

Video question answering method based on self-driven twinborn sampling and reasoning
A self-driven, twinning technology, applied in inference methods, video data retrieval, video data indexing, etc., can solve problems such as failure to make good use of context information, and achieve the effect of enhanced learning.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
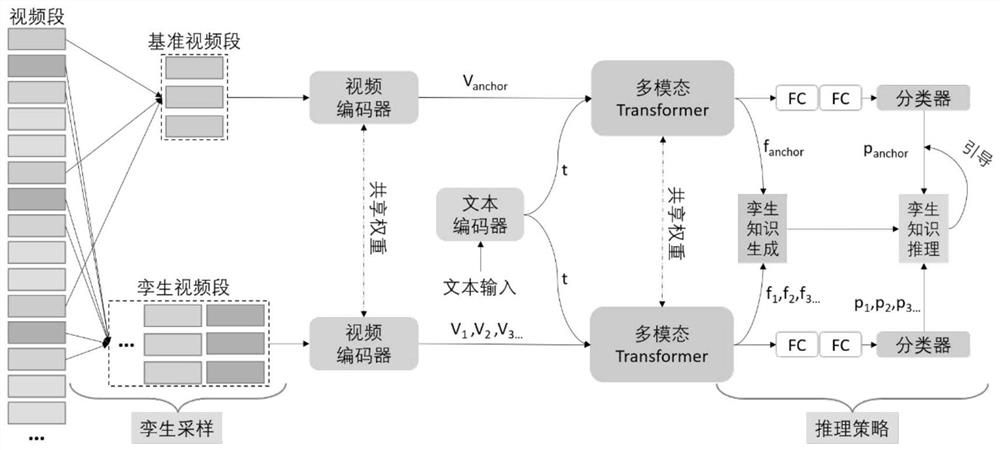
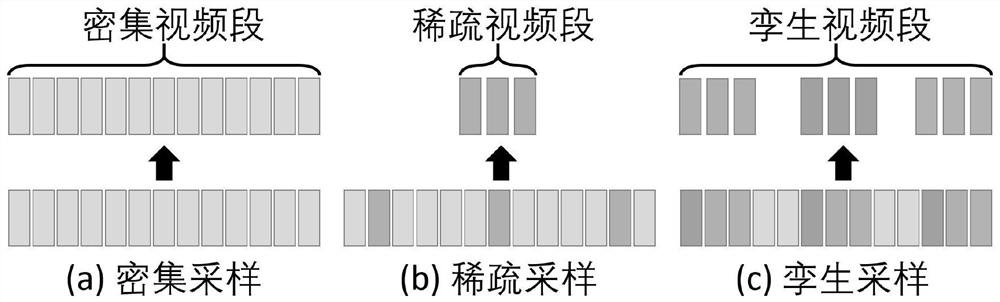
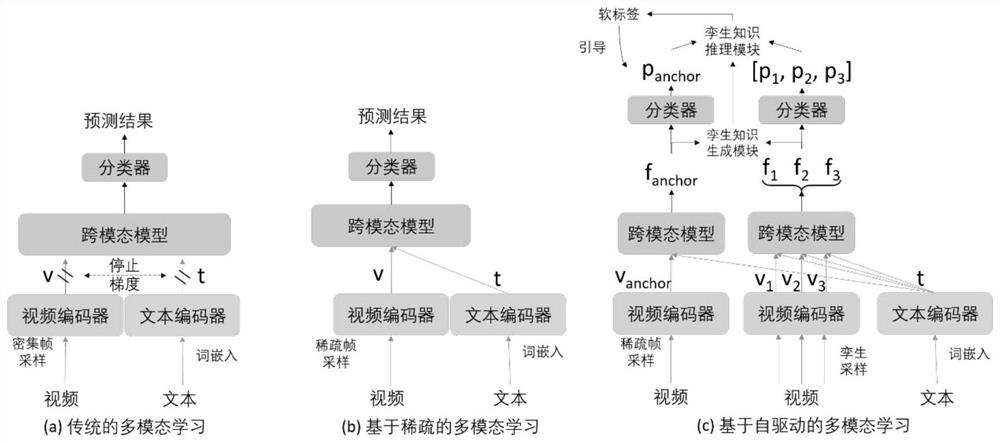
[0062] figure 1 The overall framework of the invention is shown. For a video F, the present invention constructs a reference video segment c by sampling anchor and the corresponding twin video segments where N represents the number of all video segments. The length of each video segment c is B frames, and B feature maps are obtained through the video encoder. The encoded features of the reference segment and the twin segment are respectively denoted as v anchor as well as
[0063] The text representation encoded by the text encoder and the video segment representation of the video encoder are stitched together as input, and the multimodal Transformer is used to generate video segment-text features. Benchmark video segment-text features denoted as f anchor , and the corresponding twin video segment-text features are denoted as
[0064] Similarly, the soft label predictions inferred using these features are denoted as p {anchor} with where p is a vector of dimensi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More