

Memory caching method oriented to range querying on Hadoop
A memory cache and range technology, applied in the information field, can solve the problems of frequent data transfer in and out memory bumps, inability to establish a cache based on query requirements, and inability to adjust the cache granularity, etc., to improve the hit rate, improve performance, and reduce overhead.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
[0035] A memory cache method for range query on Hadoop, comprising the steps of:
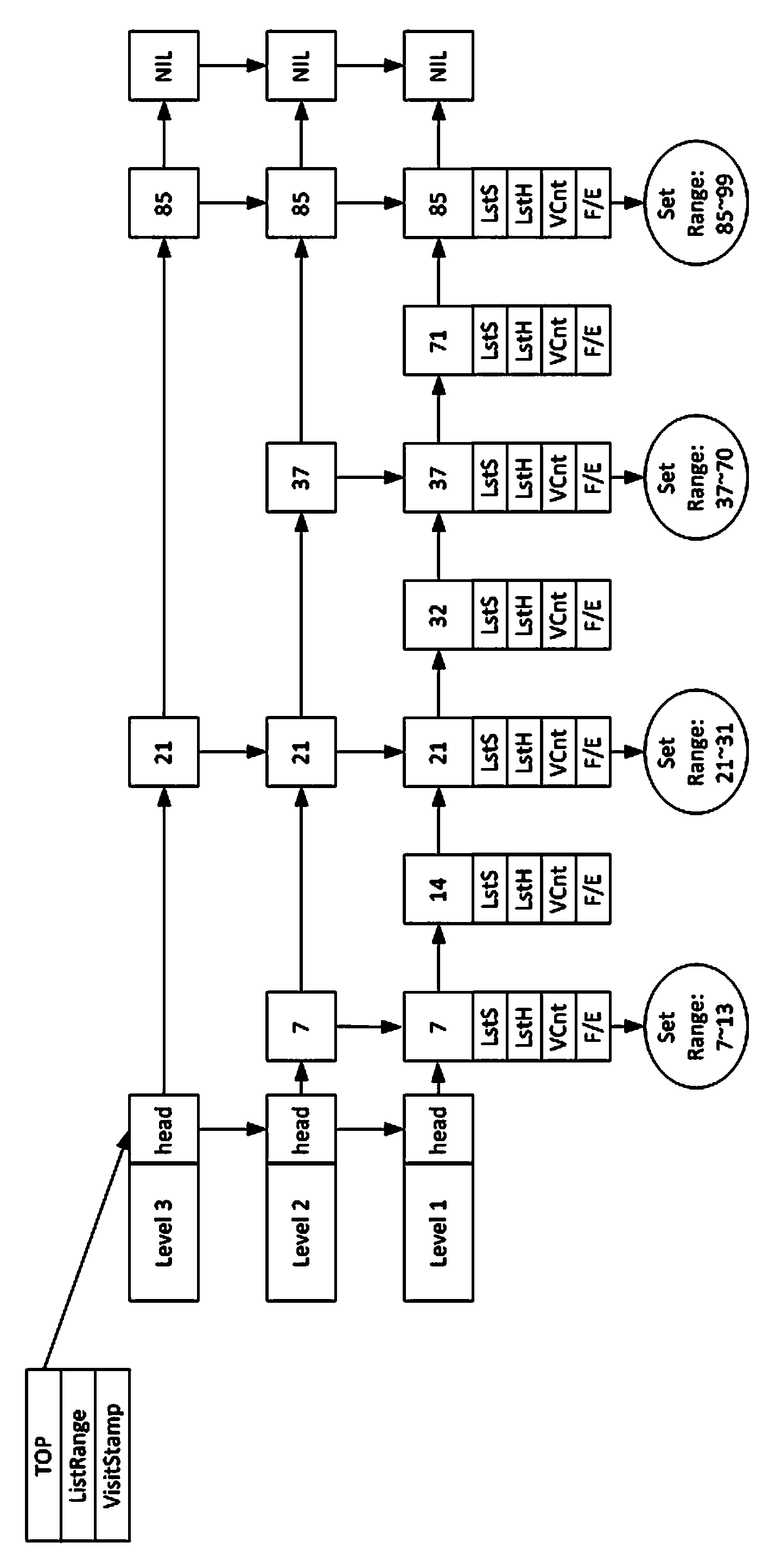
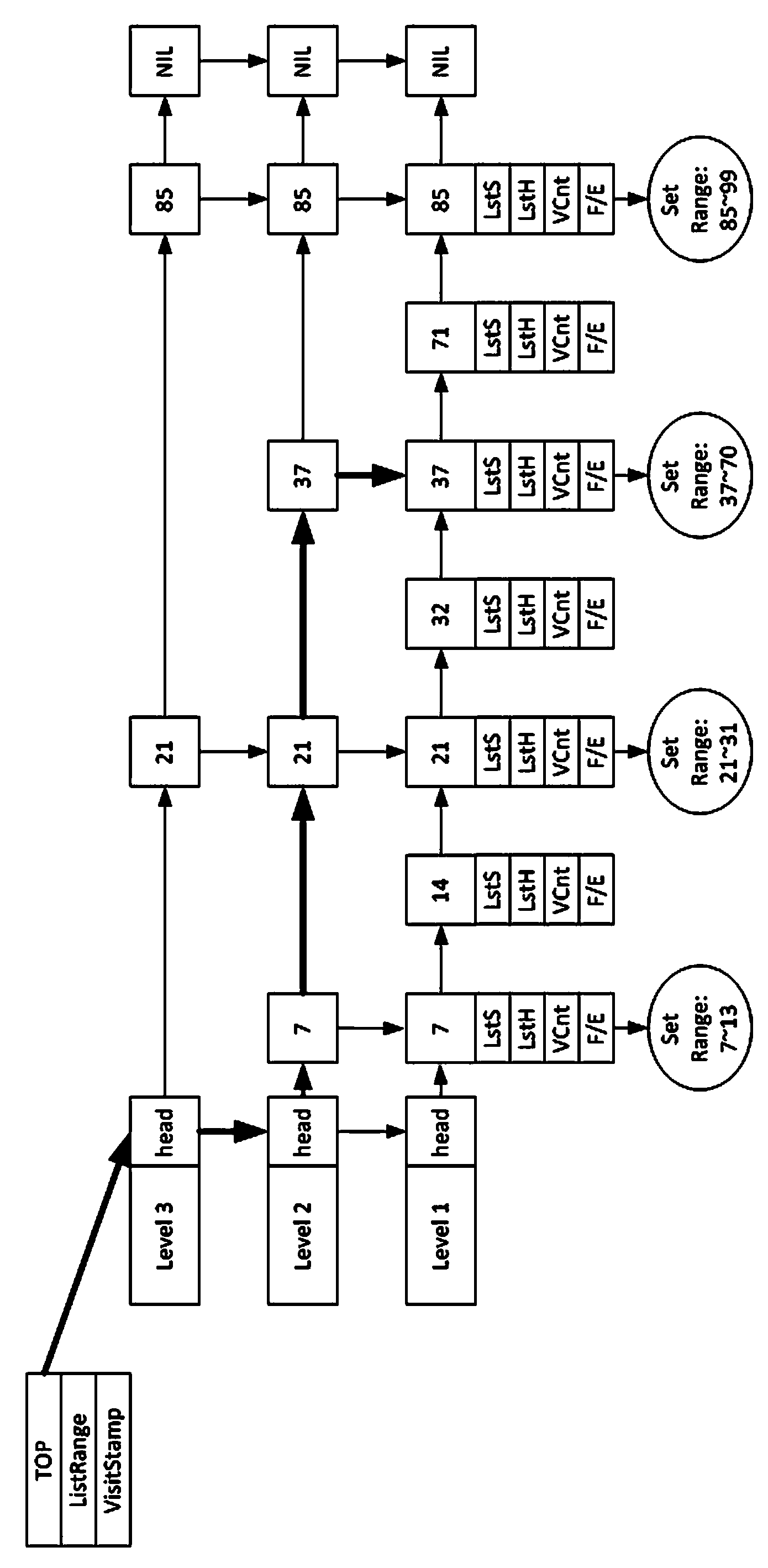
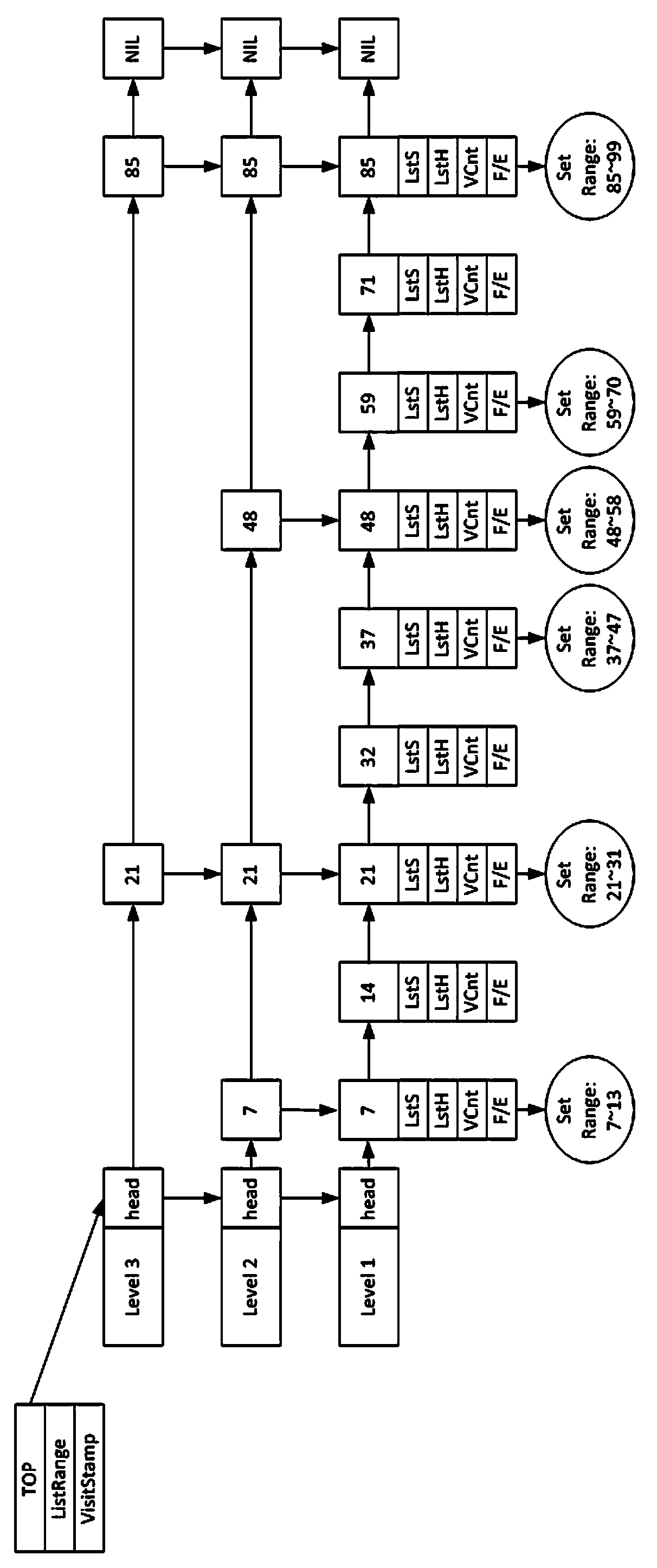
[0036]1) Build an index on the query attribute of Hadoop massive data, and store the index on HBase. Because HBase provides good scalability and fault tolerance, it can be considered that HBase has unlimited disk space, and the data in HBase is safe and reliable. HBase distributes data on each node of the cluster, and each node manages a part of the data, which is called a Region. The data in the Region is continuous with the primary key, and HBase uses this to support effective range queries;
[0037] 2) Establish a memory slice cache on the HBase index data. The goal of the cache is to select those index data that are accessed more frequently to be cached in memory, so as to reduce the disk IO (input and output) overhead of data query. Since it is necessary to establish a cache that supports efficient range queries, in the data structure of the memory cache, the present invention establishes ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More