

Large-scale data clustering method and device and computer readable storage medium
A technology of large-scale data and clustering methods, applied in computer parts, computing, character and pattern recognition, etc., can solve problems such as reduced execution efficiency, inability to provide good solutions, and time-consuming
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0058] It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
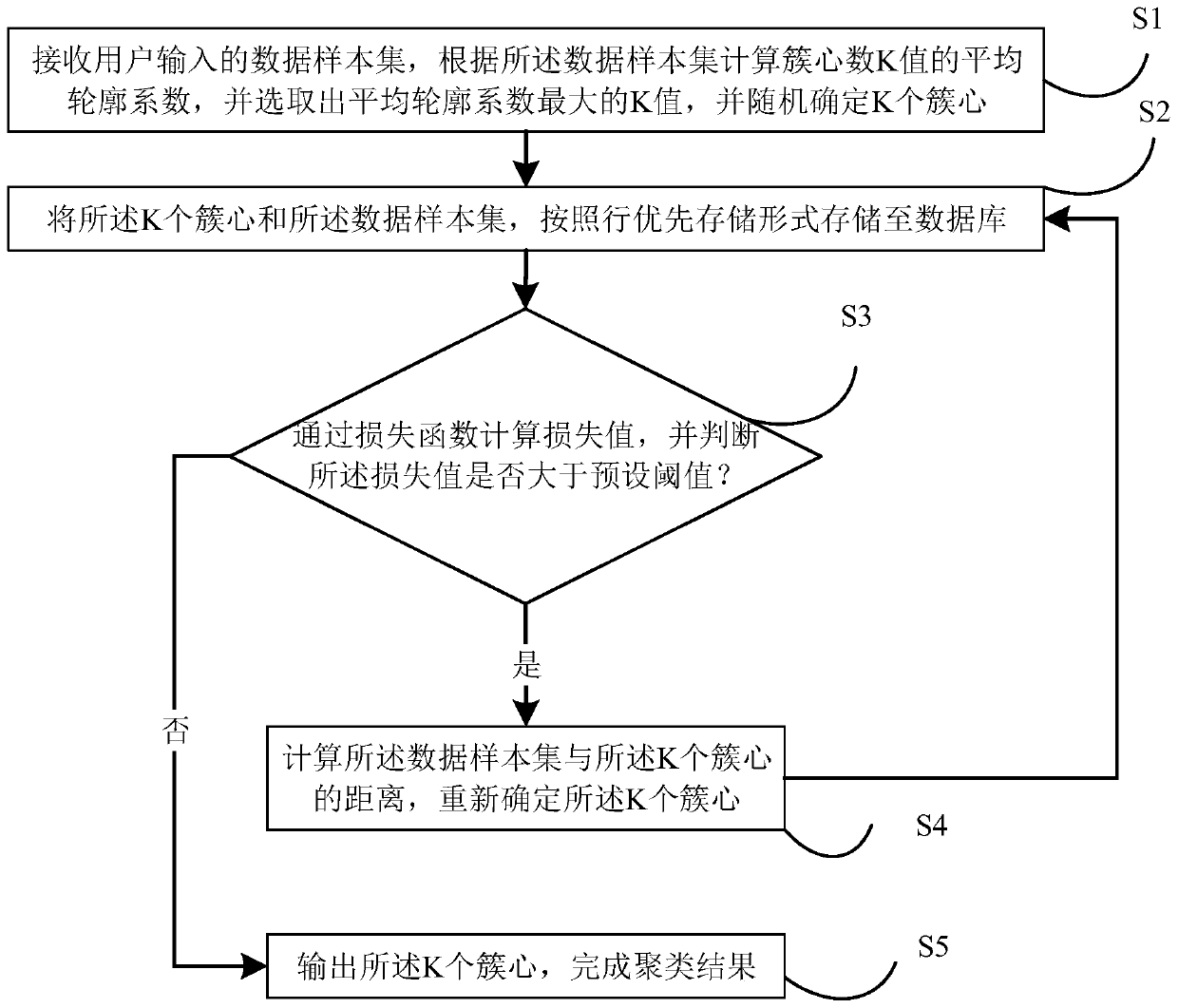
[0059] The invention provides a large-scale data clustering method. refer to figure 1 As shown, it is a schematic flowchart of a large-scale data clustering method provided by an embodiment of the present invention. The method may be performed by a device, and the device may be implemented by software and / or hardware.
[0060] In this embodiment, the large-scale data clustering method includes:
[0061] S1, the K value calculation layer receives the data sample set input by the user, calculates the average silhouette coefficient according to the data sample set, and selects the K value with the largest average silhouette coefficient, randomly determines K cluster centers, and divides the data sample set, The K value and the K cluster centers are input to the cluster center calculation layer.
[0062] In a preferre...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More