Deep reinforcement learning-based recommendation method and system with negative feedback
A technology of reinforcement learning and recommendation methods, applied in neural learning methods, data processing applications, biological neural network models, etc., can solve the problems of slow learning rate and low accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0047] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention. In addition, the technical features involved in the various embodiments of the present invention described below can be combined with each other as long as they do not constitute a conflict with each other.
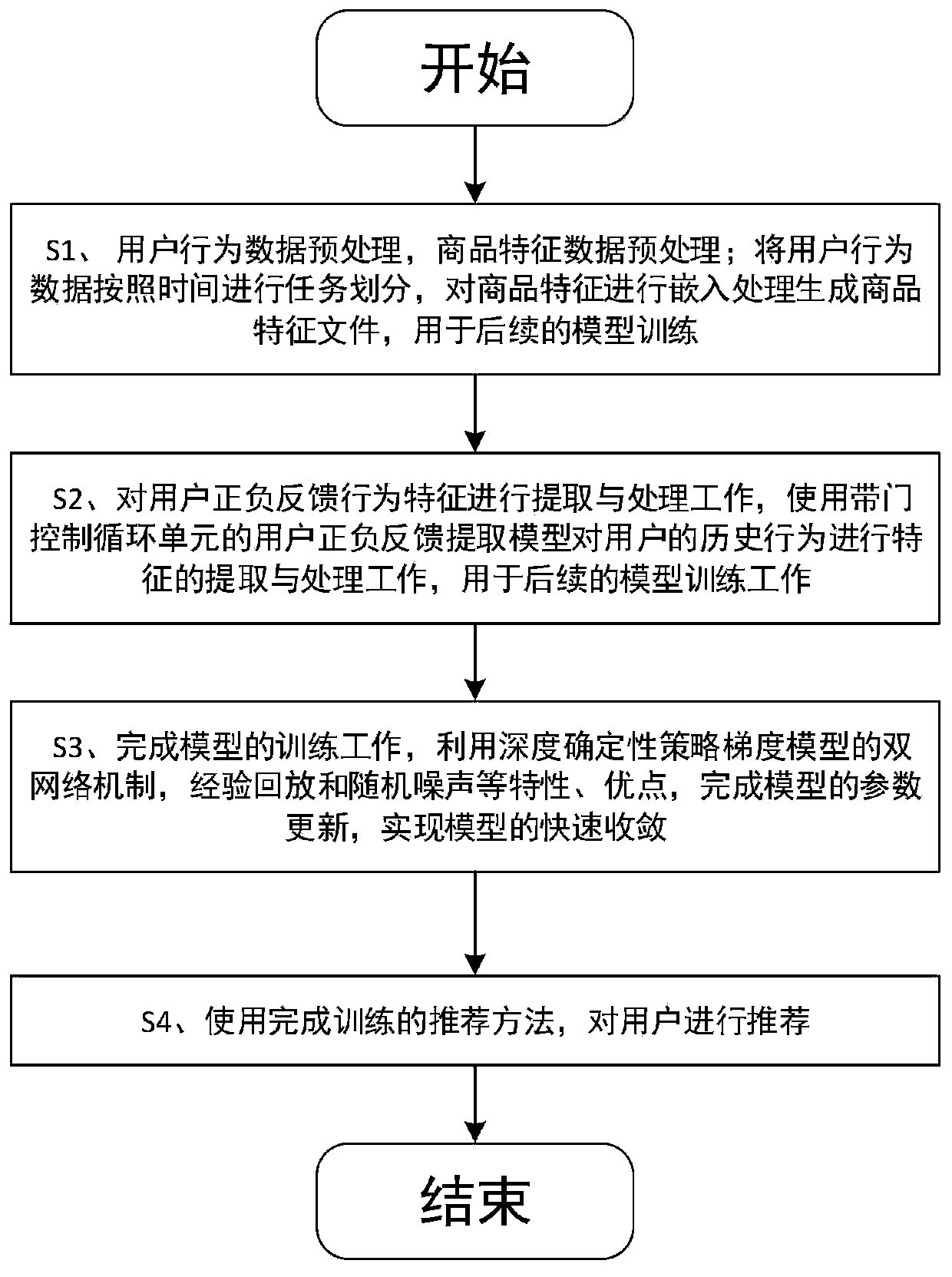
[0048] The present invention provides a method such as figure 1 shown, including:
[0049] S1. The data acquisition based on the deep reinforcement learning recommendation method with negative feedback mainly depends on the behavior information of the users in the e-commerce website when they visit the website and the feature information of the product. Extract and divide user behavior data; ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com