

Audio visual speech module based on residual network and bidirectional gating recurrent units
A technology of recurrent unit and speech model, which is applied in speech analysis, speech recognition, instruments, etc., and can solve the problem of low recognition accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0022] It should be noted that, in the case of no conflict, the embodiments in the present application and the features in the embodiments can be combined with each other. The present invention will be further described in detail below in conjunction with the drawings and specific embodiments.
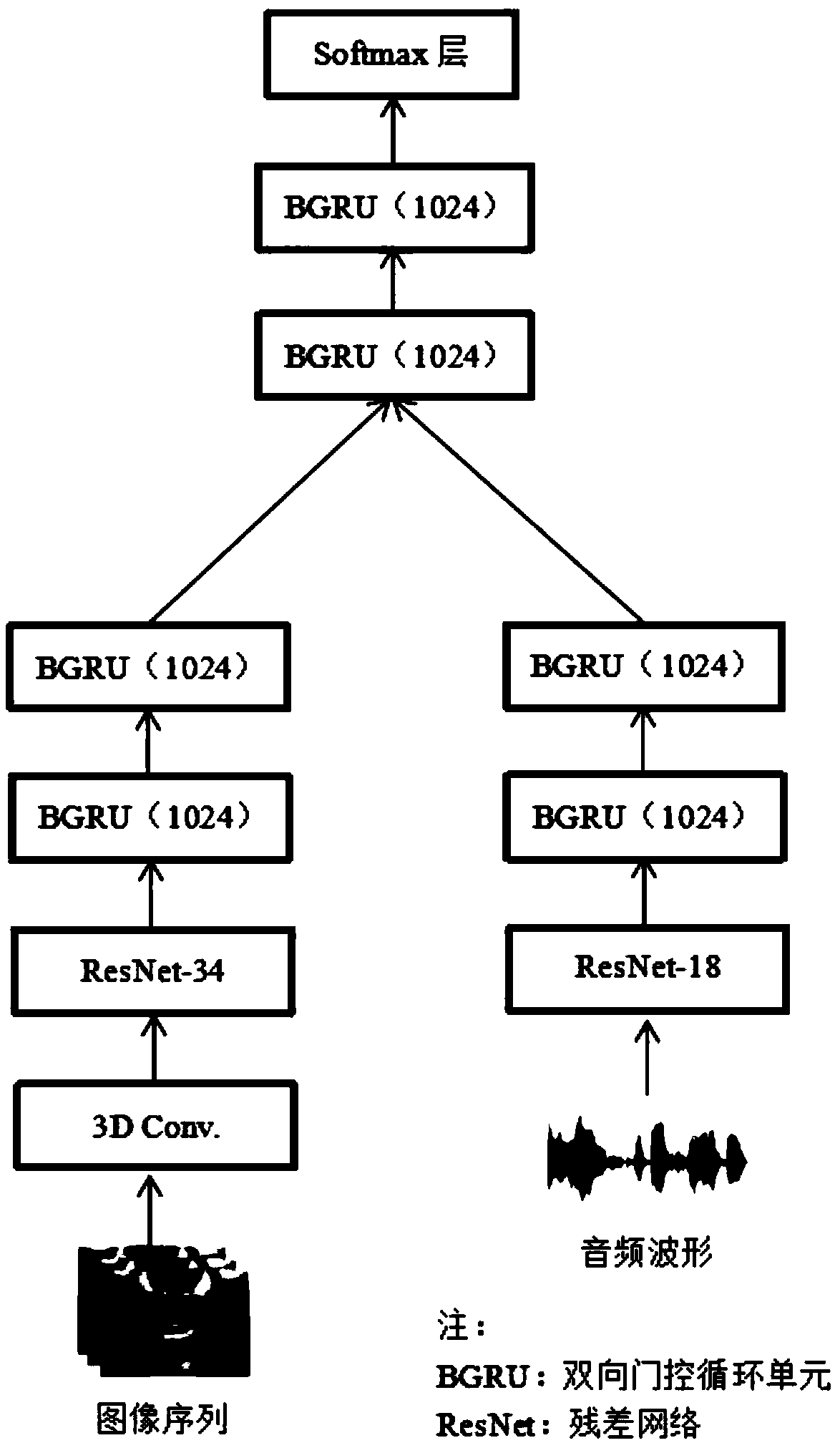
[0023] figure 1 It is a system frame diagram of an audio-visual speech model based on a residual network and a bidirectional gated recurrent unit of the present invention. It mainly includes visual stream, audio stream, classification layer and audio-visual fusion.
[0024] The visual flow is composed of a spatio-temporal convolution with a 34-layer residual network (ResNet-34) and a 2-layer bidirectional gated recurrent unit (BGRU); here is the version of the 34-layer identity map. The main process is: when When the output of each step becomes a single-dimensional tensor, the residual network will gradually reduce the space-time dimension; finally, the output of the 34-layer residual...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More