

Decoding method and device supporting domain customized language model
A language model and decoding method technology, applied in the computer field, can solve the problems of weakened speech recognition decoding effect, poor robustness, low support effect, etc., to achieve the effect of improving the effect and scalability, improving the experience of use, and improving the scope of application
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
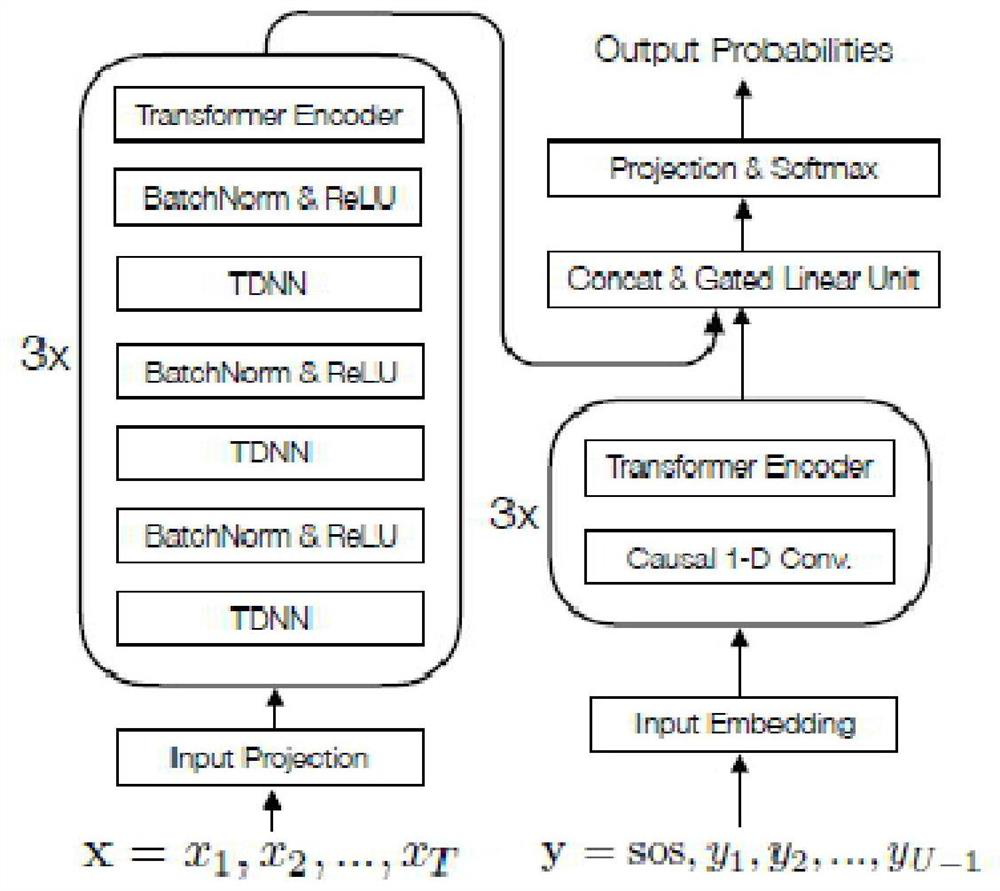
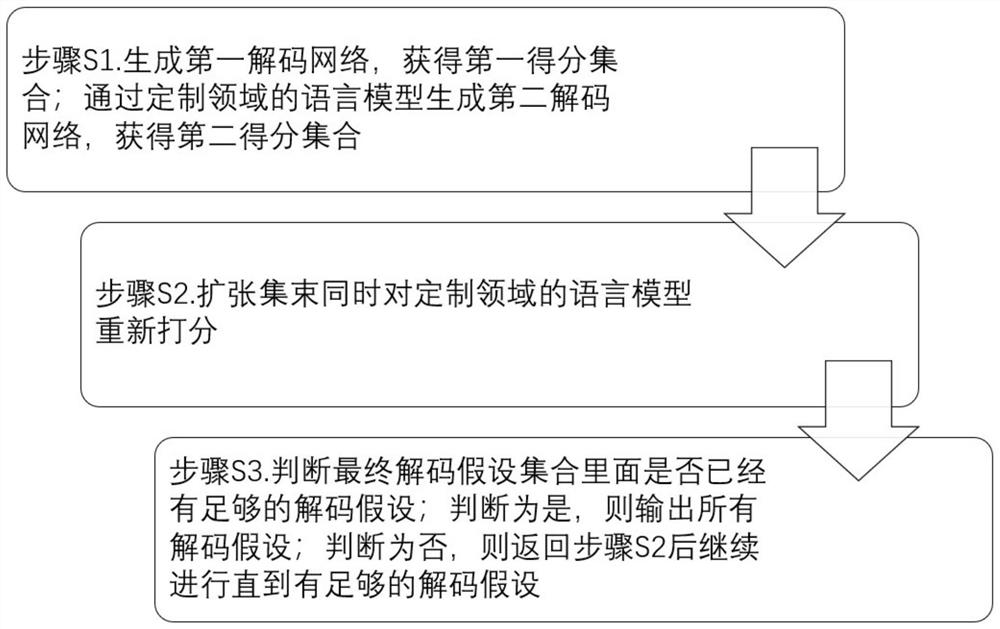
[0046] In Embodiment 1 of the present invention, an example of the end-to-end speech recognition encoder encoder and decoder decoder is as follows figure 1 As shown, the RNNT architecture based on convolution and Transformer is used. In this embodiment, the decoding method that supports domain-customized language models is based on beam search decoding, such as figure 2 As shown, it includes: Step S1. Generate the first decoding network as the first-pass decoding search network to obtain the first score set; generate the second decoding network through the language model of the customized domain, and obtain the second score as the language model score query network Set; Step S2. Update the bundle and re-score the language model in the customized domain, including iteratively performing the following operations: take the sub-matrix of the encoder expansion matrix corresponding to the current speech frame and the decoder output matrix, and input the spliced matrix into The o...
Embodiment 2
[0049] The difference between the second embodiment and the first embodiment is that before the step S2, the speech signal is initialized to obtain the encoder expansion matrix and the decoder output matrix. Such as Figure 4 As shown, in the present embodiment, at first, to the speech signal of input device input, extract the feature of this speech sequence by aforementioned extraction module, the frame number of speech sequence is num_frames, the dimension of each speech frame is dim_feat, with It gets the phonetic feature matrix for the elements. Input this speech matrix into the encoder of the end-to-end speech recognition system, obtain a transformed matrix [num_frames, enc_dim], and expand it into an encoder expansion matrix of [B, num_frames, enc_dim]. Initialize the decoded set of B words, where B represents the size of the entire beam. each character is , representing the sentence initial symbol, and get each The size of is represented by a vector, input to the de...
Embodiment 3
[0064] Embodiment 3 is based on Embodiment 2, in the process of cluster expansion, such as Figure 5 As shown, first judge whether the corresponding idx_i is a null character, and expand the bundle according to the judgment result. If idx_i corresponds to a null character, then add t_idx_i = t_idx_i+1, that is, the corresponding speech frame to the next position, and directly use the Cartesian product pair set corresponding to the current cluster as the updated Cartesian product pair set, to The second score of the current bundle is directly used as the updated second score; and then the second process is directly carried out. If the corresponding idx_i is not a null character, the first process is performed first.
[0065] The following describes the first process in detail, including the first step: find all Cartesian product pairs {LState_1, LState_2, ..., LState_m} from the Cartesian_{b_i} corresponding state of the current beam b_i and A collection of corresponding...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More