

Clustering method of massive high-dimensional audio data based on central index
A technology of audio data and clustering method, applied in electrical digital data processing, special data processing applications, instruments, etc., can solve the problem of high cost of k-means calculation, so as to shorten the clustering time, reduce the calculation cost, and reduce the clustering cost. class cost effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
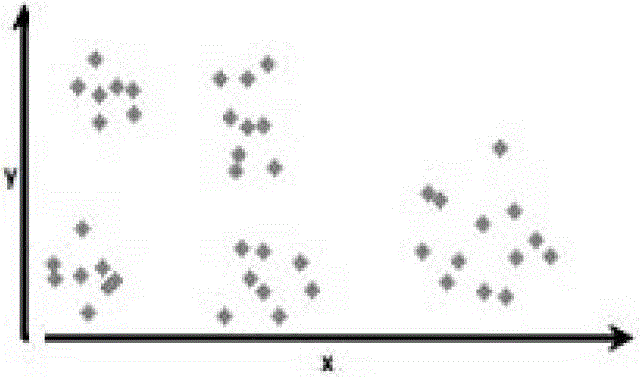
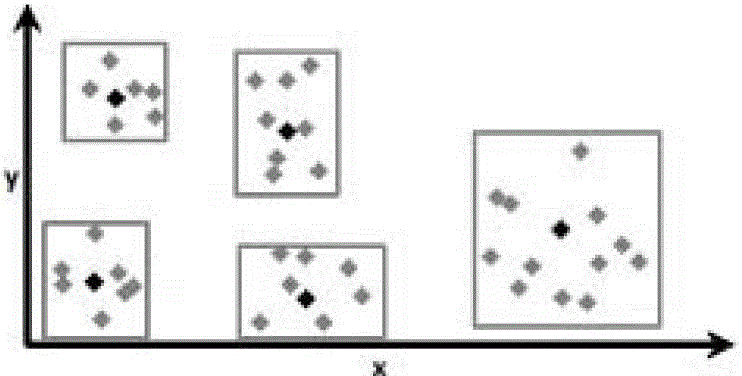
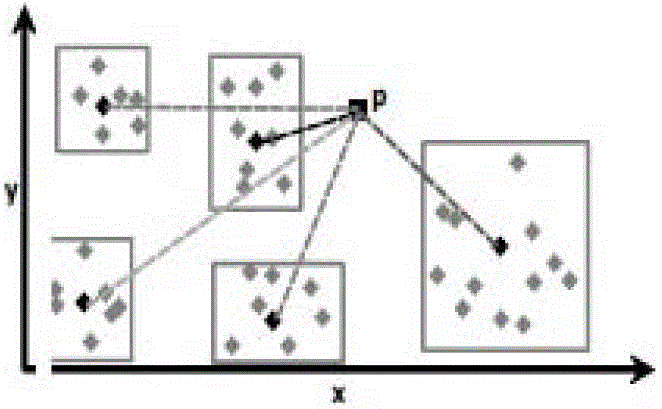
[0035] Figure 1 to Figure 4 It is a schematic diagram of a simulation example of the present invention, wherein k central points are clustered into 5 partitions, ie m=5. Calculate the center point and radius of each partition. For a given point P in a dataset containing massive high-dimensional data, calculate the distance between the given point P and the center point of each partition to obtain the center point of the partition closest to the given point P And the corresponding partition, that is, the selected partition and the center point of the selected partition can be obtained.
[0036] After obtaining the selected partition and the center point of the selected partition, calculate the distance between the given point P and the clustering points in the selected partition. According to the k-means clustering method, according to the distance between the given point P and the clustering points , which can realize the clustering of data points in the data set. In the em...
Embodiment 2
[0038] In this embodiment, high-dimensional audio data is used as the research correspondence, and the implementation environment includes a cluster of 14 computers, each of which has two chips, dual-core (2.70GHz), CPU is E5400, 4GB memory, and uses a linux operating system. Hadoop version is 0.20.3, and all experiments of MapReduce system use Java1.6.
[0039]Wherein, the audio database includes about 100,000 MP3 songs downloaded from the Internet, most of which are pop music, and the rest are classical and folk music. Main features are extracted from audio data and a 26-dimensional dataset is obtained. A point in a 26-dimensional space represents a frame of a song. The dataset includes a total of 167,876,767 26-dimensional vectors. The benchmark program is Mahout's k-means implementation, which is a well-known machine learning library developed by Apache.
[0040] Cluster the audio data of 10,000 songs, k are 50, 500, and 5,000 respectively. In order to remove the influe...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More