

Pipelining Computational Resources in General-Purpose Graphics Processing Units
A graphics processing unit and pipeline technology, applied to general-purpose stored program computers, computing, architecture with a single central processing unit, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
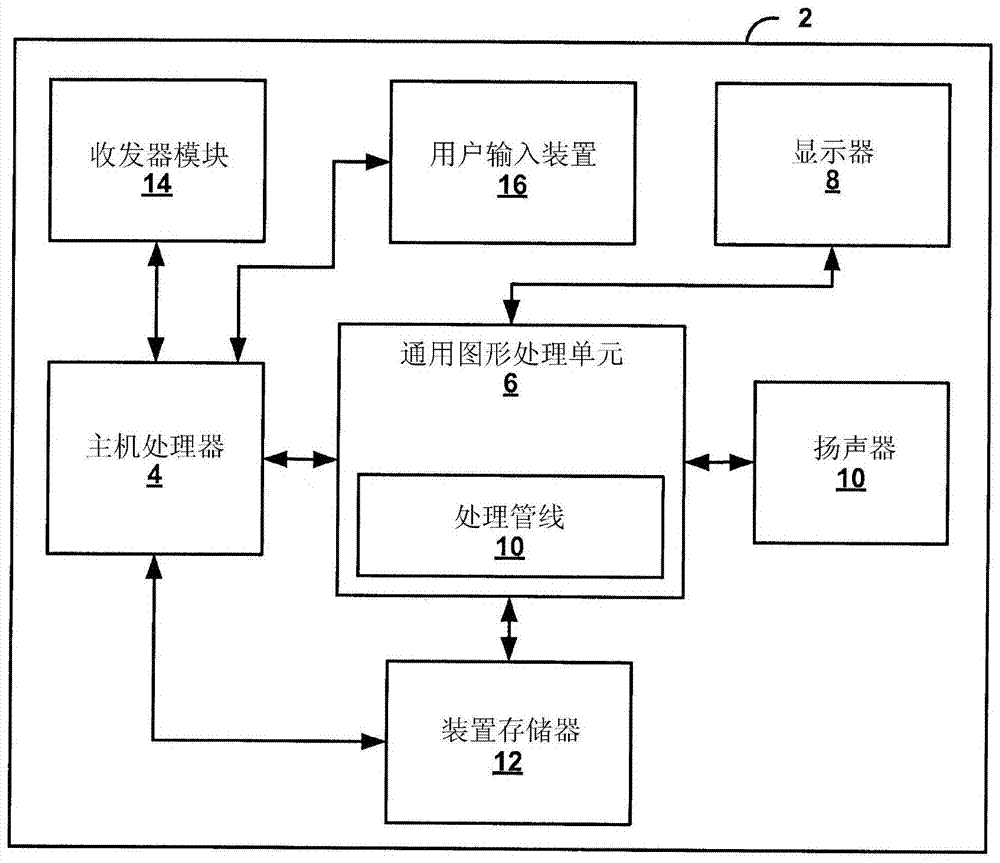
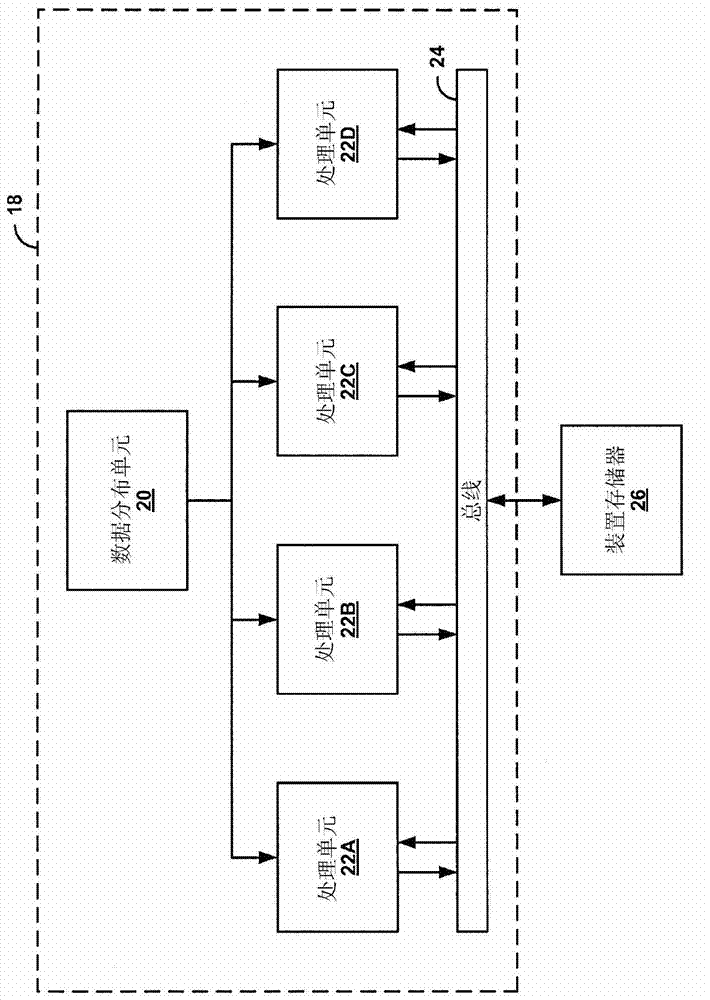
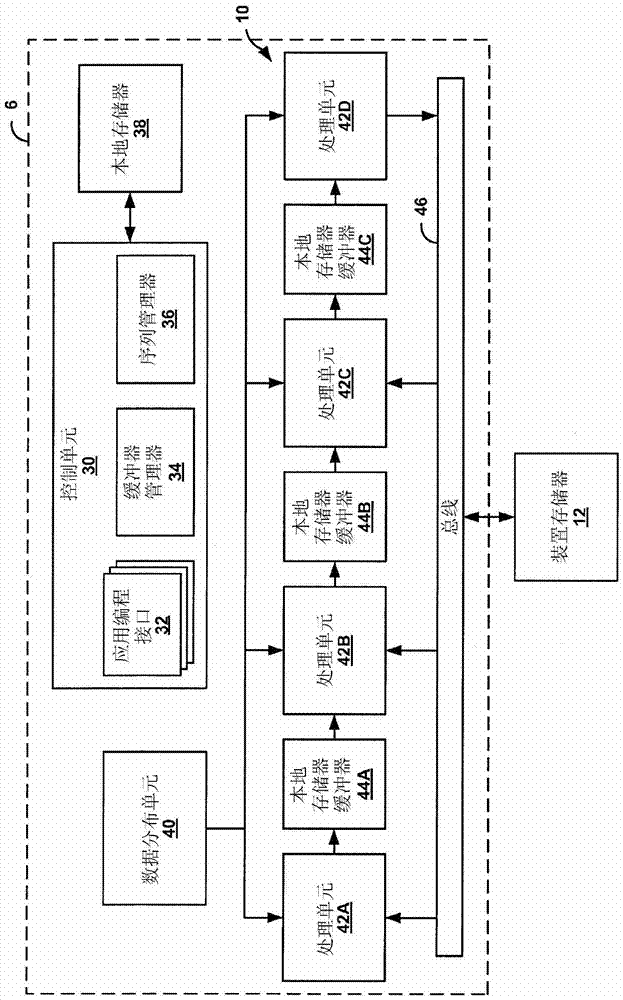
[0016] This disclosure describes techniques for extending the architecture of a general-purpose graphics processing unit (GPGPU) with parallel processing units to allow efficient processing of pipeline-based applications. Specifically, the techniques include configuring local memory buffers connected to parallel processing units operating as stages of a processing pipeline to hold data for transfer between the parallel processing units. Local memory buffers allow on-chip, low power, direct data transfer between parallel processing units. The local memory buffers may contain hardware-based data flow control mechanisms to enable data transfers between parallel processing units. In this way, data can be passed directly from one parallel processing unit to the next parallel processing unit in the processing pipeline via local memory buffers, effectively transforming the parallel processing unit into a series of pipeline stages. Local memory buffers can significantly reduce memory...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More