Method and apparatus for voice recognition, electronic device, and computer readable storage medium
A speech recognition and computer technology, applied in speech recognition, speech analysis, instruments, etc., can solve problems such as poor user experience, false triggering, and high processing pressure on keyword detection devices
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
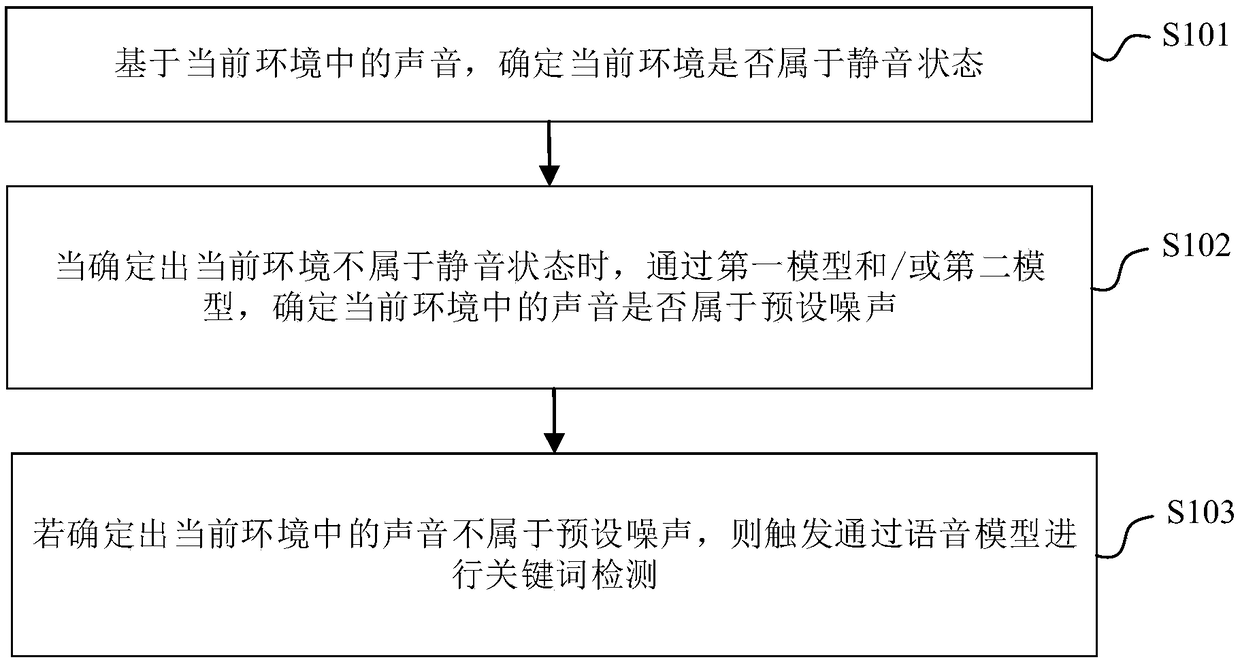
[0035] The embodiment of the present invention provides a method for speech recognition, such as figure 1 As shown, the method includes:
[0036] Step S101 , based on the sound in the current environment, determine whether the current environment is in a silent state.
[0037] The embodiment of the present invention may be executed by a terminal device, or may be executed by a server. It is not limited in the embodiment of the present invention.
[0038] For the embodiment of the present invention, the sound in the current environment may be monitored in real time, or at preset intervals, to determine whether the current environment is in a silent state.
[0039] Step S102, when it is determined that the current environment does not belong to the silent state, determine whether the sound in the current environment belongs to preset noise through the first model and / or the second model.
[0040] For the embodiment of the present invention, the first model may be the SPN mode...
Embodiment 2
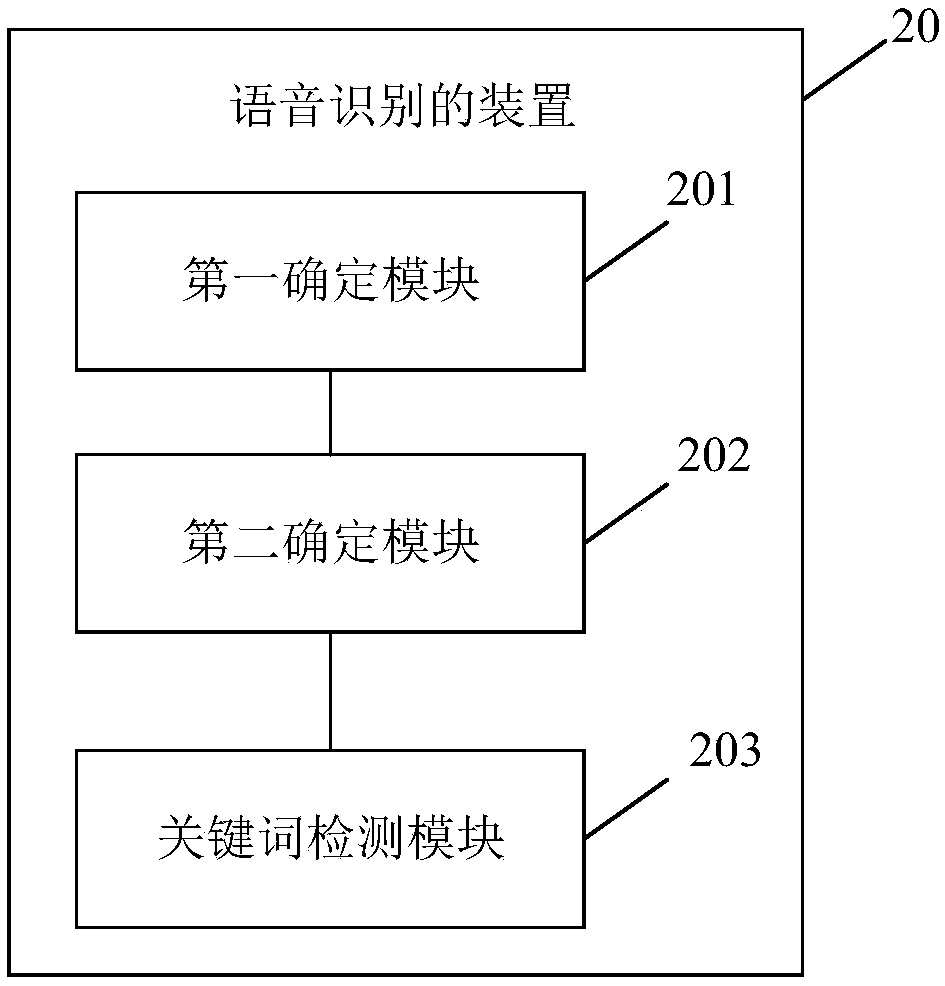
[0047] The embodiment of the present invention provides another possible implementation manner. On the basis of the first embodiment, the method shown in the second embodiment is also included, wherein,
[0048] In step S102, through the first model and / or the second model, it is determined whether the sound in the current environment belongs to the preset noise, and the step SA (not marked in the figure) is also included before, wherein,
[0049] Step SA, creating and training the first model and / or the second model.
[0050] Wherein, the first model is used to determine whether the sound in the current environment belongs to the noise generated by humans, and the second model is used to determine whether the sound in the current environment belongs to the noise not generated by humans.
[0051] For the embodiment of the present invention, the first model and / or the second model can be created in the existing garbage model; the first model parallel to the garbage model and / or...
Embodiment 3
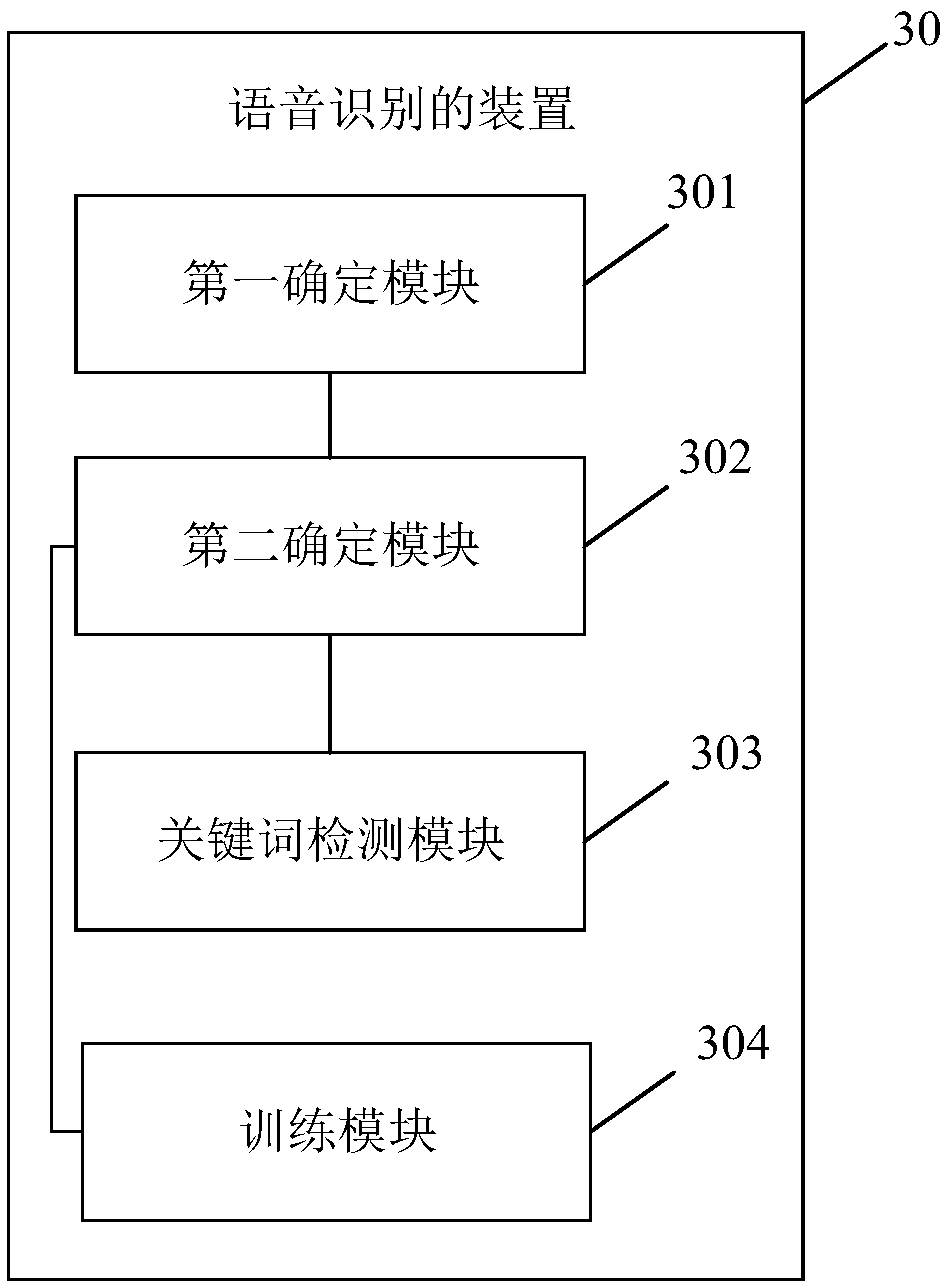
[0062] Another possible implementation of the embodiment of the present invention further includes the operations shown in the third embodiment on the basis of the first embodiment, wherein,
[0063] Step S101 includes step S1011 (not marked in the figure), step S1012 (not marked in the figure) and step S1013 (not marked in the figure), wherein,
[0064] Step S1011. Determine whether the decibel corresponding to the sound in the current environment is greater than a preset threshold.
[0065] For the embodiment of the present invention, an application scenario corresponding to the current environment is determined, and a corresponding preset threshold is determined based on the application scenario corresponding to the current environment. In the embodiment of the present invention, different application scenarios may correspond to different preset thresholds, or different application scenarios may correspond to the same preset threshold. It is not limited in the embodiment o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com