

Speech recognition modeling method and speech recognition modeling device
A speech recognition model and speech recognition technology, applied in speech recognition, speech analysis, instruments, etc., can solve problems such as poor speech recognition performance, constraint modeling methods, complex speech signals, etc., to improve recognition speed and recognition accuracy Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0020] Embodiments of the present invention are described in detail below, examples of which are shown in the drawings, wherein the same or similar reference numerals designate the same or similar elements or elements having the same or similar functions throughout. The embodiments described below by referring to the figures are exemplary only for explaining the present invention and should not be construed as limiting the present invention. On the contrary, the embodiments of the present invention include all changes, modifications and equivalents coming within the spirit and scope of the appended claims.
[0021] figure 1 It is a flowchart of an embodiment of the modeling method for speech recognition of the present invention, such as figure 1 As shown, the above-mentioned modeling method for speech recognition may include:
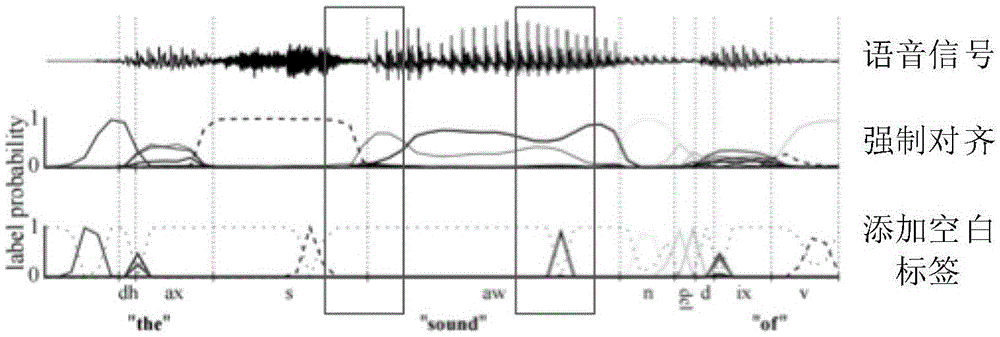
[0022] Step 101, converting the speech signal into a sequence of feature vectors, and converting the marked text corresponding to the speech signal i...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More