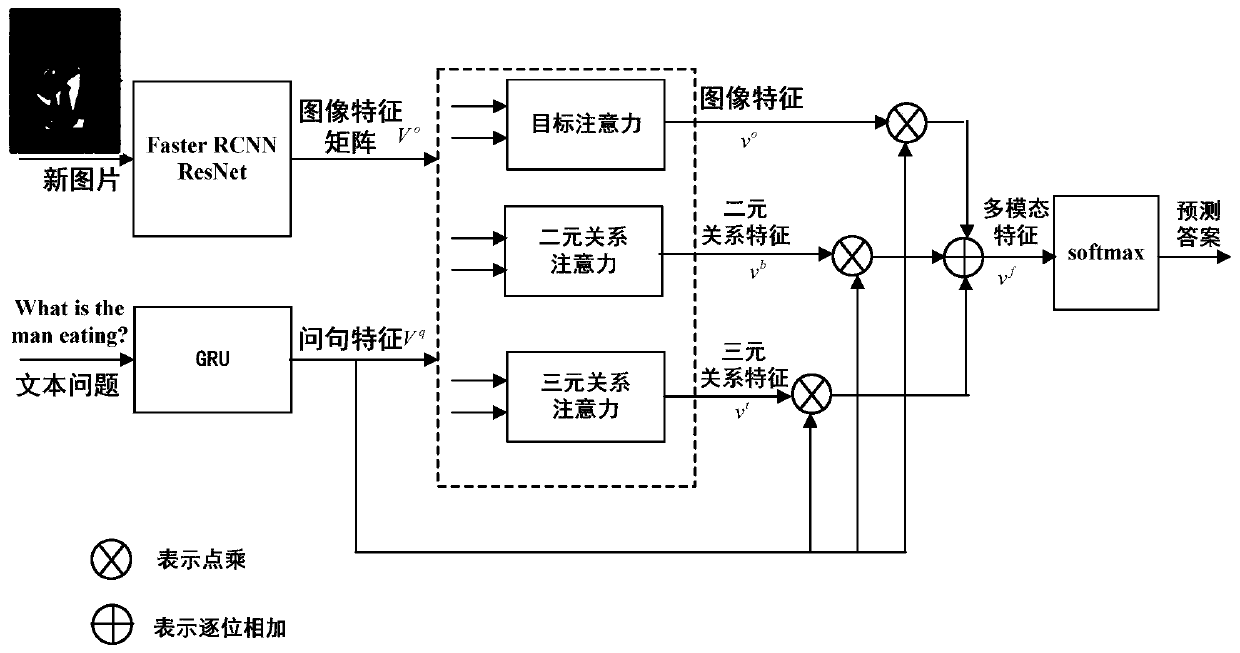
The invention discloses a visual question and answer method based on a combined relation attention network, aims at the problem that the existing visual question and answer method can only extract a simple visual relation, and innovatively constructs a self-adaptive relation attention module for fully extracting an accurate binary relation and a more complex ternary relation. The visual relationship between the relationship and the question can reveal deeper semantics, and the reasoning capability of the method when the method answers the question is enhanced. Meanwhile, the problem that an existing visual question and answer method cannot well fuse image features and position (relation) features of a target in an image is solved. According to the method, firstly, image features and position (relation) features of a target are extracted respectively, extraction of the image features of the target is independent of extraction of the relation features of the target, and then the two features are fused under guidance of a question, so that the two features are well fused together. By fully and accurately extracting the visual relationship and well fusing the image features and the relationship features, the accuracy of predicting the answers of the questions is improved.
Description
technical field [0001] The invention belongs to the technical field of visual question answering (VQA for short), and more specifically relates to a visual question answering method based on a combined relational attention network. Background technique [0002] In the existing technology, visual question answering (VQA) is mainly divided into two steps: 1) understand the content of image and text questions, extract image features and question features; 2) fuse image features and question features to obtain multimodal feature representation , and then predict the answer to the question through a softmax classifier. Among them, the attention mechanism (Attention) achieves the purpose of better understanding the image and the content of the question by focusing on the image area related to the question and the keywords in the question. [0003] In terms of feature fusion, at present, it is mostly based on bilinear network (Bilinear Network), which can well combine image featur...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More Application Information
Patent Timeline
 Login to View More
Login to View More Patent Type & AuthorityApplications(China)
IPC IPC(8): G06K9/62G06F16/332
CPCG06F16/3329G06F18/253
Inventor杨阳汪政彭亮
Owner成都澳海川科技有限公司