

A Parallelized Frequent Probabilistic Subgraph Search Method Based on Merge Clustering
A search method and probabilistic technology, applied in structured data retrieval, special data processing applications, instruments, etc., can solve problems such as high space-time complexity, achieve the effects of ensuring clustering accuracy, increasing scalability, and shortening calculation time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0030]Below in conjunction with specific embodiment, further illustrate the present invention, should be understood that these embodiments are only used to illustrate the present invention and are not intended to limit the scope of the present invention, after having read the present invention, those skilled in the art will understand various equivalent forms of the present invention All modifications fall within the scope defined by the appended claims of the present application.
[0031] The present invention comprises the following stages during concrete implementation:
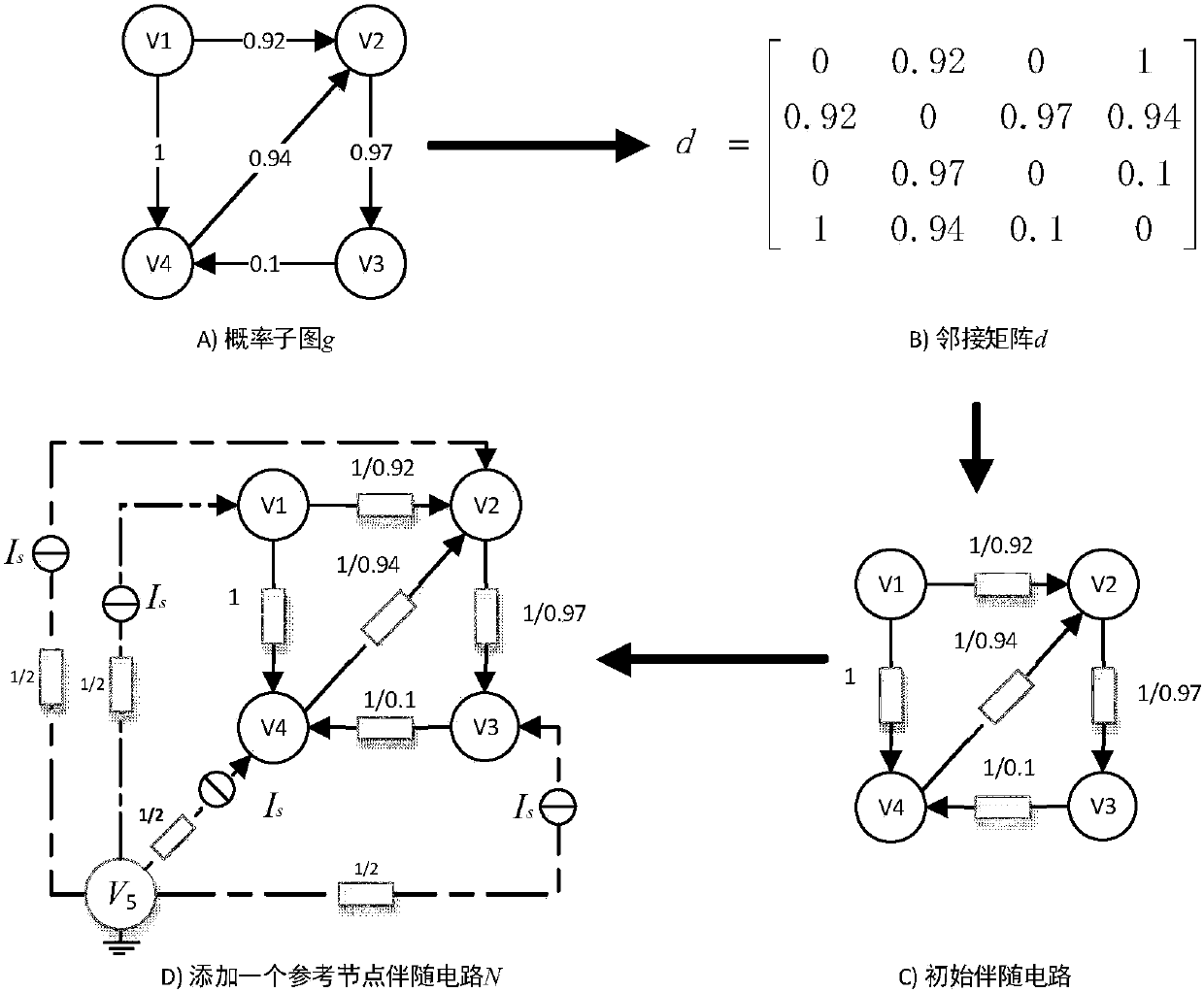
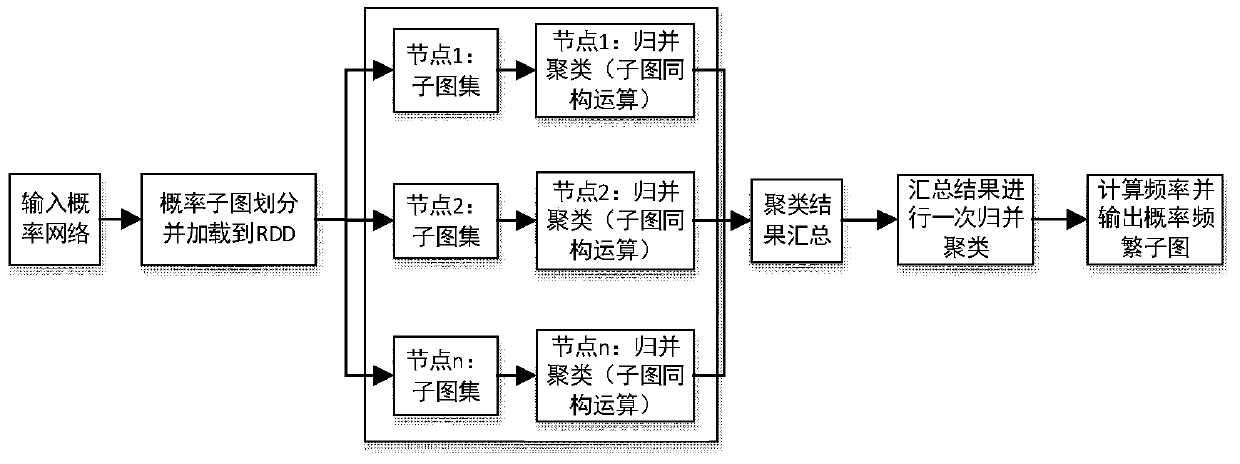
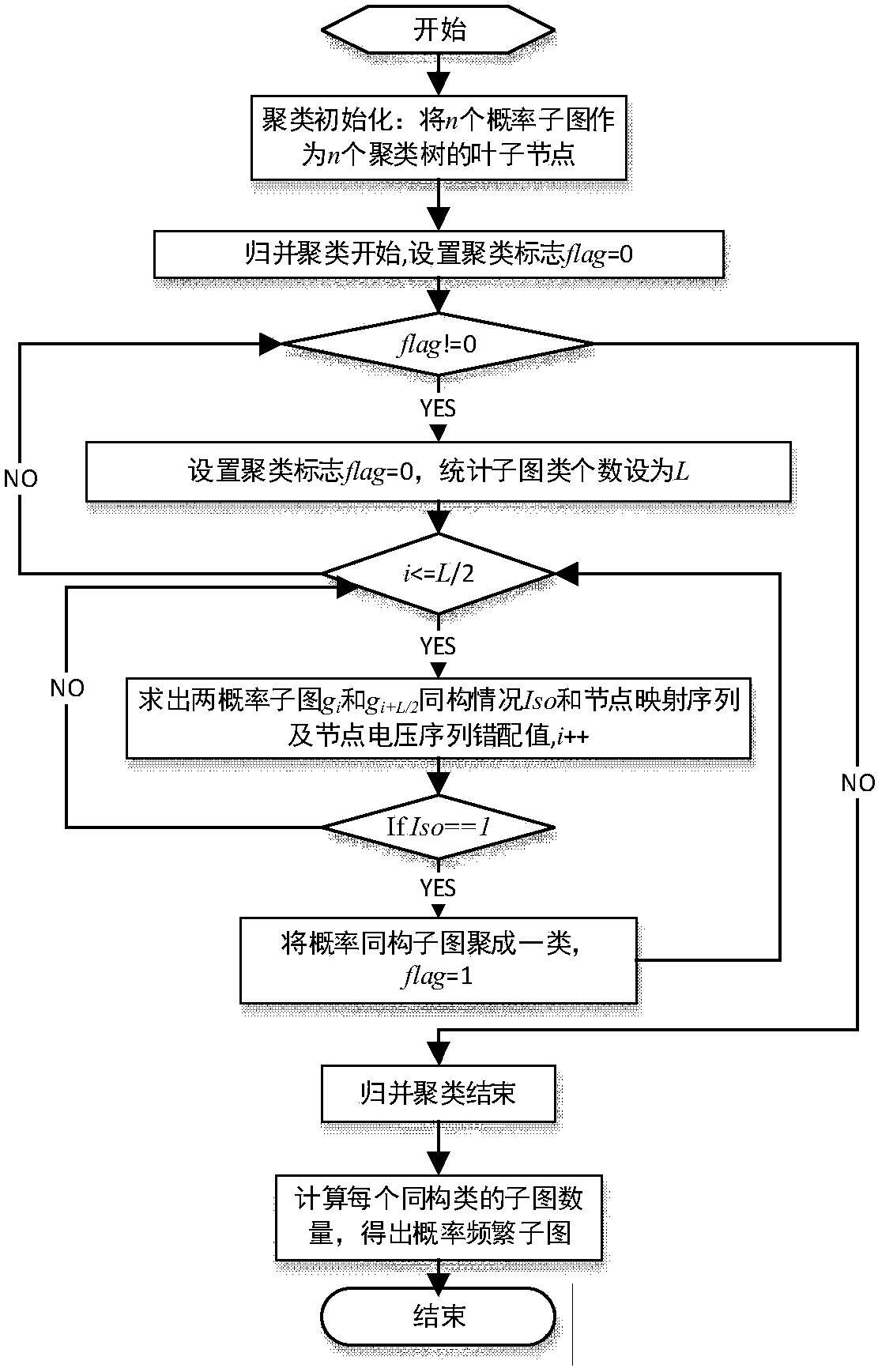
[0032] Step 1, preprocessing the probability subgraph. From the input probabilistic network (probability graph), all probability subgraphs of a given node size are identified without repetition or omission. Using the implementation structure based on the Spark parallel framework, the obtained probability subgraphs are stored in the HDFS file system, and then all probability subgraph files are loaded into ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More