

Mongolian large vocabulary continuous speech recognition method
A speech recognition and large vocabulary technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of sparse language model data, long speech recognition time, and the inability of speech recognition system to contain large-scale Mongolian words, etc. The effect of improving the amount of calculation and system performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
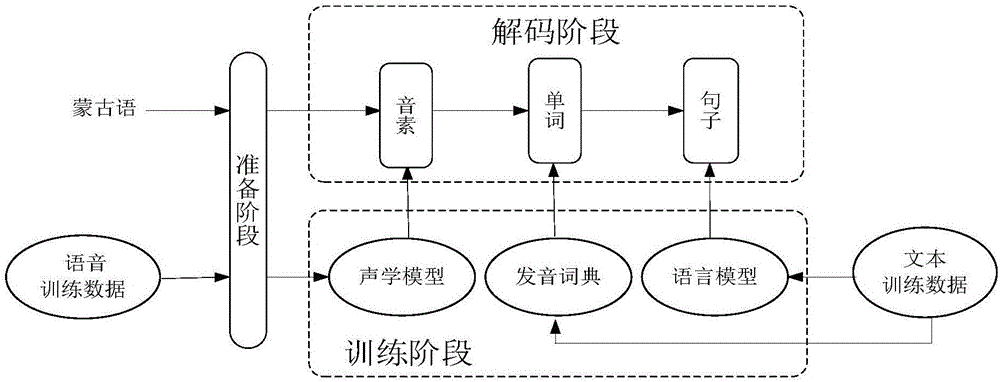
[0033] The principle of Mongolian segmentation recognition:
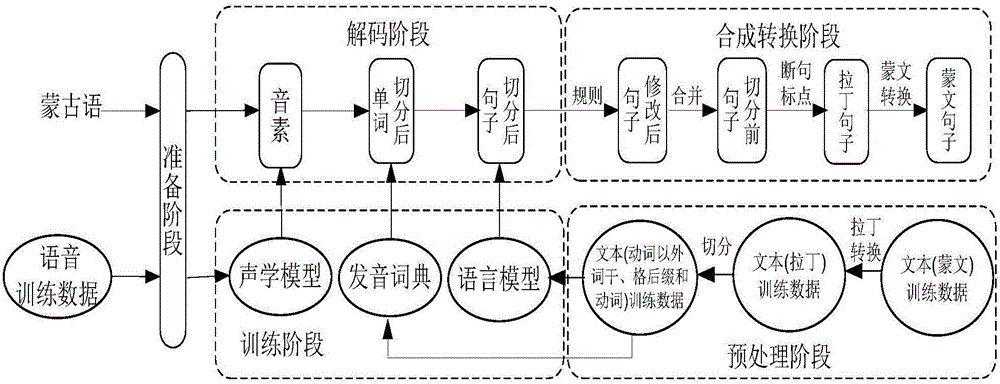
[0034] Mongolian is a typical agglutinative language, and Mongolian words are mainly formed by splicing roots and affixes, such as figure 2 shown. From the combination of roots and affixes, it can be seen that the splicing of roots and word-forming affixes or configurational suffixes has actual semantic modification, while the splicing of subsequent and ending suffixes has only grammatical meaning, and its position is always stored in the composition the end of the word. Ending suffixes do not belong to stem suffixes, which include case suffixes of static words, possessive (owner) suffixes, formal verbs (time, person) suffixes and adverb suffixes. As for the verb suffix, if the verb acts as the predicate of the main clause, it can be considered as an ending suffix, but when the verb is used as a static word (especially when it is followed by a case suffix), it can be considered as a stem suffix. In general, the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More