

A data analysis method based on user information
A user information and data analysis technology, applied in network data management, wireless communication, instruments, etc., can solve the problems of inaccurate data analysis, loss of important variables, low model contribution, etc., and achieve the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
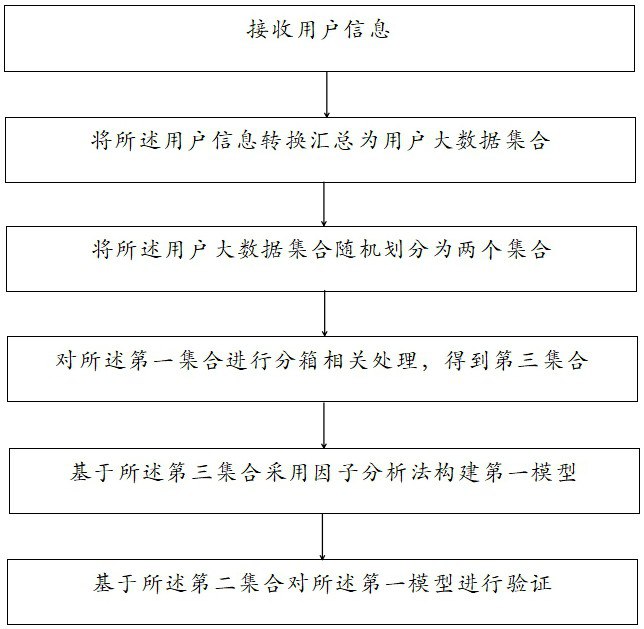
[0058] like figure 1 As shown, the present invention discloses a data analysis method based on user information, including the following steps:
[0059] Receive user information;
[0060] Summarket the user information conversion as a user's large data collection;
[0061] The set of large data sets is randomly divided into two sets, the two sets including a first set and a second set, the first set stored in the first database, the second set stored in the second database middle;
[0062] The first set of the first database is subjected to a split box correlation process, and the third set is stored in a third database;
[0063] Extract the third set in the third database, and construct a first model based on the third episode.
[0064] Extract the second set in the second database, and verify the first model based on the second set;
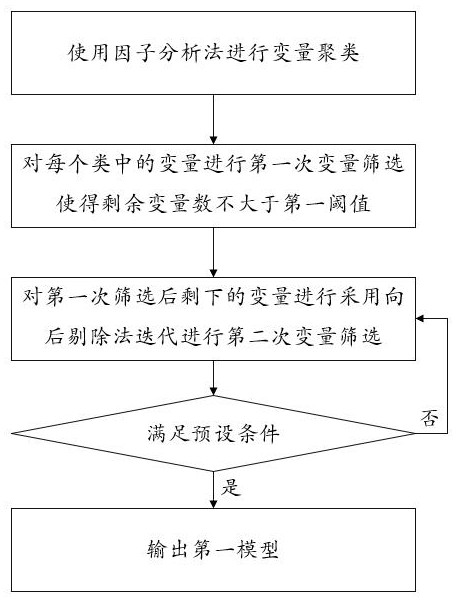
[0065] See figure 2 As shown, in which the first model is constructed based on the third epitupere, the first model is constructed, including:
[...
Embodiment 2
[0070] Based on the first example, this embodiment also includes the following:
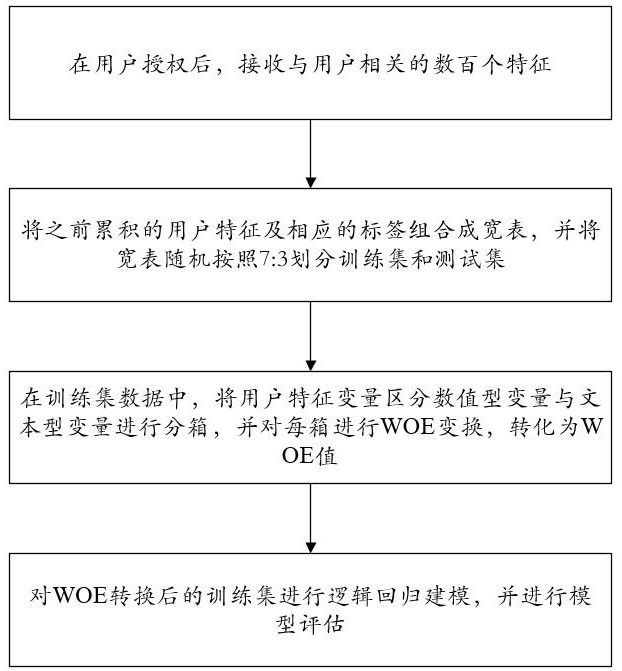
[0071] Collect users' personal information through computers or networks, and establish an evaluation model based on these collected personal information to quantify whether the user is the potential user of the value-added business, there is a risk.
[0072] The logical regression model is usually used for metrics. Logic regression is a two-class model of supervision, which converts the collected from a series of feature information (such as degree level, etc.), after the woe (Weightof evidence, evidence weights) (transform formula 1) After linearity, the value is linearly added, and the value of the sum of the SIGMOID is used to obtain a value between 0 and 1 (SIGMOID transformation is such a mapping f (x) = 1 / (1 + exp (-x) )), And this value can be used to characterize the probability of predict whether the user is trusted, and accordingly, it is determined whether or not the corresponding opera...
Embodiment 3
[0085] Based on the second embodiment, this embodiment also includes the following:
[0086] The variable of the logical regression model is generally judged by two indicators in the final regression link: p value (p-value, false value) and VIF (Variance Inflation Factor, Coefficient Diblation Coefficient) value. Where the p value reflects the significance of a single variable, the lower the P value means that the slightness of the variable is, if the P value is> 0.05, it is considered that the variable is not significant, and the VIF value reflects the variables from the model. The degree of co-linearity, the higher the VIF value, the larger the total linearity, generally if the VIF value> 4, it is considered that there is a common linearity in the model, and the variable needs to be adjusted.
[0087] Among them, the VIF represents the total linear coefficient of the model, its formula is
[0088] VIF = 1 / (1-r 2 ), Where R is the index correlation coefficient of the independen...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More