Method for incrementally capturing webpage contents
A web content and incremental technology, applied in the computer field, can solve problems such as low efficiency and reduced value, and achieve the effect of reducing the workload of crawling and improving the efficiency of update.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
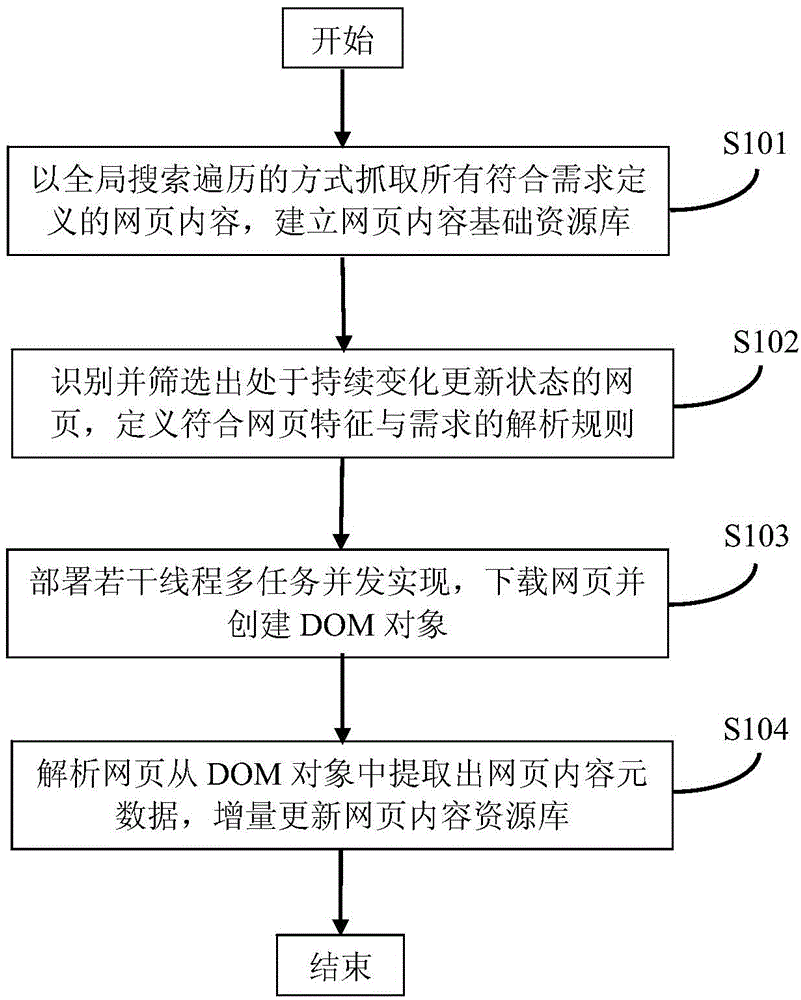
[0012] The method for incrementally capturing webpage content in the present invention is to extract the URL of the webpage in the state of changing and updating on the basis of establishing the webpage content resource library, and then grab the content metadata from the downloaded webpage and add Mass update the corresponding content in the resource library, or insert web page content that does not exist in the original resource library.
[0013] The incremental update of the basic resource library in the present invention includes the update of existing webpage content information and the addition of webpage content information under a brand new URL.
[0014] Such as figure 1 Shown, the inventive method comprises the steps:
[0015] Step S101, establishing a webpage content basic resource library:
[0016] Firstly, traverse all webpages meeting the requirement definition under the seed URL in a global search and traversal manner, download these webpages and analyze them a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com