

Hadoop cluster-based large-scale Web information extraction method and system
A hadoop cluster and information extraction technology, applied in the field of large-scale Web information extraction, can solve problems such as low access efficiency and one-sided data extraction
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0031] The present invention will be described in further detail below in conjunction with the accompanying drawings.
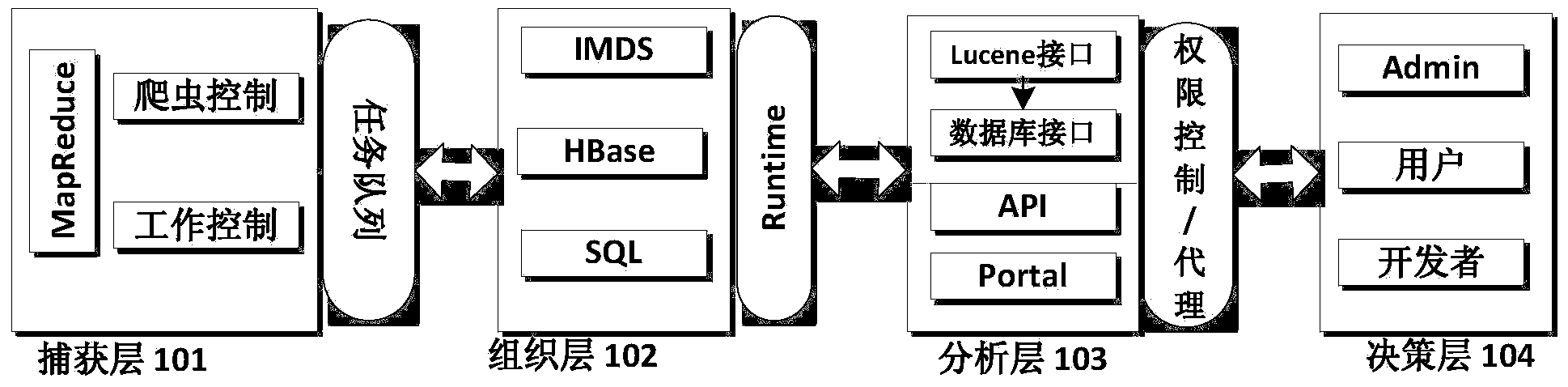
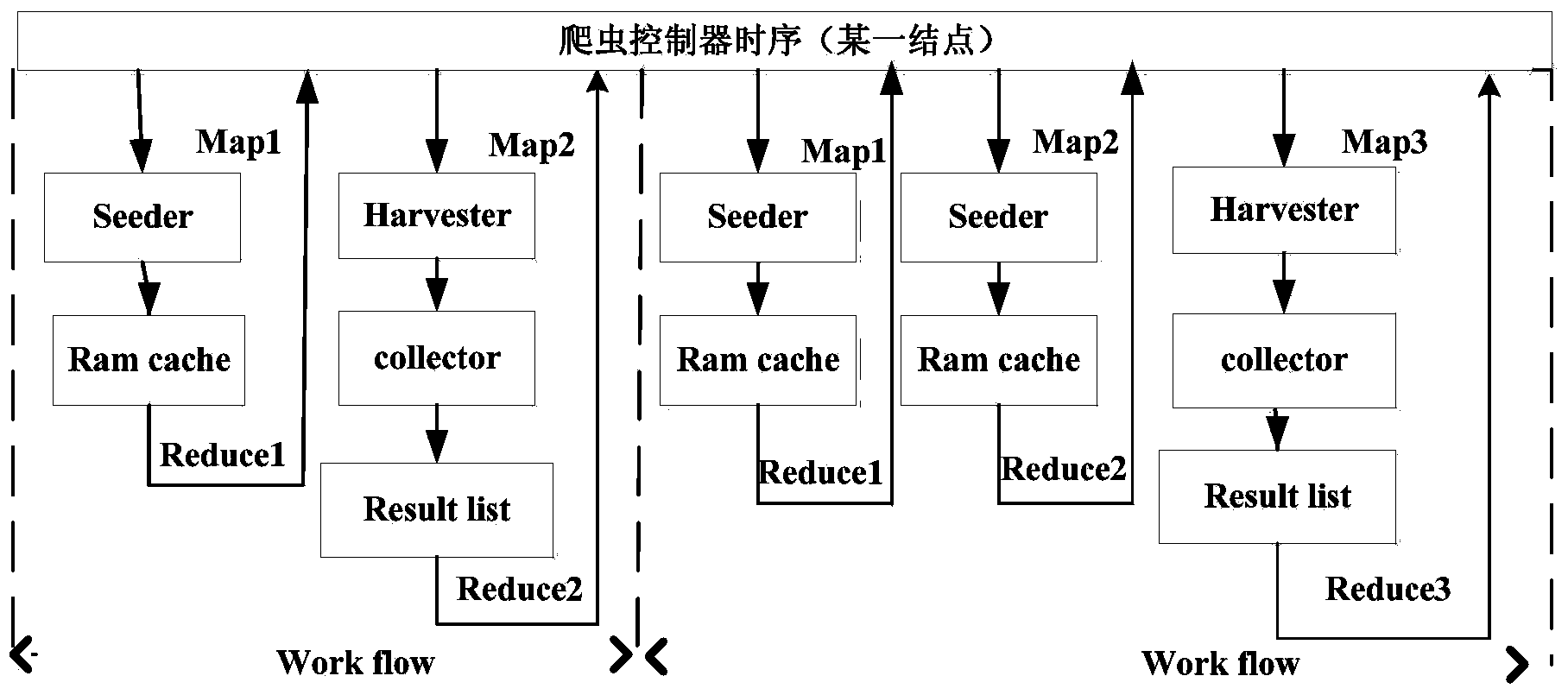
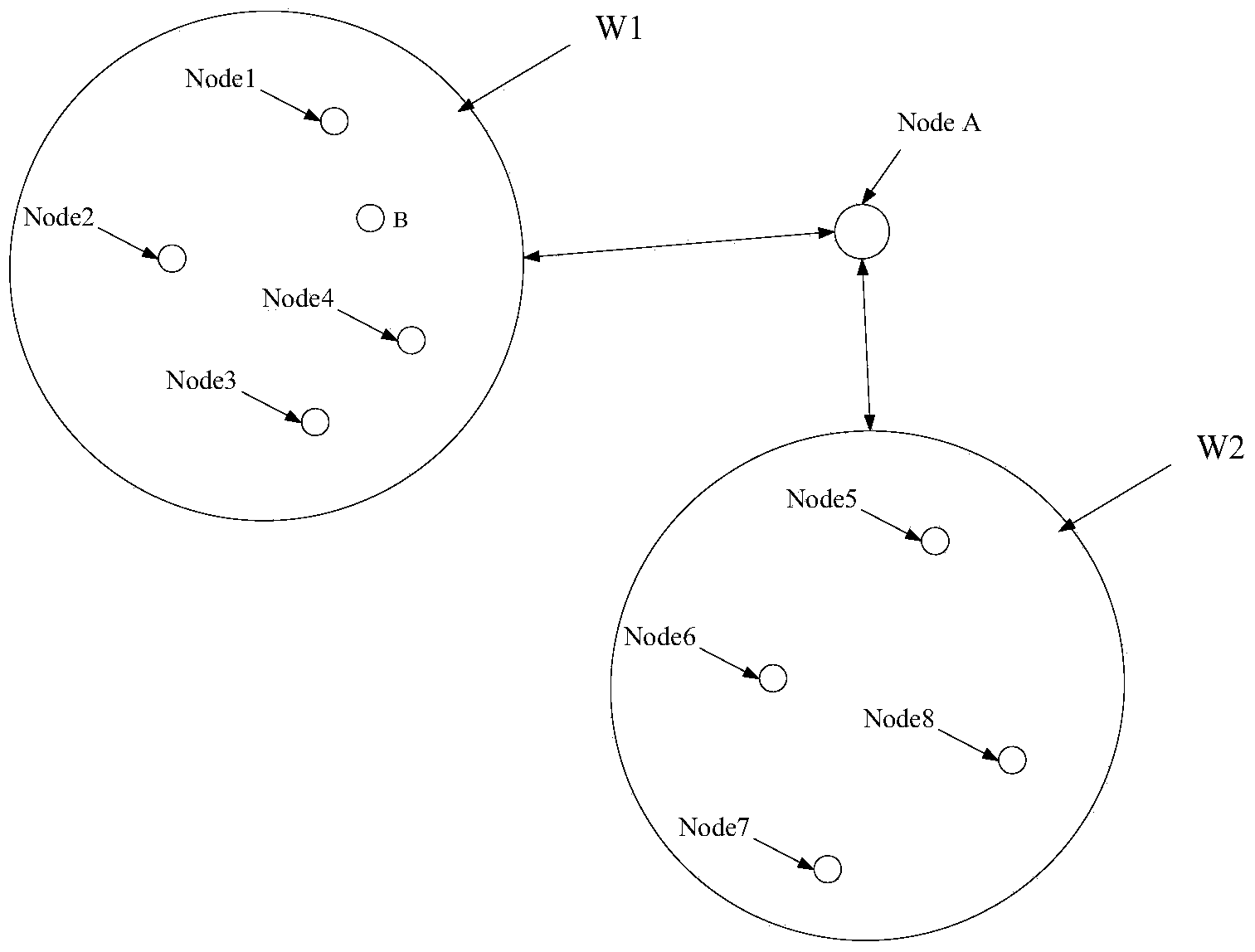
[0032] The architecture of the Hadoop cluster-based large-scale Web information extraction system in an embodiment of the present invention is a Hadoop cluster-based Web information extraction architecture. In this overall architecture, the database and service are separated into two independent clusters. In order to ensure the stable operation of the system, regular services and internal services are specifically established in the service cluster. The internal service is mainly used to keep the data extraction service running normally 24 hours a day, 7 days a week, without stopping due to resources occupied by regular services. In the service cluster, it is necessary to design a protection process to monitor the running status of the service. When a service fails, the server must be switched or restarted in time to make the system more stable. In order to...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More