

Distributed web crawler performance optimization system for mass data acquisition
A distributed network and mass data technology, applied in the field of distributed web crawler performance optimization system, can solve the problems of low deduplication efficiency, server memory resources, inability to effectively eradicate, excessive consumption of junk links, etc., to improve deduplication efficiency, The effect of breaking through performance bottlenecks and improving crawling performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0049] In order to make the purpose, content, and advantages of the present invention clearer, the specific implementation manners of the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments.
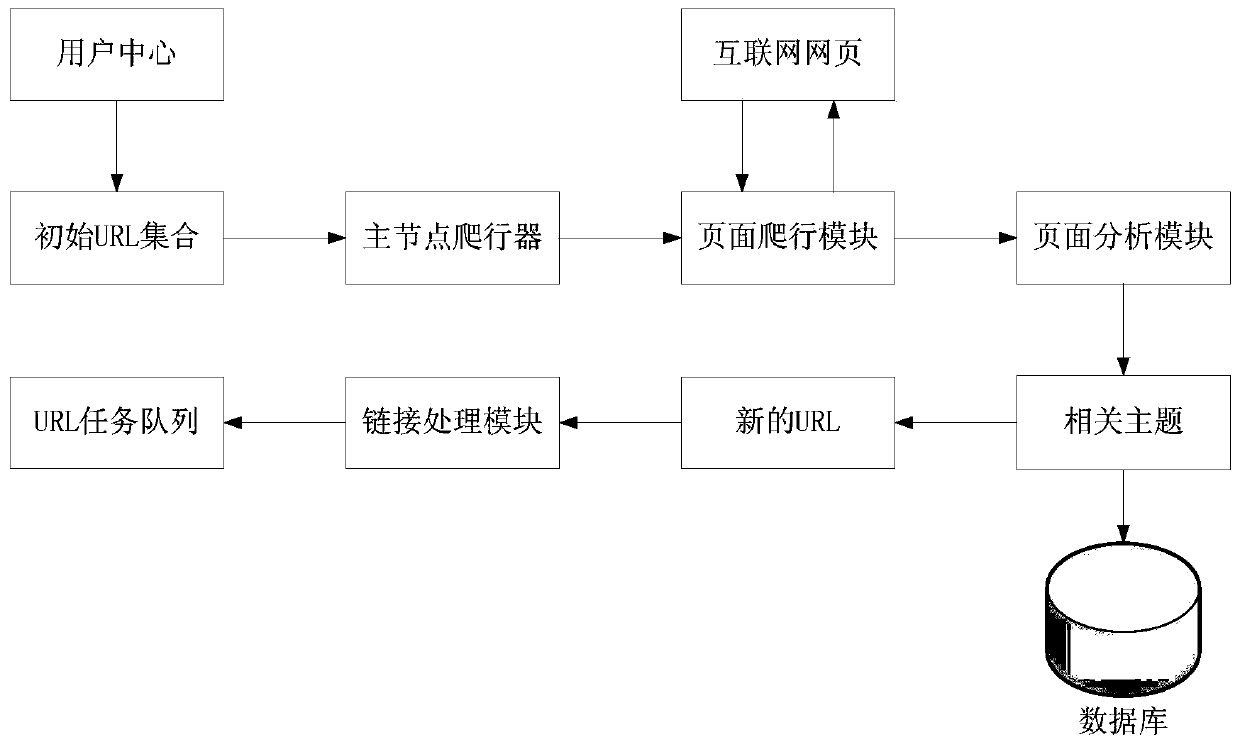
[0050] In order to solve the above technical problems, the present invention provides a distributed network crawler performance optimization system for mass data collection, the distributed network crawler performance optimization system includes: an initialization module, a crawling module; wherein,
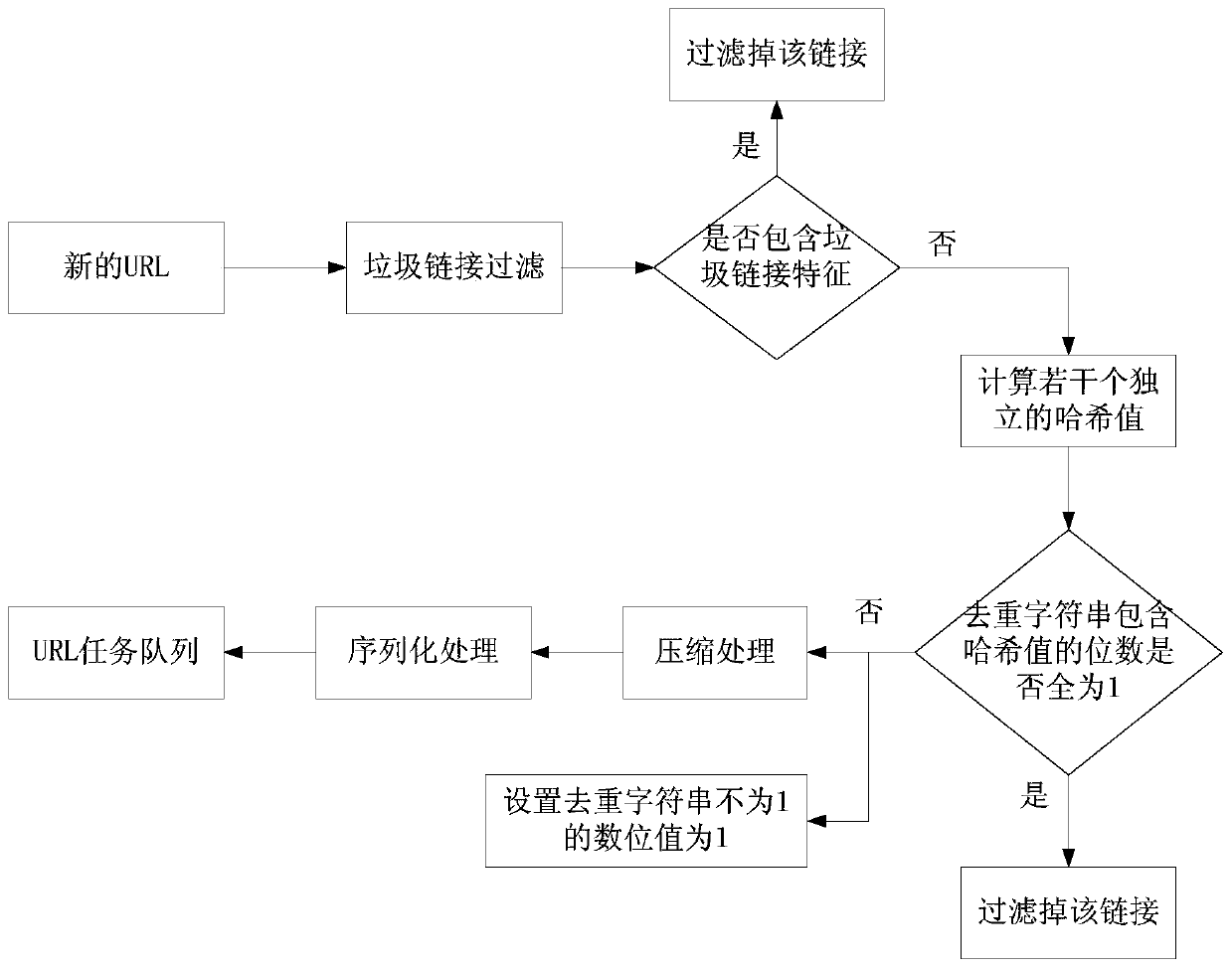
[0051] The initialization module is used to create a deduplication character string and a spam link characteristic string;
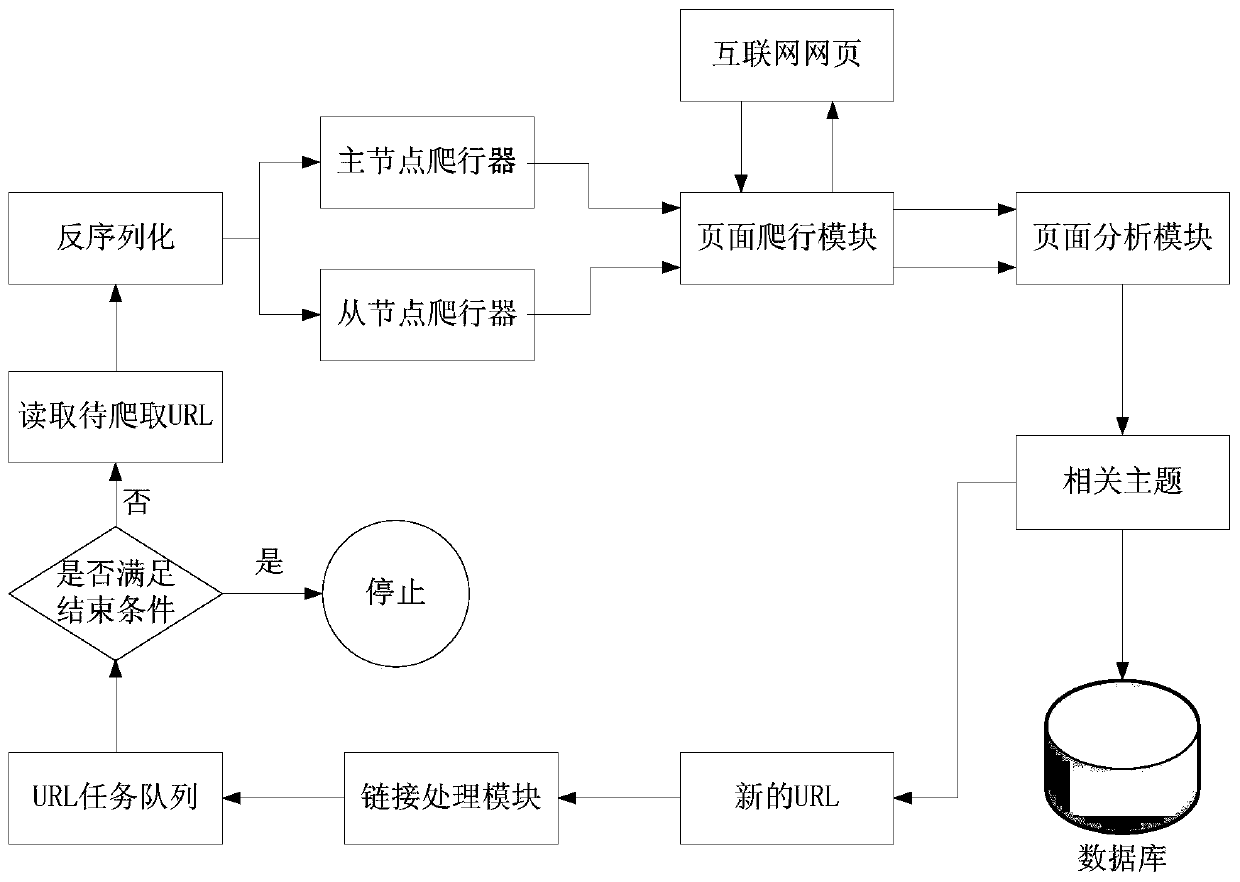
[0052] The crawling module is used to crawl the initial URL address to generate a URL task queue after the master node crawler reads the initial URL address;
[0053] The crawling module is also used to crawl web pages according to the URL task queue to complete the crawling work.
[0054] Wherein...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More