

Speech emotion recognition method based on semi-supervised feature selection
A technology for speech emotion recognition and feature selection, applied in speech analysis, instruments, etc., can solve the problems of difficulty in labeling samples, feature differences, and speaker differences.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

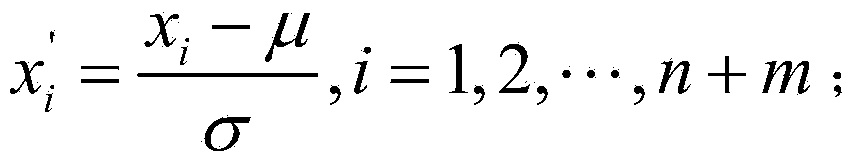
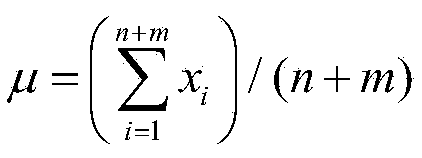
Examples
Embodiment 1
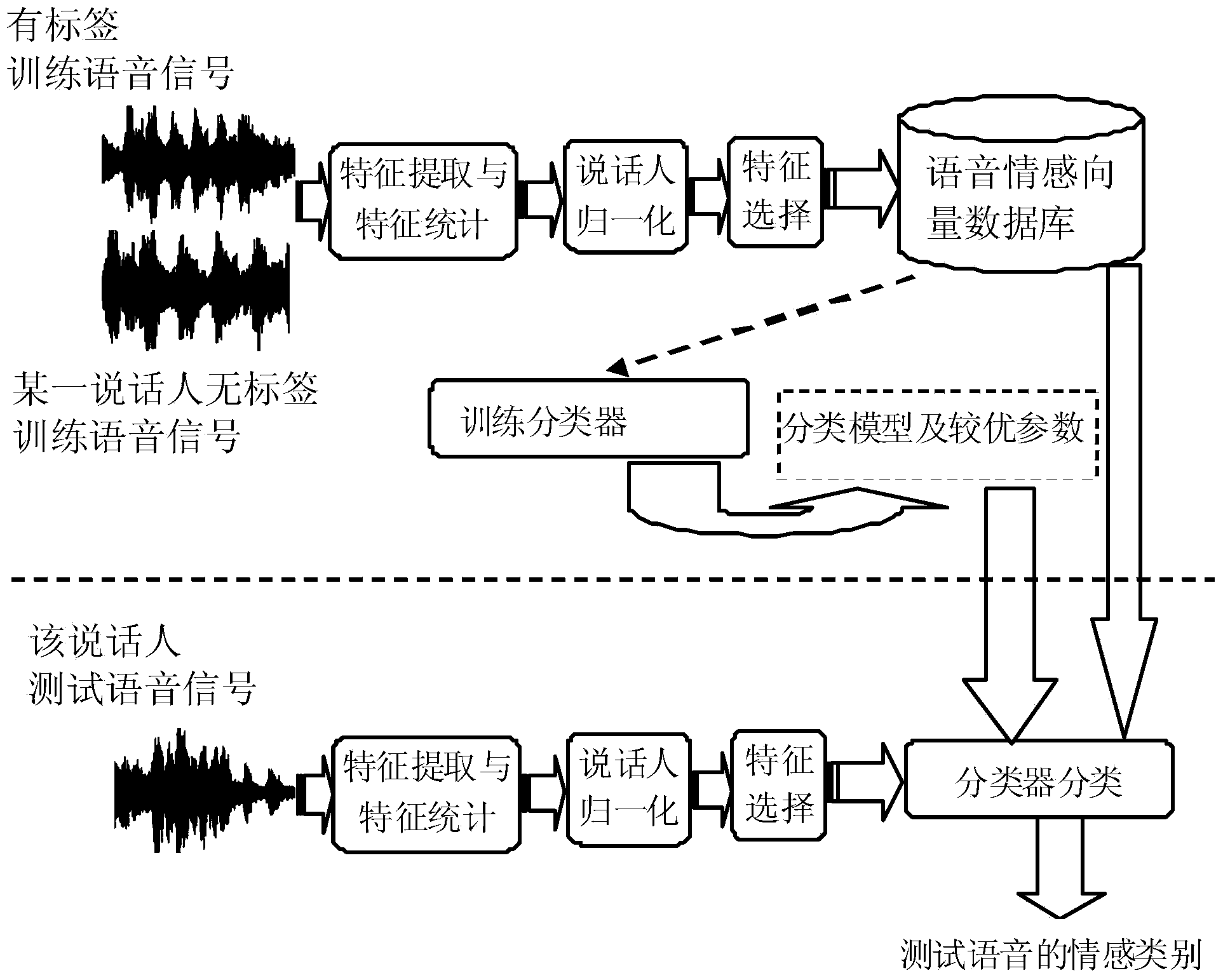
[0043] Such as figure 1 As shown, the speech emotion recognition method based on semi-supervised feature selection described in this embodiment includes two parts, the training phase and the recognition phase, now combined figure 1 The flow charts are detailed below.
[0044] 1. Training stage
[0045] In this stage, all speakers are trained separately to obtain the classifier corresponding to each speaker. The specific process is as follows:
[0046] Step 1: Extract MFCC, LFPC, LPCC, ZCPA, PLP, R for all speech training signals (for each training session, the speech signals of all labeled samples and the speech signal of a current speaker's unlabeled sample) -PLP features, where the number of Mel filters of MFCC and LFPC is 40; the linear prediction orders of LPCC, PLP, and R-PLP are 12, 16, and 16 respectively; the frequency segments of ZCPA are: 0, 106, 223, 352, 495, 655, 829, 1022, 1236, 1473, 1734, 2024, 2344, 2689, 3089, 3522, 4000. Therefore, the dimensions of each...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More