

Method for automatically obtaining short text of knowledge domain from community question-and-answer website
A knowledge field and community question-and-answer technology, which is applied in the field of automatically obtaining short texts in the knowledge field from community question-and-answer websites, can solve problems such as unfavorable use and learning of learners, inability to fully cover resources, and incomplete resources, so as to facilitate learning and use. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0056] The present invention will be further described in detail below in conjunction with specific embodiments, which are for explanation rather than limitation of the present invention.
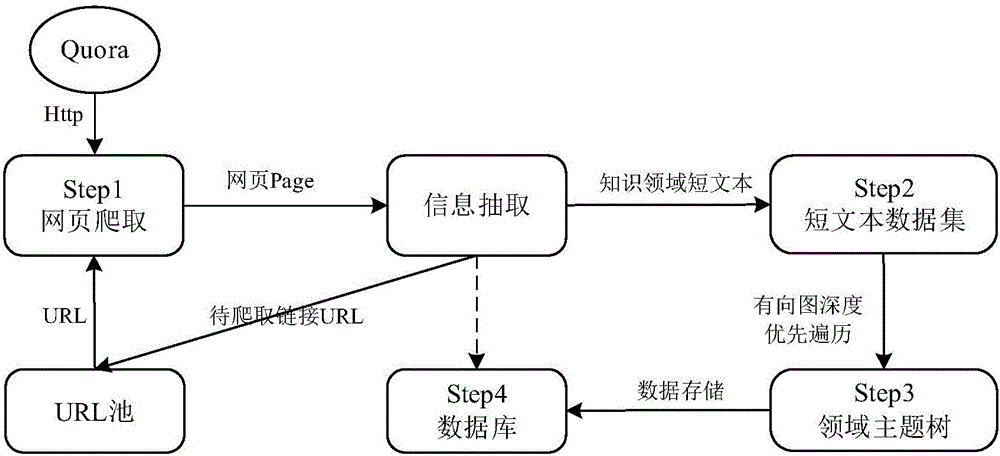
[0057] The present invention is a method for automatically acquiring short texts in the knowledge field from a community Q&A website, which realizes automatic collection and sorting of short texts in the knowledge field of the community Q&A website. It includes the following steps.
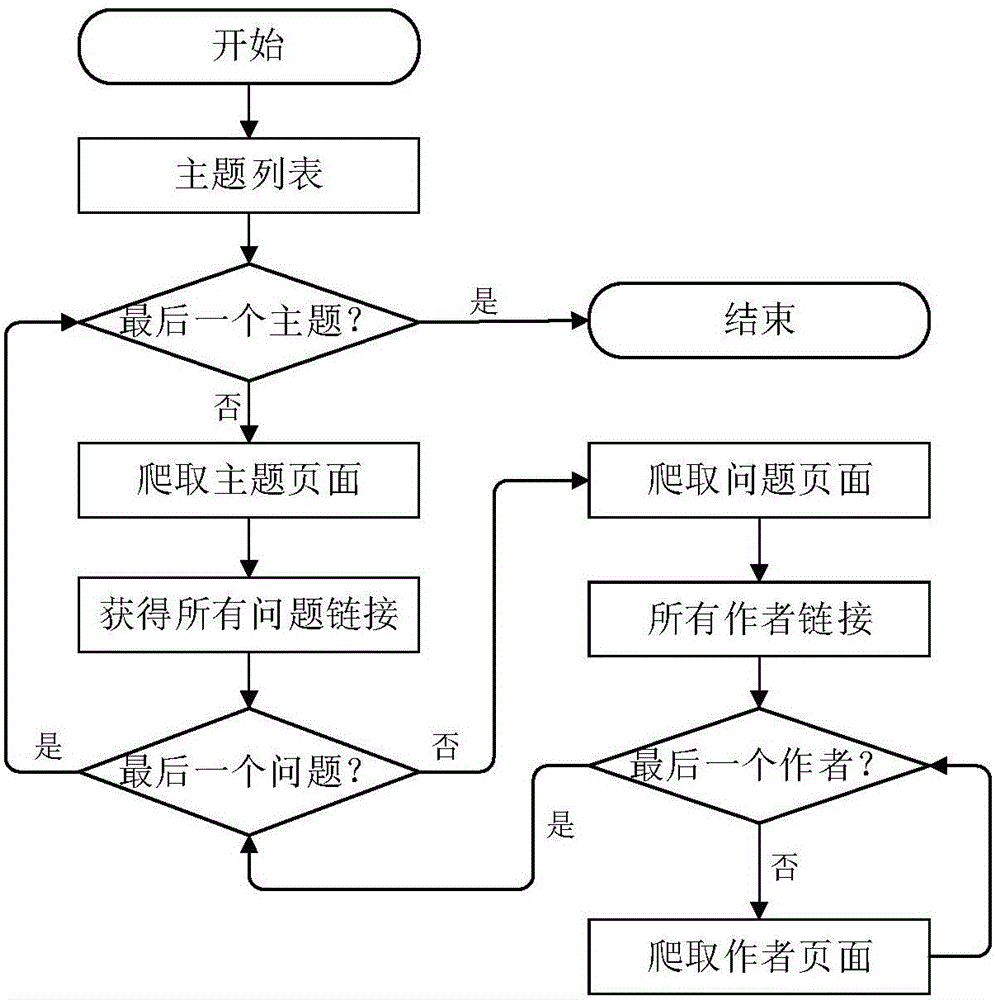
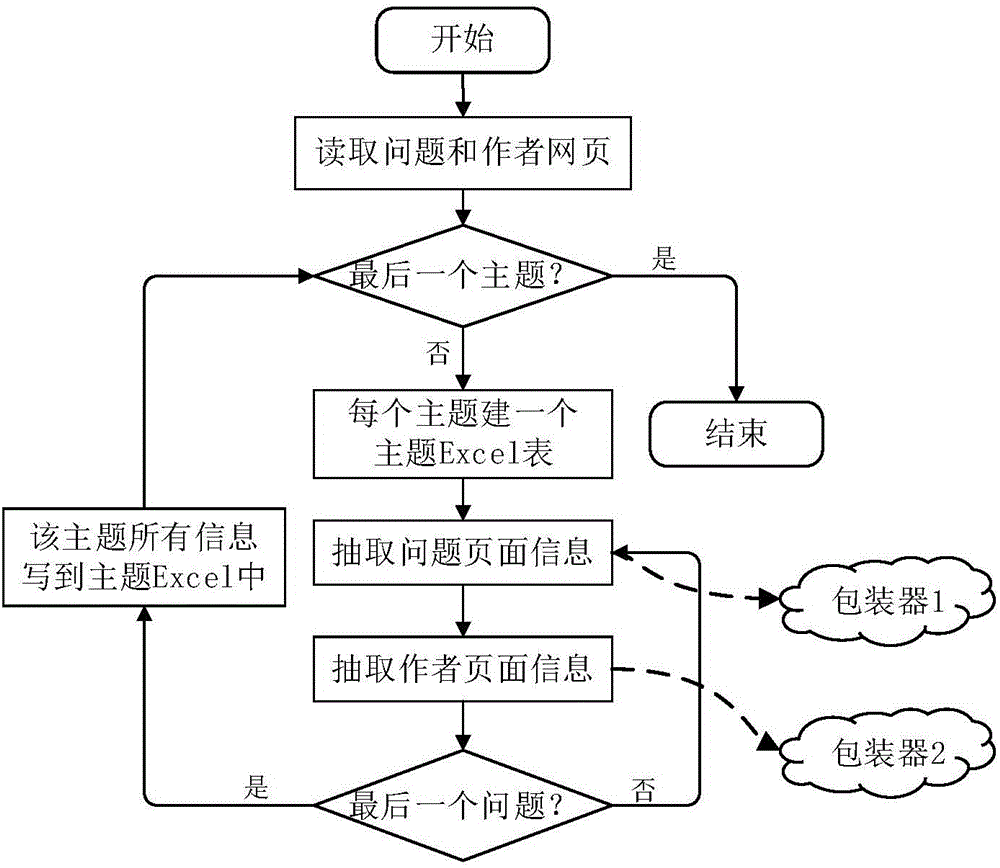
[0058] (1) Crawling the web pages of the knowledge domain in the community question and answer website: crawl the dynamic web pages of the community question and answer website and ensure the integrity of the data. Taking the Quora website as an example, web pages containing knowledge domain knowledge include topic pages, question pages, and author pages, which are crawled according to the depth-first traversal algorithm. First, crawl the topic page according to the Quora topic page address, obtain the hyperlinks t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More