Information extraction method and apparatus for PDF file
An information extraction and document technology, applied in the field of information processing, can solve the problems of effective extraction and inability to finely analyze chart information, and achieve the effect of simplifying the time for analyzing the content of the research report.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0073] The following will clearly and completely describe the technical solutions in the embodiments of the present invention in conjunction with the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some of the embodiments of the present invention, not all of them. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
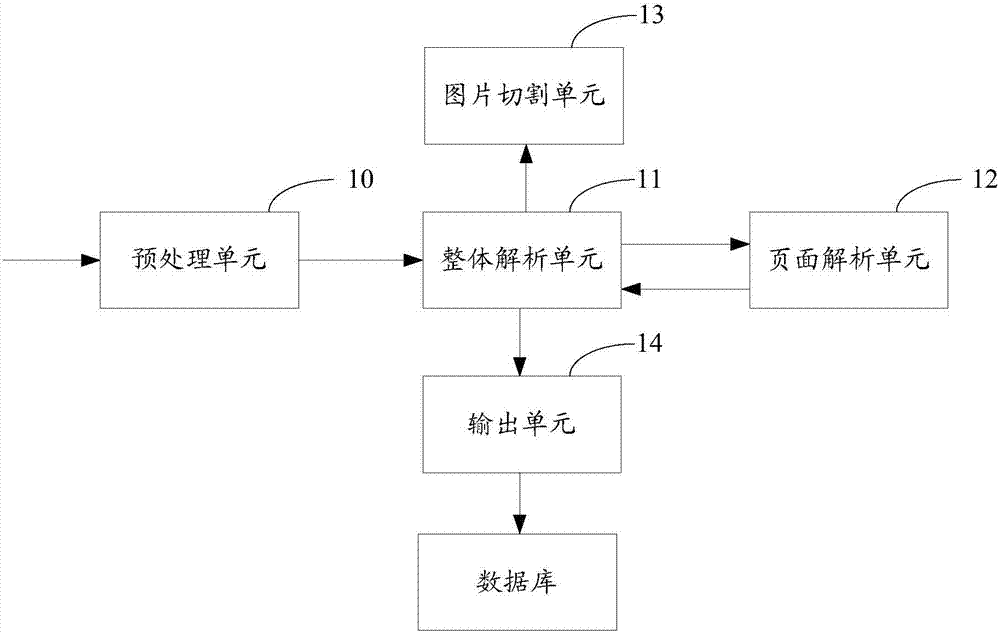
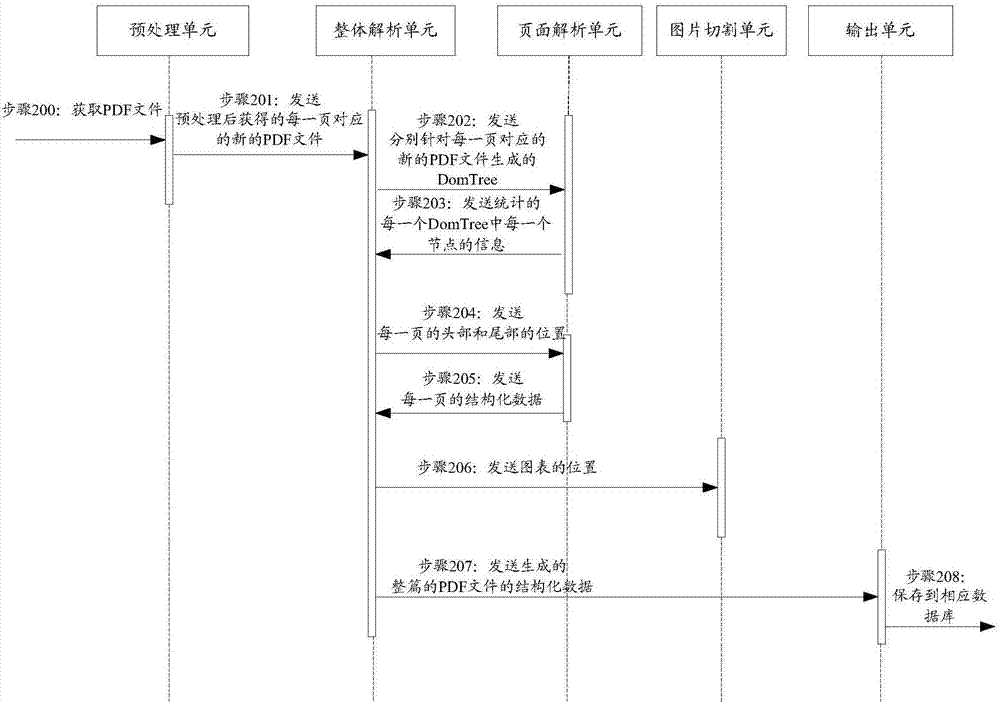
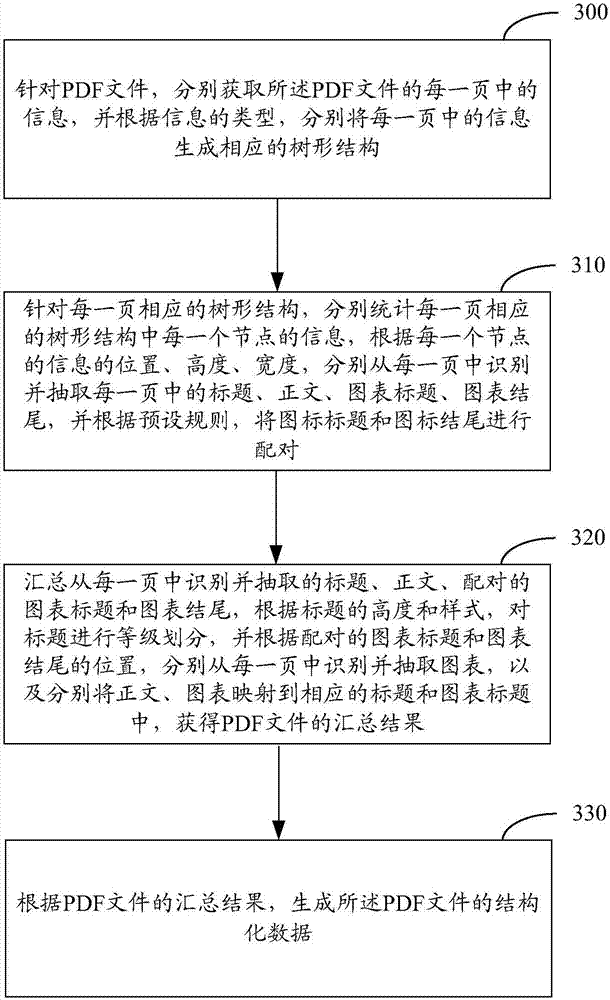
[0074] In order to solve the problem in the prior art that the information content of the PDF file cannot be finely analyzed and the chart information cannot be effectively extracted, in the embodiment of the present invention, for the PDF file, the title, text, picture, and table are identified and extracted (wherein, this In the embodiment of the invention, pictures and tables are collectively referred to as "charts" below), and they are organ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More