

Semi-automatic word segmentation corpus labeling and training device
A training device and semi-automatic technology, applied in special data processing applications, instruments, electrical and digital data processing, etc., can solve the problem of organizing various language information into machines that can be directly read, reducing labor costs and improving efficiency and accuracy, reducing the effect of complexity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
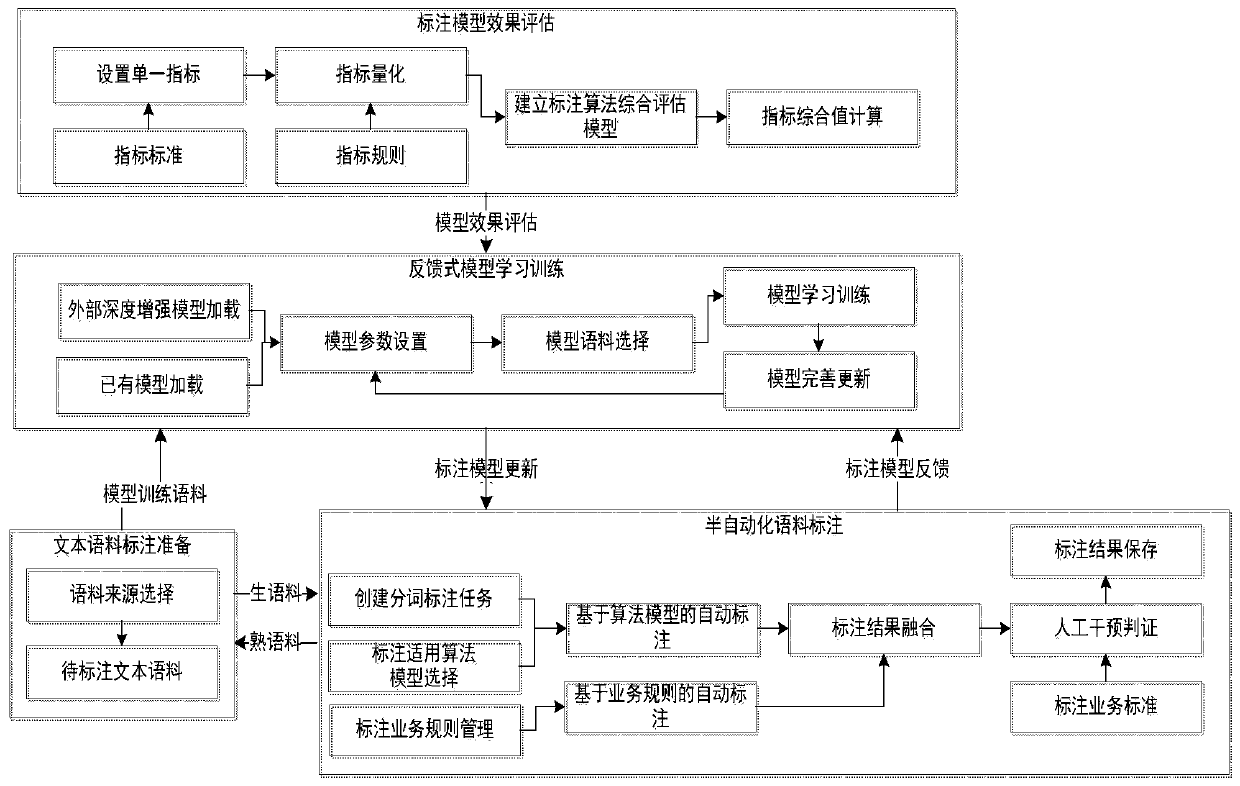
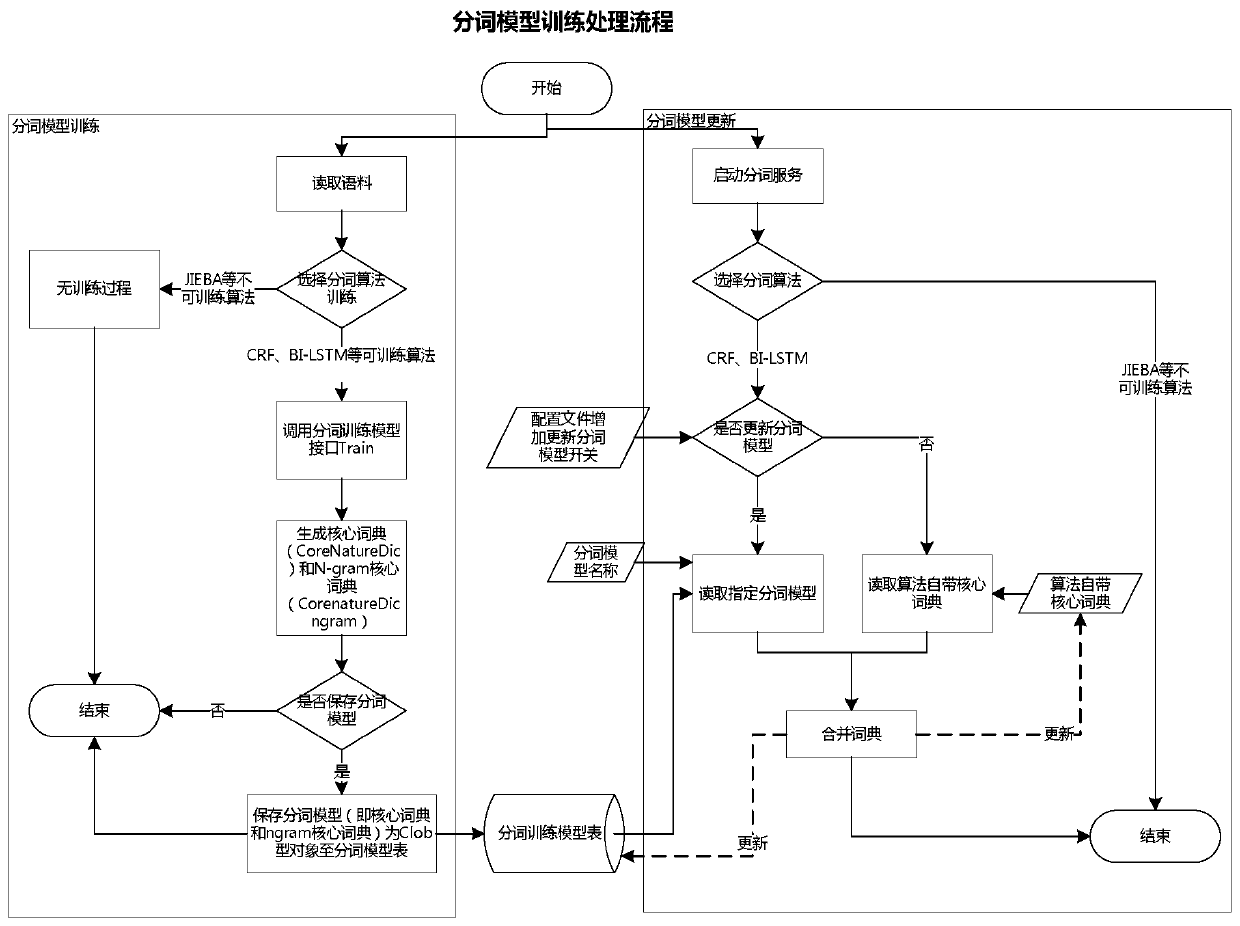
[0023] See figure. In the preferred embodiment described below, a semi-automatic word segmentation corpus labeling training device includes: a text corpus labeling preparation module, a semi-automatic corpus word segmentation labeling module, a feedback model learning training module and a word segmentation labeling model effect evaluation module, which The feature is that the text corpus labeling preparation module provides preparation for labeling tasks. By distinguishing data from different sources and selecting corpus sources, pre-labeling the corpus data to be labeled according to the source or subject is performed for a single word segmentation, and the corpus to be labeled and word segmentation are realized. Data management, and then through multiple word segmentation algorithms such as bidirectional maximum matching word segmentation based on integrated dictionaries, conditional random field CRF, JIEBA, bidirectional LSTM network, BI-LSTM, etc., submit the raw corpus wo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More