

Text-dependent speaker recognition method based on joint deep learning
A speaker recognition and text-related technology, which is applied in the field of text-related speaker recognition, can solve problems such as poor robustness and inability to accurately represent the speaker's personality characteristics, and achieve the effects of improving accuracy, widening gaps, and narrowing differences
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
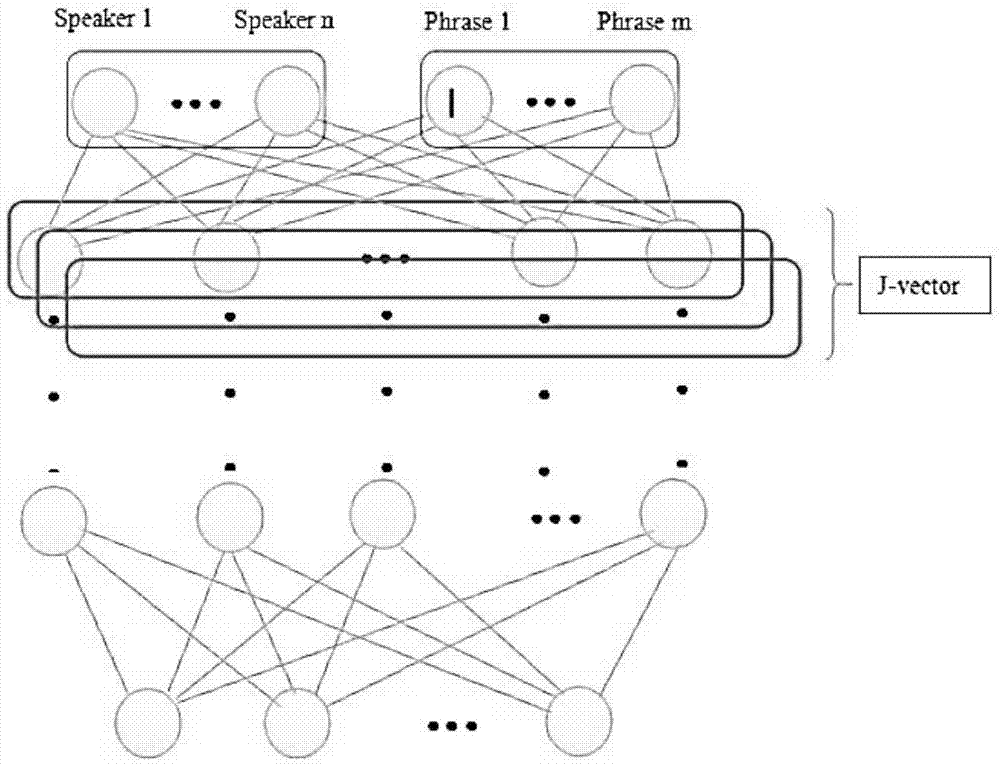
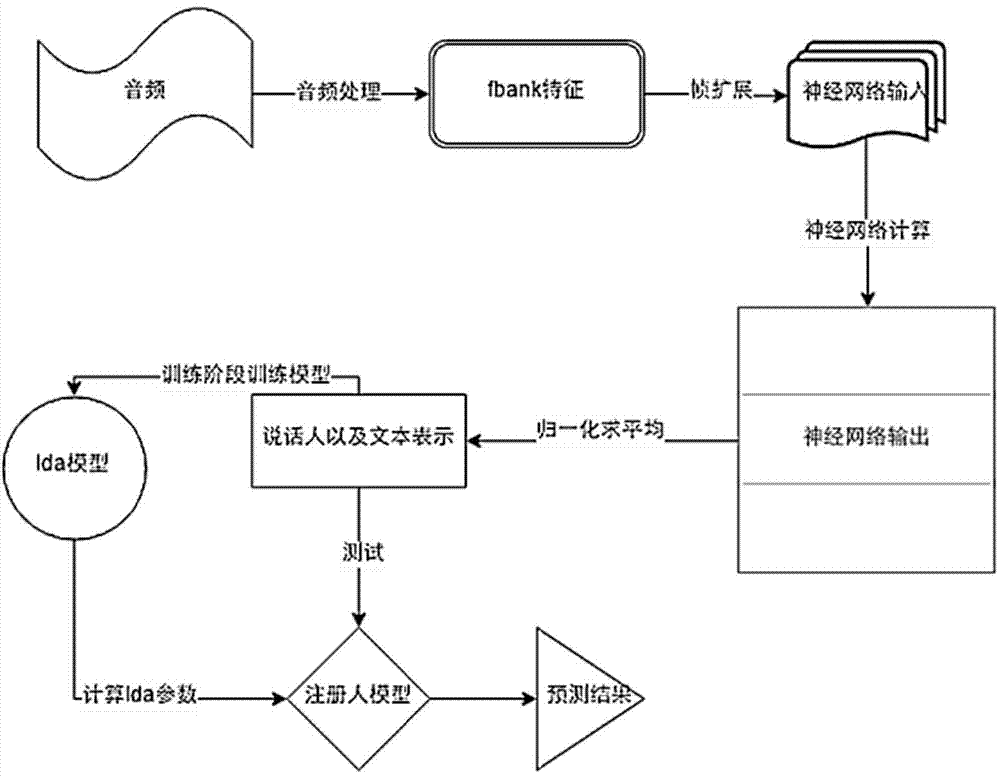
[0038]In this embodiment, the text information and the speaker are taken into consideration during the training of the deep neural network. For simplicity of implementation, the loss function of the speaker and the text information is directly added to obtain a new loss function. Due to the linear nature of the gradient, the gradient of each coefficient can be calculated independently, and then the coefficients of each non-output layer can be updated by the gradient of the new loss function (sum of two loss functions). When the performance of the two networks cannot be improved, the learning rate starts to decrease.
[0039] The federated learning of this embodiment avoids overfitting of any one task and makes the network more effective. Once the network training (development phase) is completed, j-vector features can be extracted on the last layer of the network, such as figure 1 shown. This feature can be used in various registration and evaluation models.
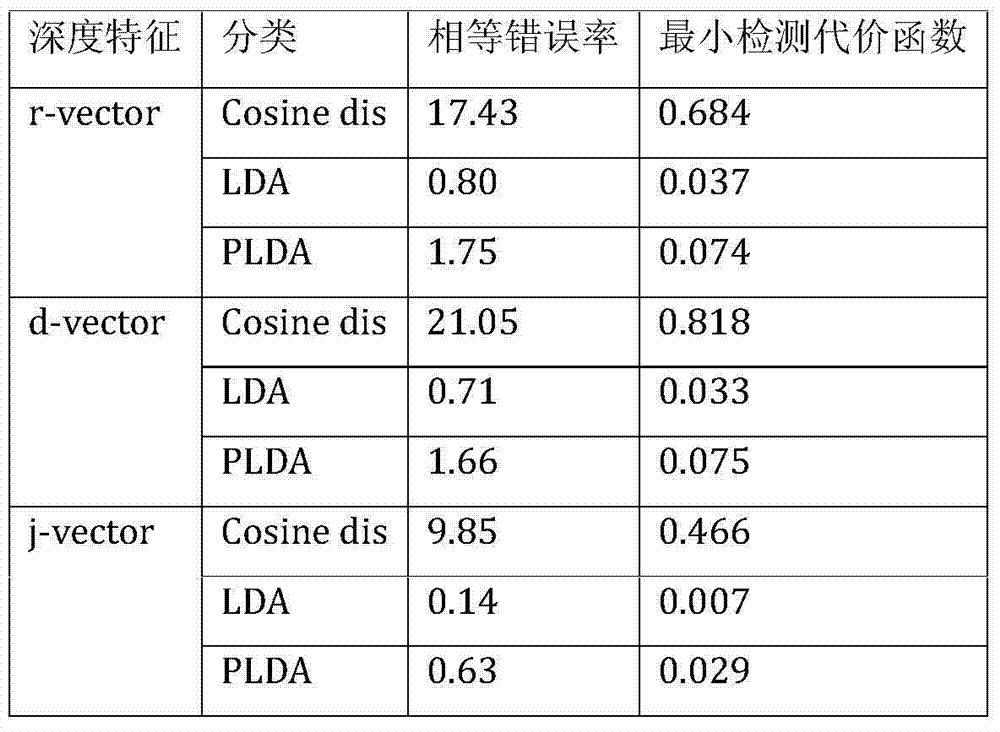
[0040] Cosine...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More