File semantics and system real-time state based redundant data deduplication method
A technology of redundant data and file semantics, applied in electrical digital data processing, special data processing applications, instruments, etc., can solve the problems of read performance impact, read operation response delay, data read performance loss, etc., to save storage space, Maintain efficient responsiveness and increase flexibility
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0068] In order to describe the present invention more specifically, the technical solutions of the present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
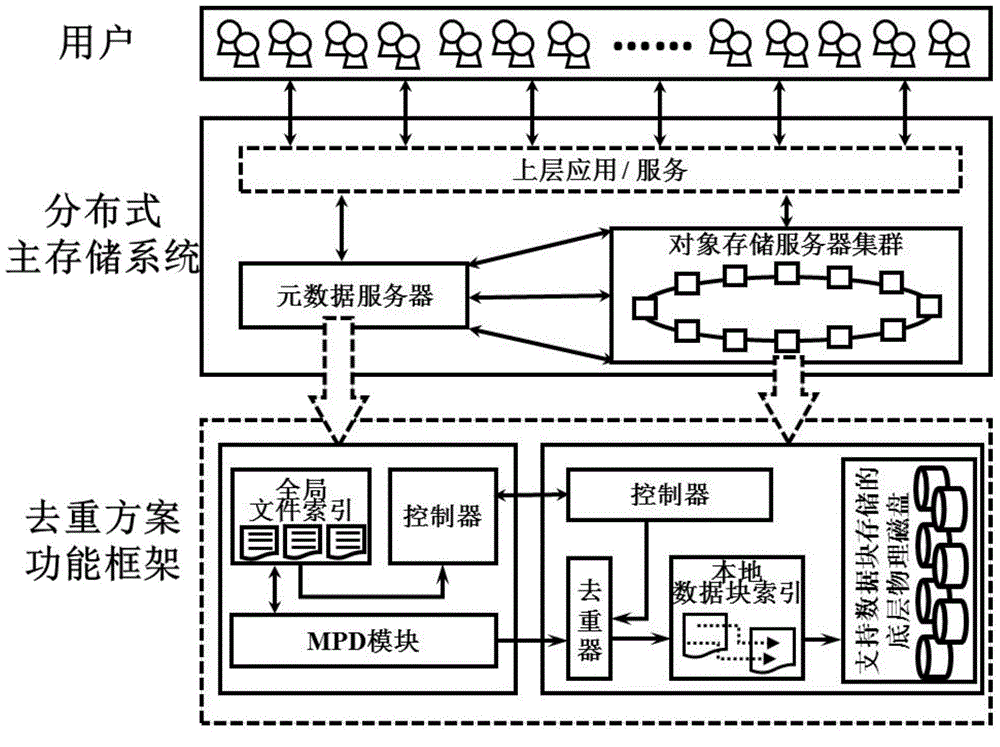
[0069] Such as figure 1 As shown, in the actual operating application environment, the redundant data deduplication scheme based on file semantics and real-time system status of the present invention runs in a general-purpose distributed primary storage system, and the storage system mainly includes metadata servers and object storage server clusters; in:
[0070] The metadata server is responsible for receiving user requests and directing the requests to the corresponding object storage servers. It is also responsible for detecting the running status of the entire distributed primary storage system and maintaining a global index in units of file names. The index contains the "signature", location information and metadata information of each file. This s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More