

Speech recognition method and device
A speech recognition and speech technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problem of high error rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

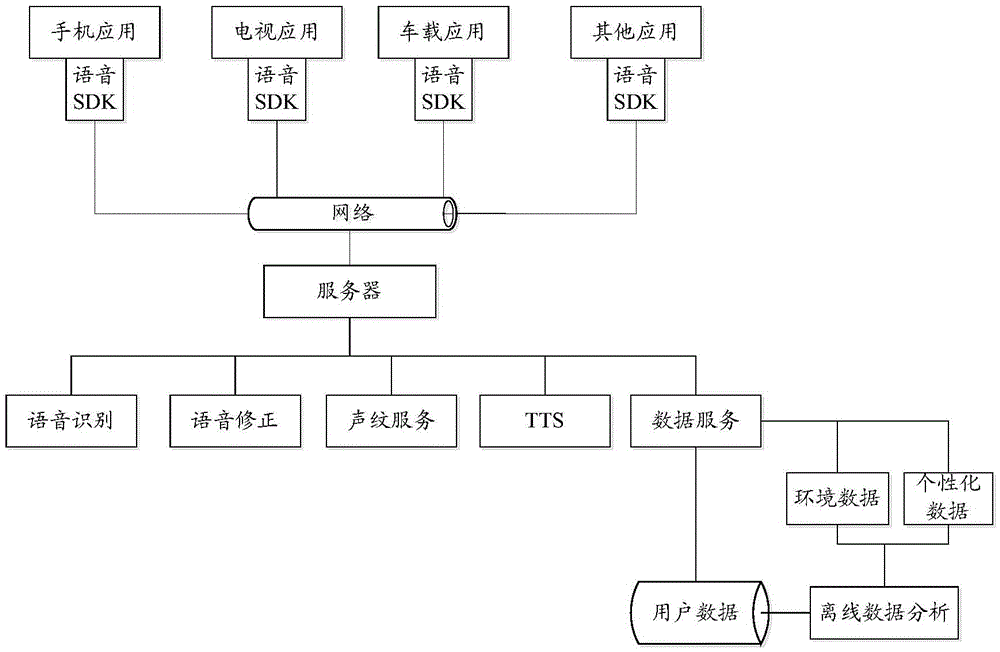
Examples
Embodiment 1
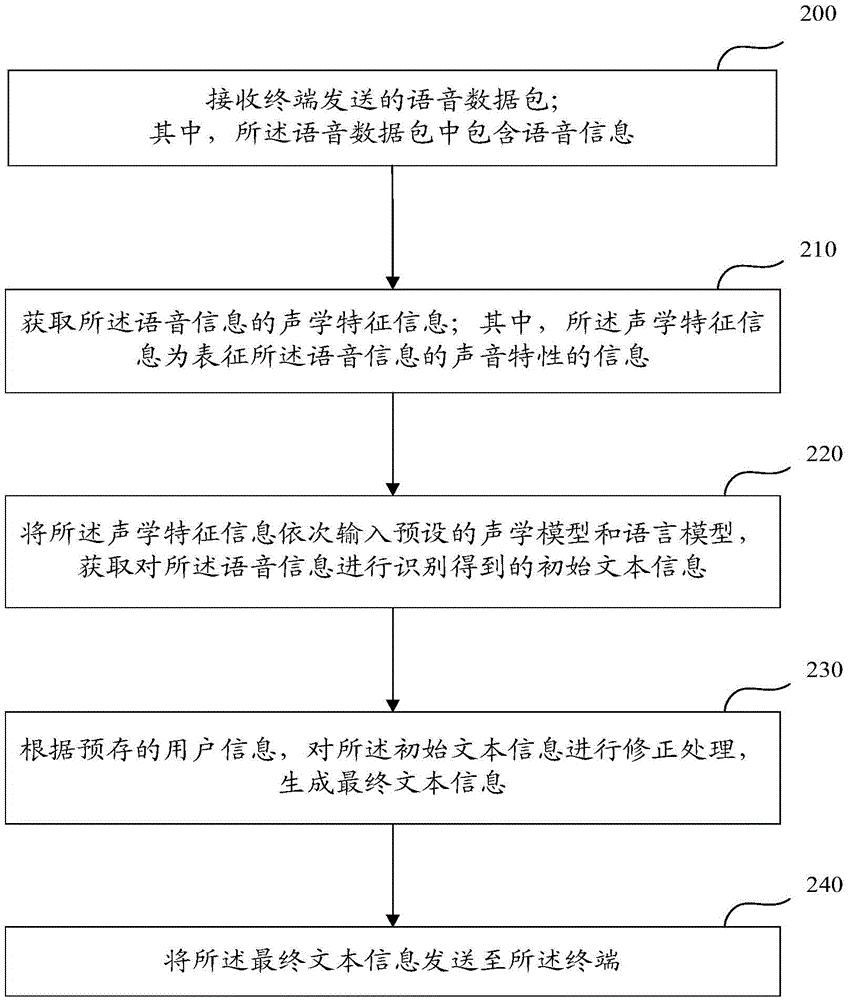
[0028] refer to figure 2 As shown, in the embodiment of the present invention, the process of the server performing speech recognition includes:
[0029] Step 200: Receive a voice data packet sent by the terminal; wherein, the voice data packet includes voice information.
[0030] In the embodiment of the present invention, the terminal calls the SDK (Software Development Kit; Software Development Kit) to obtain the voice information input by the user through the voice collection part; the terminal generates a voice data packet according to the voice information; and the voice data The package is sent to the server.
[0031] Optionally, a wireless communication network is included between the terminal and the server, and the terminal sends the voice data packet containing the voice information to the server through the wireless communication network.
[0032] Further, after the server receives the voice data packet sent by the terminal, it performs noise removal processing ...
Embodiment 2
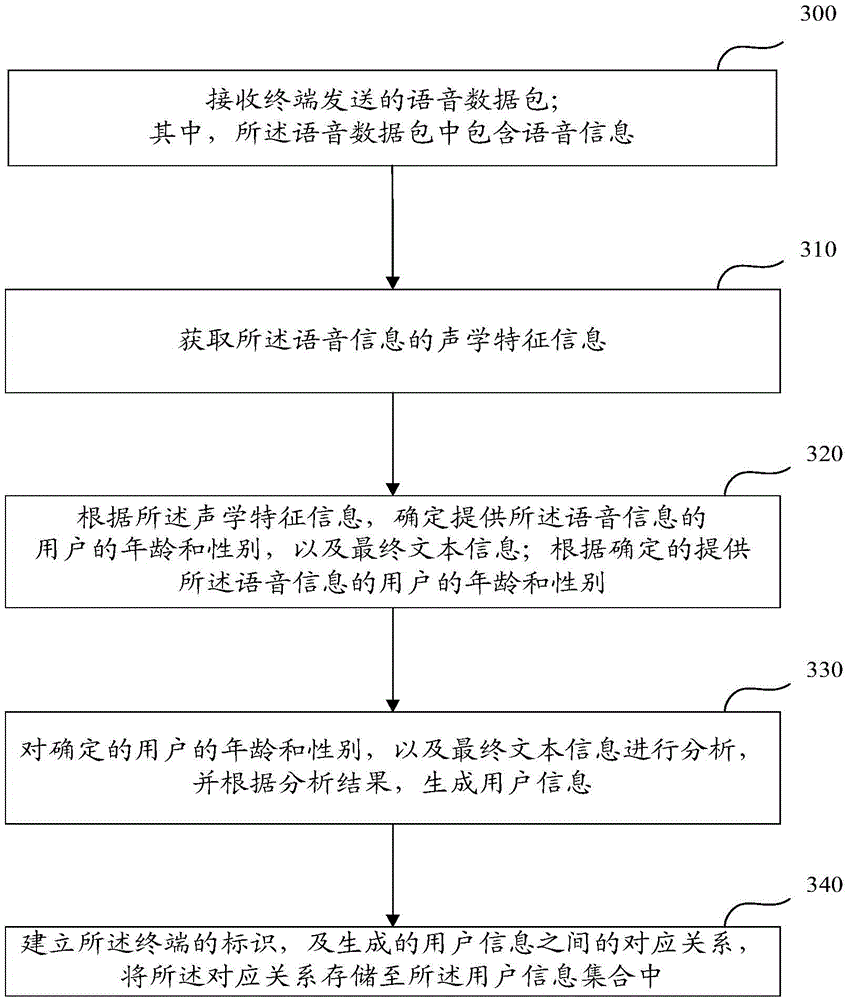
[0059] refer to image 3 As shown, in the embodiment of the present invention, the generation process of the user information contained in the database of the server includes:
[0060] Step 300: Receive a voice data packet sent by the terminal; wherein, the voice data packet includes voice information.
[0061] Step 310: Obtain acoustic feature information included in the voice information.
[0062] Step 320: According to the acoustic feature information, determine the age and gender of the user who provided the voice information, and the final text information; according to the determined age and gender of the user who provided the voice information.
[0063] Optionally, the server may also acquire environmental data, such as time and user action range, according to the acoustic feature information.
[0064] Step 330: Analyze the determined age and gender of the user and the final text information, and generate user information according to the analysis result.
[0065] Op...
Embodiment 3
[0068] Based on the above technical solutions, see Figure 4 As shown, in the embodiment of the present invention, a memory space cleaning device is provided, including a receiving unit 40, an acoustic feature information acquiring unit 41, an initial text information acquiring unit 42, a final text information generating unit 43, and a sending unit 44, wherein:
[0069] The receiving unit 40 is configured to receive a voice data packet sent by the terminal; wherein, the voice data packet contains voice information;
[0070] Acoustic feature information acquisition unit 41, configured to acquire acoustic feature information of the voice information; wherein, the acoustic feature information is information representing sound characteristics of the voice information;
[0071] An initial text information acquisition unit 42, configured to sequentially input the acoustic feature information into a preset acoustic model and a language model, and acquire initial text information obt...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More