

Data de-duplication method
A technology for data deduplication and data block, applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., can solve the problems of slow deduplication speed and formation of single points of failure, and achieve high deduplication rate and high reliability , the effect of excellent performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0040] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
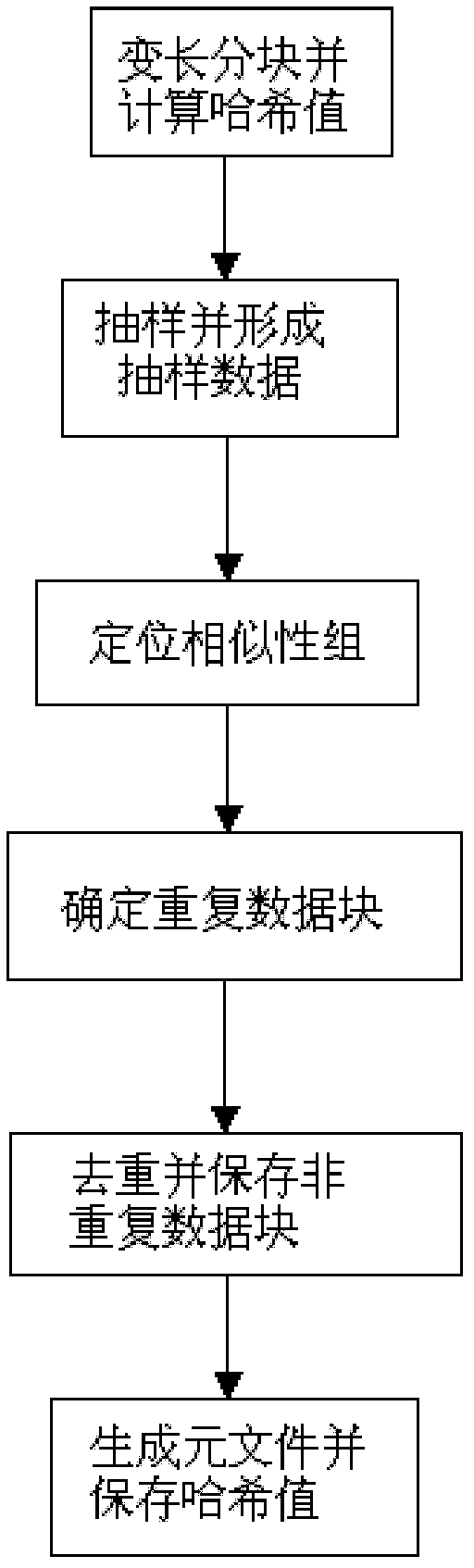
[0041] see figure 1 , a method for deduplication of the present invention, comprising the following steps:
[0042] First, write a file, divide the file into variable-length blocks, form multiple data blocks of different lengths, and calculate the hash value of the data blocks;
[0043] Form sample data of the file by sampling the hash value;
[0044] Locating a similarity group of documents by comparing sample data of documents with sample data of existing documents;
[0045] If the similarity between the sampled data of the file and the sampled data of the current existing file exceeds a certain value, it is determined that the data group corresponding to the sampled data of the current existing file is a similarity group of files.
[0046] Identify duplicate data blocks by comparing the hash value of the file with the hash value of the s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More