

Method and device for aggregate query in distributed databases
A database and distributed technology, applied in the field of database query, can solve problems such as no longer supporting aggregation query, and achieve the effect of reducing development time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
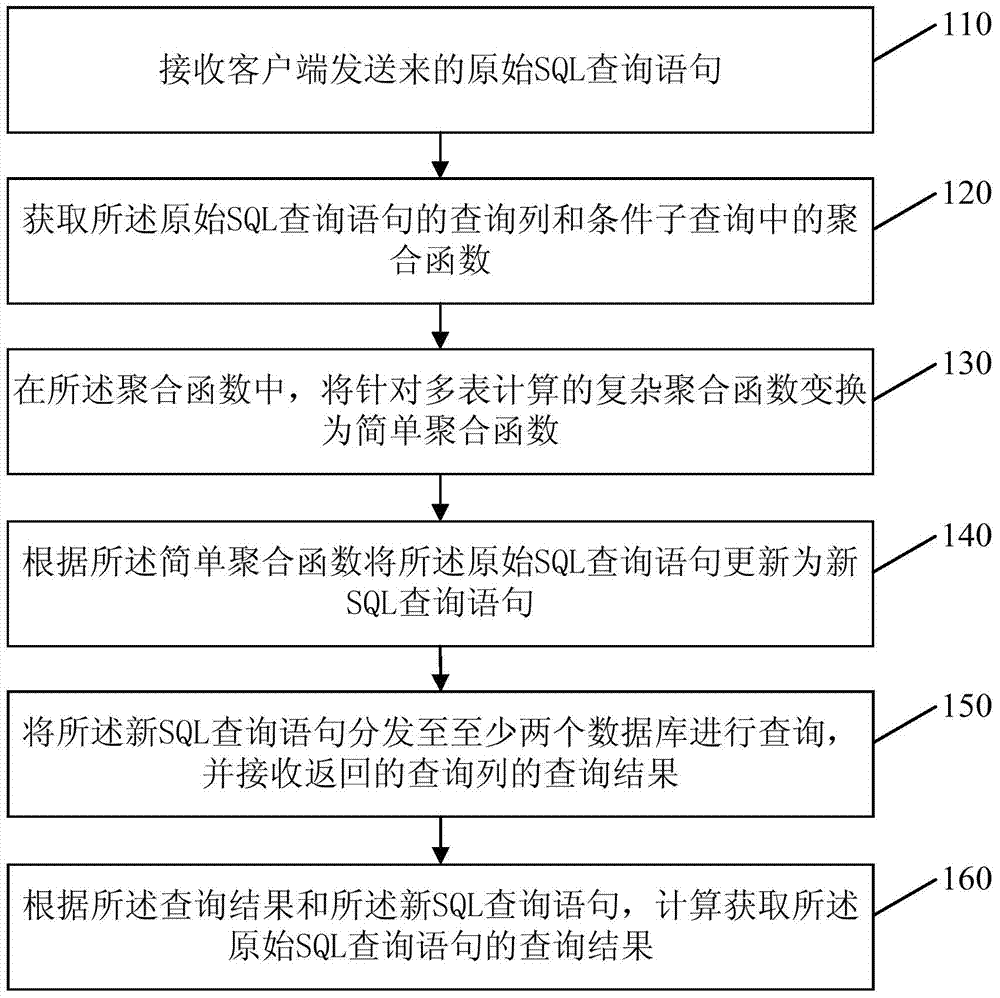
[0025] figure 1 It is a flow chart of a method for aggregate query in a distributed database provided by Embodiment 1 of the present invention, and this embodiment is applicable to realizing aggregate query in a distributed database. The distributed database includes a SQL (Structured Query Language, structured query language) node and at least one data node, wherein the SQL node is used to receive query commands and perform calculations according to the query commands, and the data node is used to store data. The method can be executed by the SQL node, and specifically includes the following steps:
[0026] Step 110, receiving the original SQL query statement sent by the client.
[0027] Wherein, the original SQL statement is the original query command manually input on the client. The client sends the query command to the SQL node, and the SQL node receives the original SQL statement sent by the client. The original SQL statement includes the SELECT keyword, query column,...
Embodiment 2
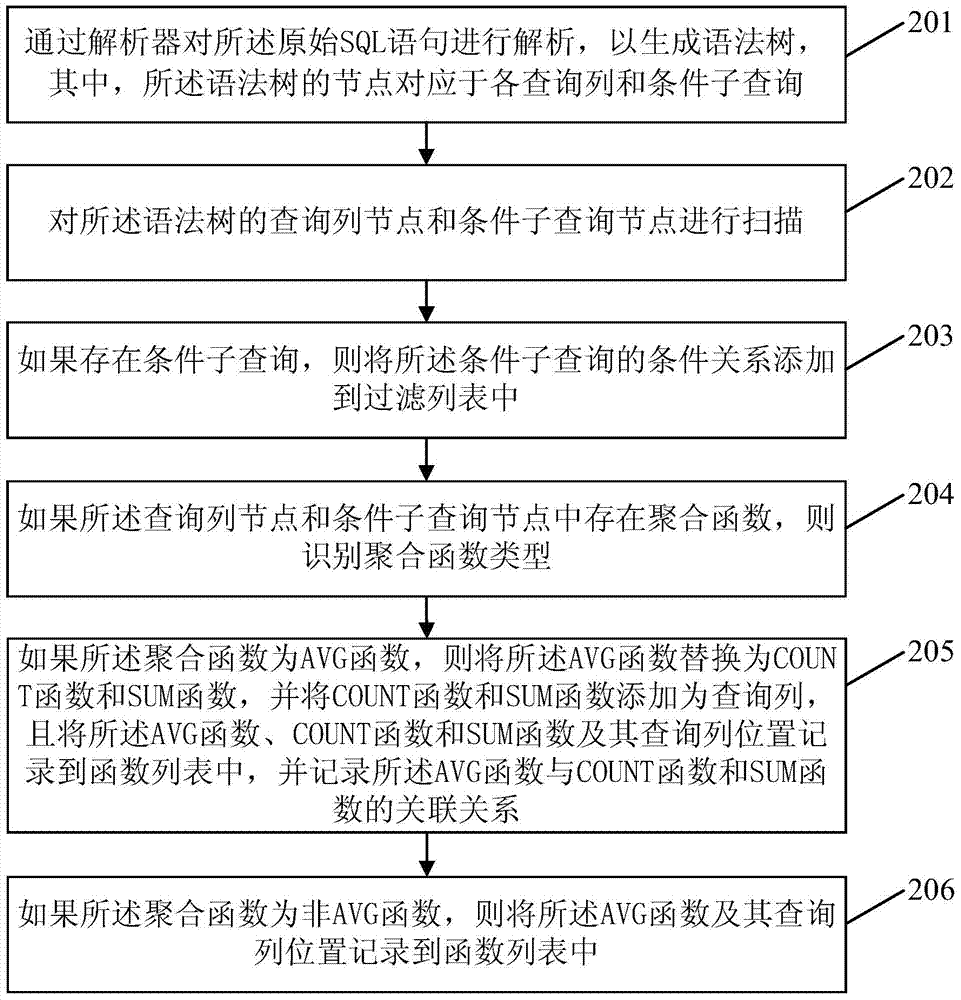
[0064] Embodiment 2 of the present invention provides a method for aggregation query in a distributed database, and specifically applies the method for aggregation query in a distributed database provided in Embodiment 1. The specific example is: Suppose there is a data table acid, which contains columns: id, name, sex, age, city, mobile, where id is the primary key.
[0065] The original query is: SELECT city, avg(age) FROM acid GROUP BY city HAVING(count(id)>100000).
[0066] The meaning of the original SQL query statement: from the acid data table, from the city that satisfies the condition of (count(id)>100000), obtain the data of city and the data of avg(age).
[0067] The above original SQL query statement includes two aggregate functions, avg(age), which is the average age, and count(id), which is to calculate the number of ids.
[0068] After the SQL node receives the original SQL query statement, it parses the original SQL query statement to generate a syntax tree (s...
Embodiment 3
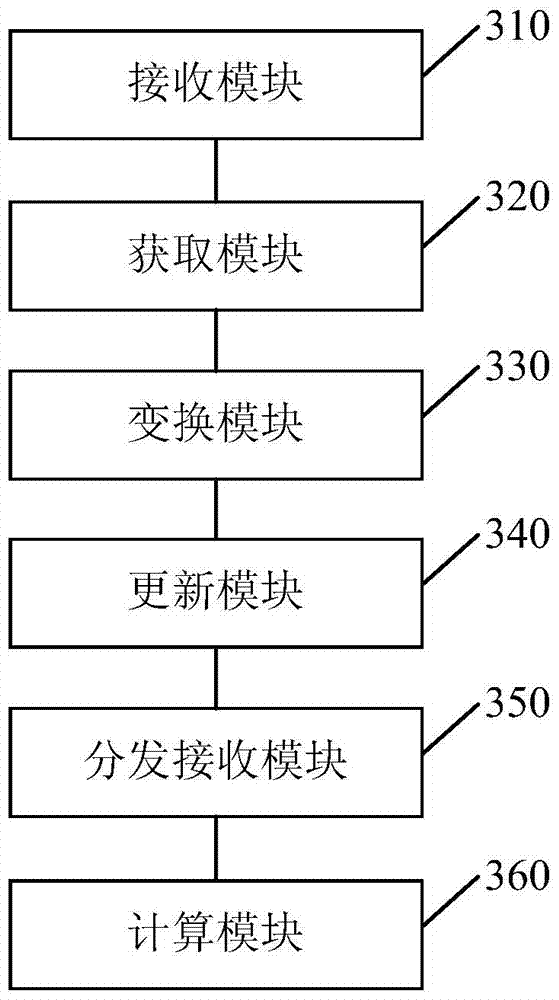
[0075] image 3 It is a schematic diagram of a device for aggregate query in a distributed database provided in Embodiment 3 of the present invention. The device for aggregate query in a distributed database provided in this embodiment is used to implement the method for aggregate query in a distributed database provided in Embodiment 1 . Such as image 3 As shown, the apparatus for aggregation query in a distributed database provided by Embodiment 3 of the present invention includes: a receiving module 310 , an acquiring module 320 , a transforming module 330 , an updating module 340 , a distribution receiving module 350 and a computing module 360 .
[0076] Wherein, the receiving module 310 is used to receive the original SQL query statement sent by the client;
[0077] The obtaining module 320 is used to obtain the query column of the original SQL query statement and the aggregation function in the conditional sub-query;
[0078] The transformation module 330 is used t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More