A method and system for improving the efficiency of a big data comprehensive inquiry engine based on Hadoop
A query engine and data query technology, applied in the field of search engines, can solve the problems that the advantages cannot be integrated and applied, and achieve the effect of improving the efficiency of big data query, reducing business code refactoring, and reducing the impact of repulsion
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

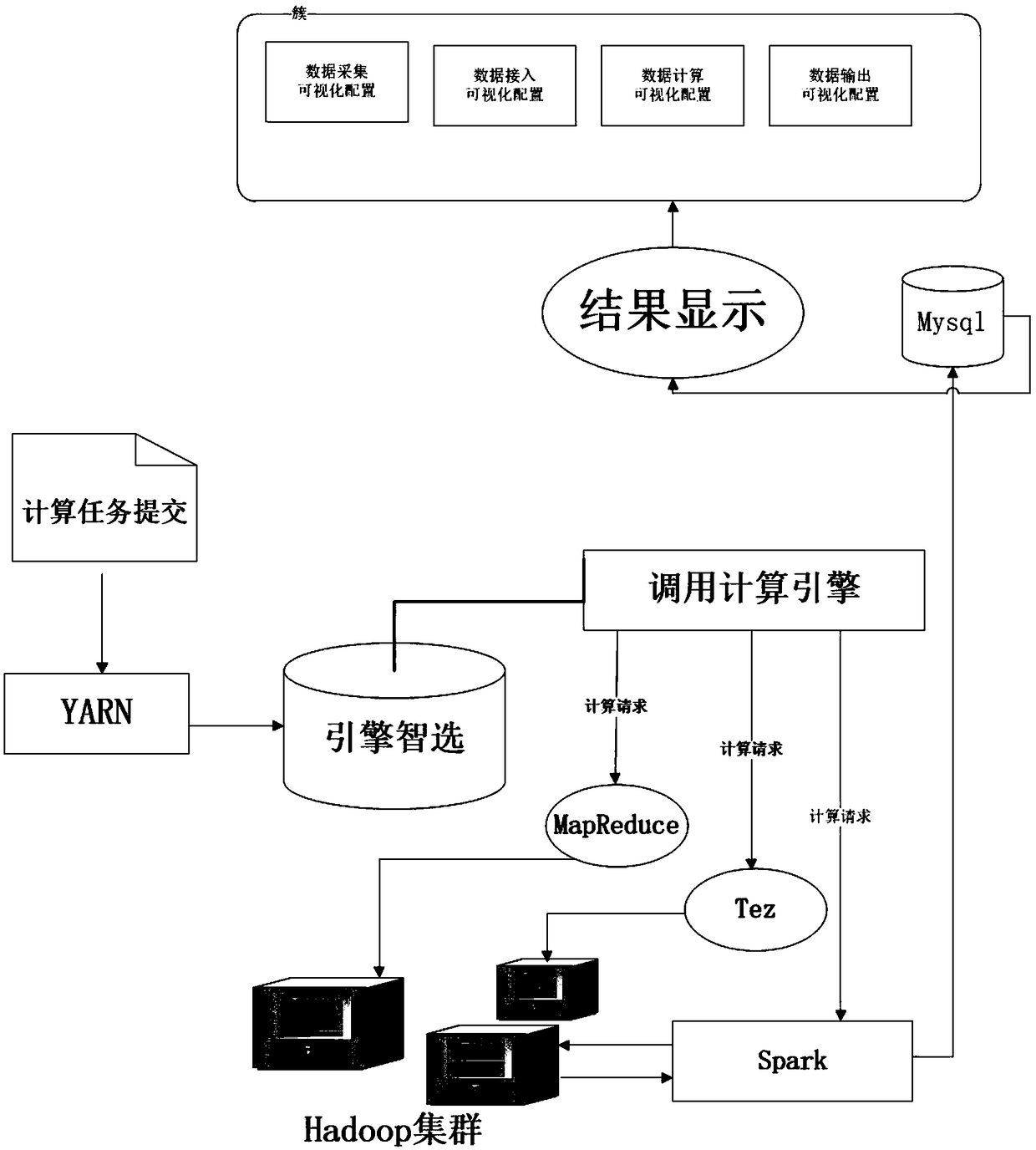
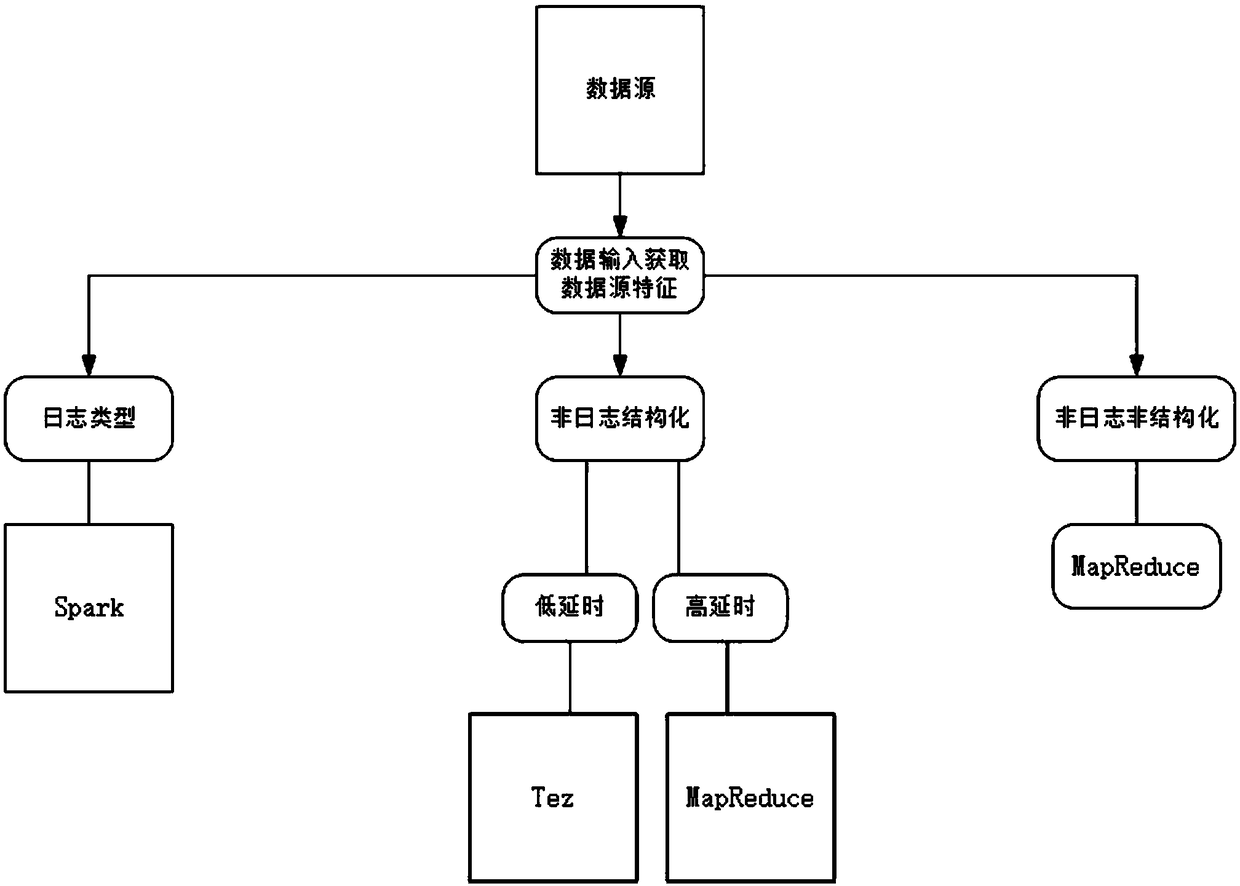
Examples
Embodiment example
[0042]First, prepare 14 centos 6.5 machines, configured as 8-core 32G 4T hard drives, each machine must first check the mapping files of all nodes in the Linux system, and comment out 127.0.0.1 and ::1 and add under it: 127.0.0.1localhost, HDP resource (uploaded to the internal cloud resource machine, the default is the machine where the ambari-server is located).
[0043] Because there is a single point of failure (SPOF) in the NameNode in the HDFS cluster, for a cluster with only one NameNode, if the NameNode machine has an unexpected downtime, the entire cluster will be unavailable until the NameNode is restarted. The HA function of HDFS solves the above problem by configuring Active / Standby two NameNodes to implement hot backup of NameNode in the cluster. If Active NN downtime occurs, it will switch to Standby to make NN service uninterrupted; HDFS HA relies on zookeeper, so Need to edit and configure zookeeper and modify hadoop configuration.
[0044] The Hadoop core-s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More