

Word segmentation method based on MMseg algorithm and pointwise mutual information algorithm
Patent Information
- Authority / Receiving Office
- CN · China
- Patent Type
- Applications(China)
- Current Assignee / Owner
- SUN YAT SEN UNIV
- Publication Date
- 2017-03-22
- Estimated Expiration
- Not applicable · inactive patent
Smart Images
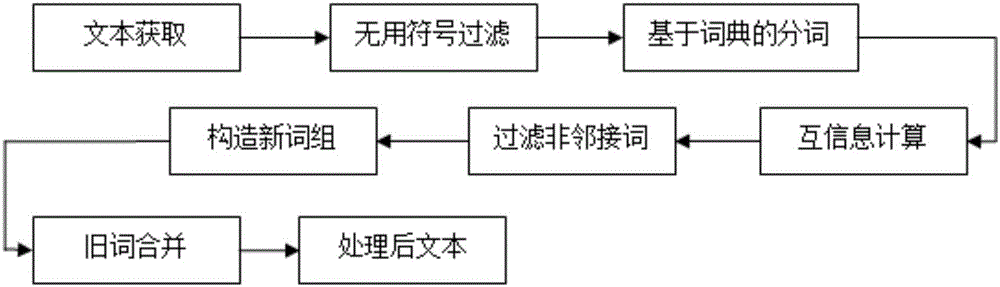
Figure 1 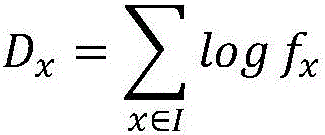
Figure 2 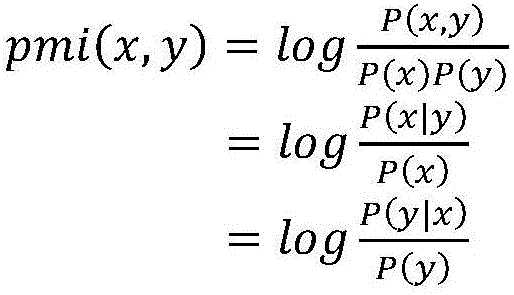
Figure 3
Abstract
Description
technical field
[0001] The present invention relates to the field of Chinese word segmentation, and more specifically, relates to a word segmentation method based on MMseg algorithm and point-by-point mutual information algorithm. Background technique
[0002] my country's research on natural language processing started relatively late, and it only established its own natural language processing model in the 1980s. Later, with the development of computers and the improvement of users' own needs, the domestic emphasis on natural language has greatly increased. The number of research institutions has increased and the research team has grown. The research team combined the characteristics of Chinese texts while drawing on foreign achievements, and proposed a new theoretical model to improve the level of research on Chinese understanding.
[0003] There are spaces between words in English word segmentation, but in Chinese text, characters between sentences are connected togethe...