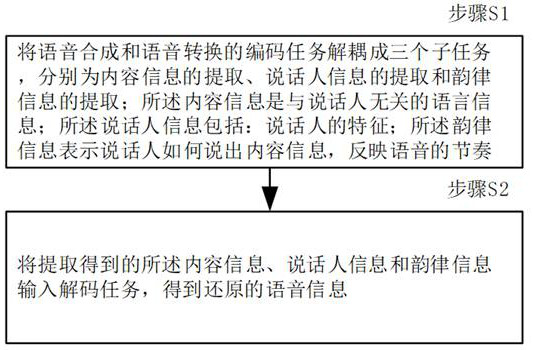
A unified training method and system for speech synthesis and speech conversion
A speech conversion and speech synthesis technology, which is applied in speech synthesis, speech analysis, instruments, etc., can solve the problem that it is impossible to learn the representation of speech content, and achieve the effect of improving performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment example
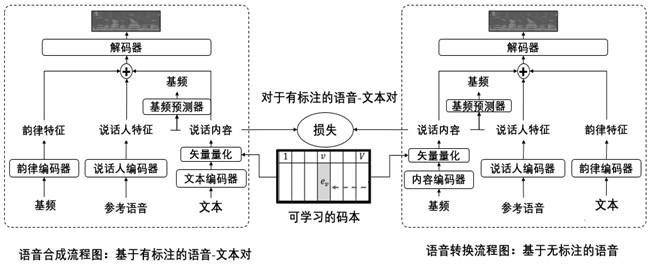
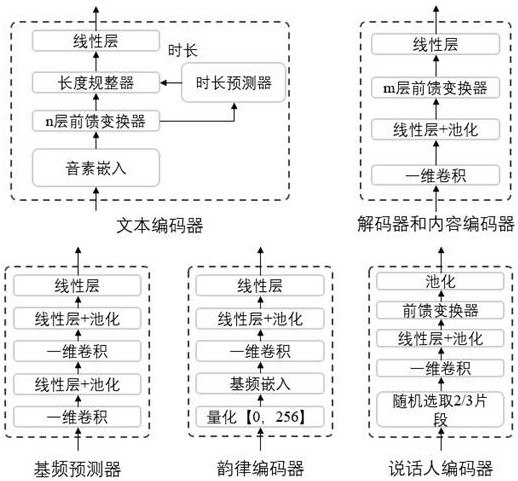
[0107] The proposed unified TTS and VC training framework is as follows figure 2 shown. Specifically, the structure of each sub-module can be as follows image 3 Show. The number of feedforward transformer (FFT) blocks is 2 in the text encoder and 6 in the decoder module. In each FFT block, the dimension of the hidden state is 256. The kernel size of all 1D convolutions is set to 3. The dropout rate is set to 0.5. The dimension of the last linear layer in the decoder is 80, which is consistent with the Mel spectral dimension. The size of the last linear layer in the encoders (text encoder, prosodic information encoder, content information encoder) is 256. Adam optimizer is used to update parameters. The initial learning rate is 0.001 and the learning rate decreases exponentially. In the inference stage, hifigan is used as a vocoder.
[0108] In addition, an additional duration model needs to be trained, which is very common in speech synthesis tasks, and the example ...
PUM
 Login to view more
Login to view more Abstract
Description
Claims
Application Information
 Login to view more
Login to view more - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap