

Text similarity calculation method based on x2-C
A technology of text similarity and calculation method, which is applied in the field of text similarity calculation based on χ2-C, and can solve the problems of complex structure of CNN model, many parameters, and long running time.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


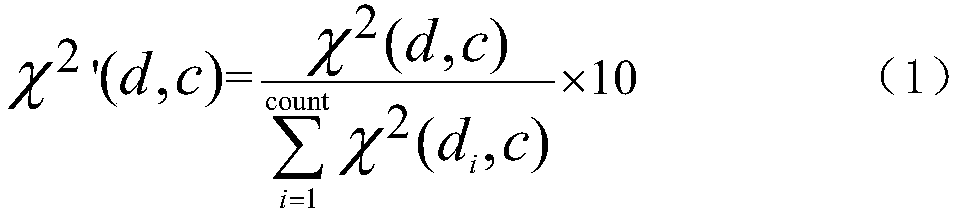
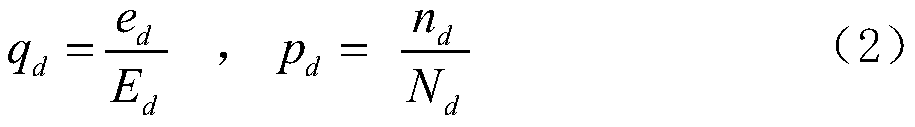
Examples
Embodiment Construction
[0049] The specific embodiment of the present invention will be further described below in conjunction with accompanying drawing and specific embodiment:
[0050] Based on χ 2 The text similarity calculation method of -C comprises the following steps:
[0051] Step 1: Preprocess the test data and the content of the corpus;
[0052] Step 2: Use the convolutional neural network CNN to classify the test data set;
[0053] Step 3: Use the TF-IDF algorithm to calculate the initial weight of the feature words in the detection sample;
[0054] The TF-IDF algorithm uses express,
[0055]
[0056] Among them, W dt Indicates the weight value of feature word d in document t, TF dt Indicates the word frequency of feature word d in document t, m d Indicates the number of occurrences of feature word d in document t, S represents the total number of feature words in document t, IDF dt Indicates the inverse text frequency index of the feature word d, n d is the number of texts co...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More