Music and human voice separation method based on U-shaped network and audio fingerprints
A technology of audio fingerprinting and separation method, applied in speech analysis, instruments, etc., can solve the problem that the model does not obtain speech and so on
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

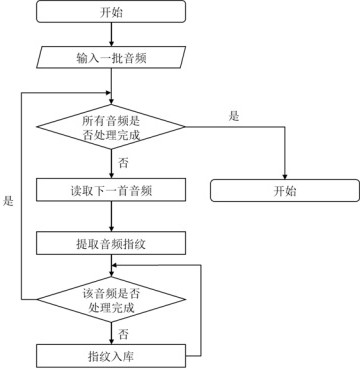
Examples
Embodiment Construction
[0044] In order to further describe the technical solution of the present invention in detail, this embodiment is implemented on the premise of the technical solution of the present invention, and provides detailed implementation methods and specific steps.
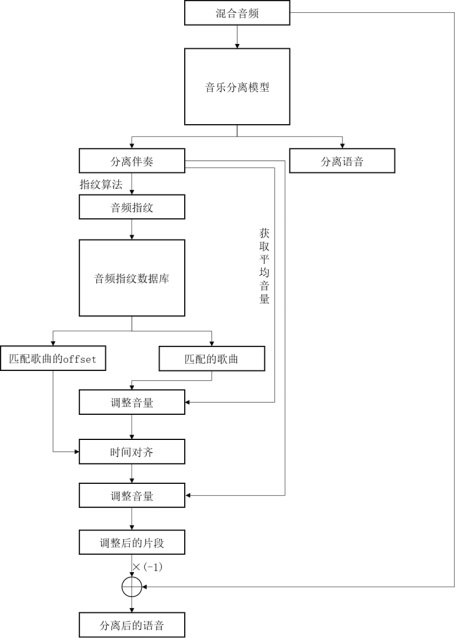
[0045] A method for separating music and human voice based on U-shaped network and audio fingerprint provided by the present invention, the specific process is as follows figure 1 Shown:
[0046] Step 1: Input the mixed audio into the trained music-vocal separation model to obtain separated accompaniment audio;
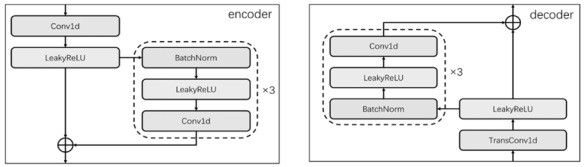
[0047] The music vocal separation model is based on a U-shaped network architecture, such as figure 2 As shown, the U-shaped network architecture includes an Encoder Encoder, a Decoder Decoder, and an intermediate layer that plays a connecting role, wherein the number of Encoder and Decoder is 6, and the specific design of Encoder and Decoder is more flexible in the embodiment. Between Encoder and Decoder In the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com