

Video caption generation method based on semantic segmentation and multilayer attention frame
A semantic segmentation and attention technology, applied in character and pattern recognition, selective content distribution, instruments, etc., can solve the problems of repeated information extraction, cross-interference of modal information, loss of image structure information, etc., and achieve the goal of improving utilization rate Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

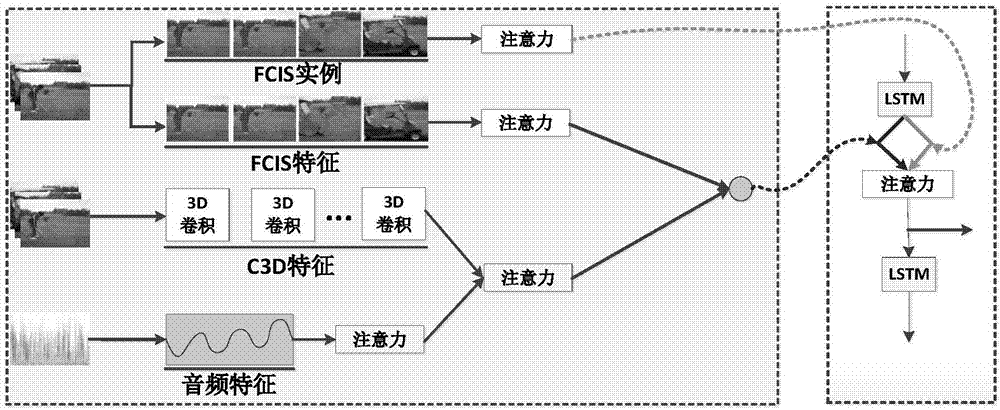
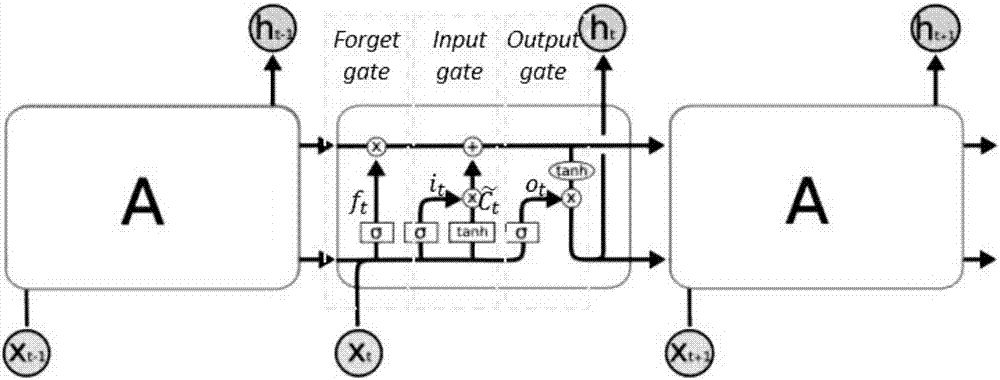
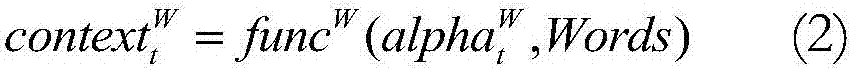
Examples
Embodiment Construction
[0020] Hereinafter, the implementation of the technical solution will be further described in detail with reference to the accompanying drawings.
[0021] It will be understood by those skilled in the art that although the following description deals with many technical details regarding the embodiments of the present invention, it is by way of example only to illustrate the principles of the present invention and is not meant to be limiting. The present invention can be applied to situations other than the technical details exemplified below, as long as they do not depart from the principle and spirit of the present invention.
[0022] In addition, in order to avoid the description of this specification being limited to being redundant, in the description in this specification, some technical details that can be obtained in the prior art materials may be omitted, simplified, modified, etc. It will be understood by persons, and this does not affect the sufficiency of the discl...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More