

Multi-modal video Chinese subtitle recognition method based on dense connection convolutional network
A recognition method and multi-modal technology, applied in character and pattern recognition, biological neural network models, neural learning methods, etc., can solve the problem of loss of sequence in feature extraction, inability to align audio and images, and ineffective fusion of multi-modal data And other issues
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0034]The technical solutions of the present invention will be clearly and completely described below in conjunction with the embodiments. Obviously, the described embodiments are only some of the embodiments of the present invention, rather than all of them. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without creative efforts fall within the protection scope of the present invention.
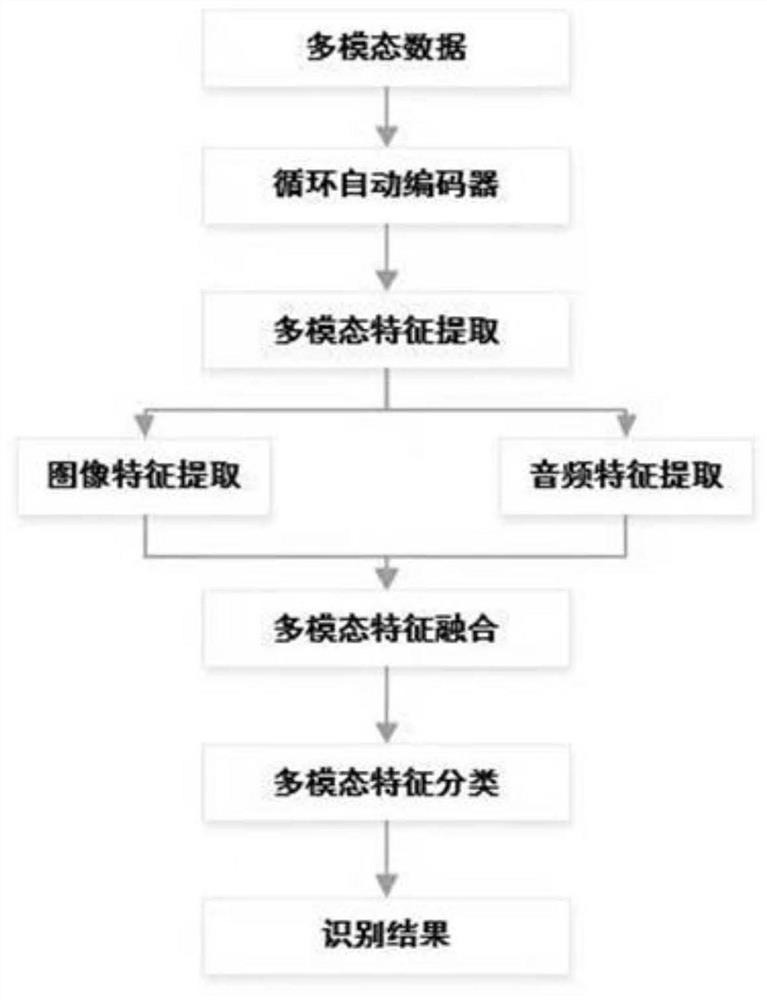
[0035] The overall implementation process of a text recognition method for multimodal video Chinese subtitles provided by the present invention is as follows: figure 1 As shown, the specific instructions are as follows:
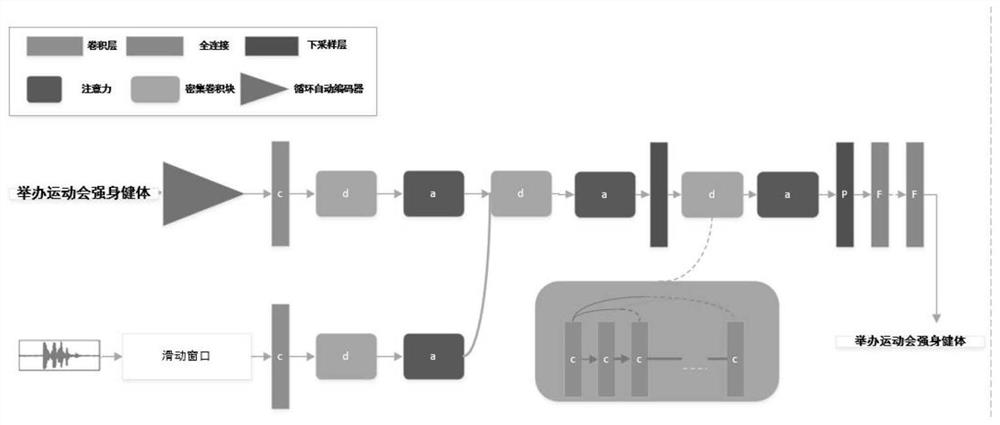
[0036] exist figure 1 In the model, the model is divided into three parts: feature compression extraction part, modal data fusion part, and multimodal feature classification part. The feature compression part is divided into the image feature compression part and the audio feature extraction part. ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More