Method for automatically writing specific manuscript
A specific and manuscript technology, applied in the field of automatic writing of specific manuscripts, can solve the problems of not being able to intelligently learn parameter characteristics and not being directly applicable
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
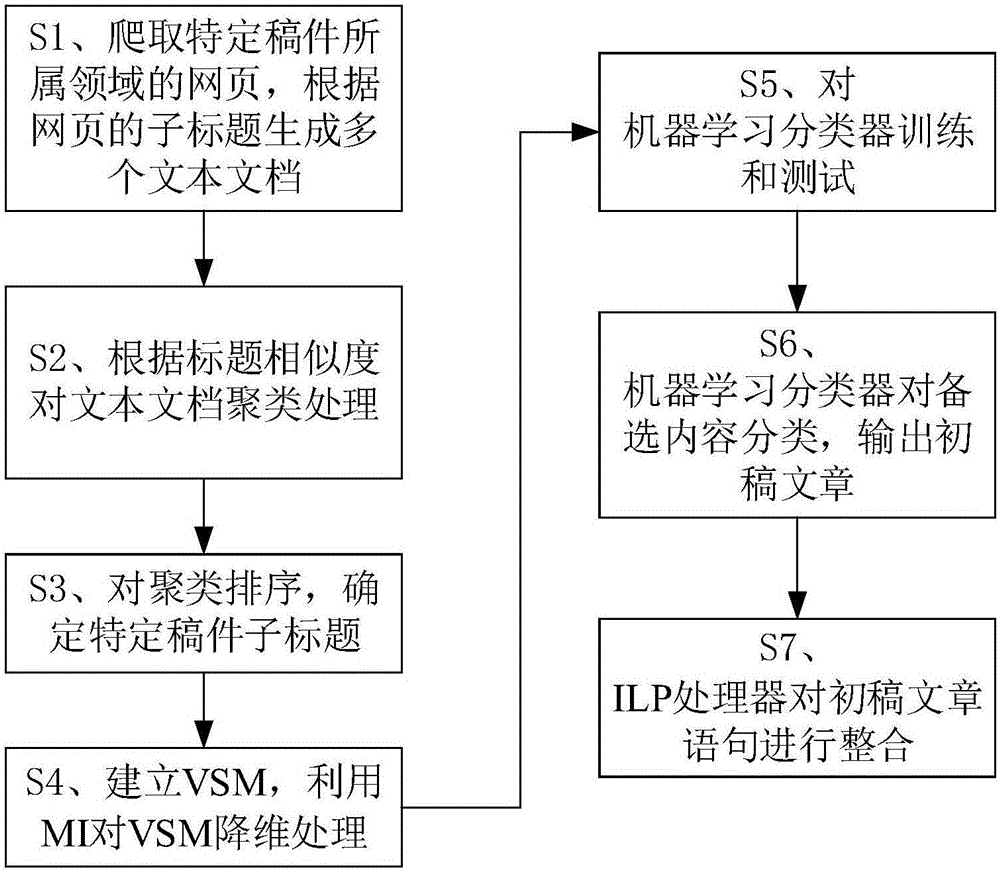
[0051] In order to make the purpose, technical solution and advantages of the present invention clearer, the technical solution of the present invention will be described in detail below. Apparently, the described embodiments are only some of the embodiments of the present invention, but not all of them. Based on the embodiments of the present invention, all other implementations obtained by persons of ordinary skill in the art without making creative efforts fall within the protection scope of the present invention.
[0052] Glossary:
[0053]TF-IDF, the abbreviation of Term Frequency-Inverse Document Frequency, is called Term Frequency-Inverse Document Frequency in Chinese. It is a commonly used weighting for information retrieval and data mining. The main idea of TF-IDF is: if a word or phrase appears in an article with a high frequency TF and rarely appears in other articles, it is considered This word or phrase has a good category discrimination ability.
[0054] VSM...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



