

A decision tree generation method based on an ID3 algorithm
A decision tree and algorithm technology, applied in computing, computer parts, instruments, etc., can solve problems to be further analyzed and discussed, and achieve the effect of reasonable feature selection and avoiding overfitting.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
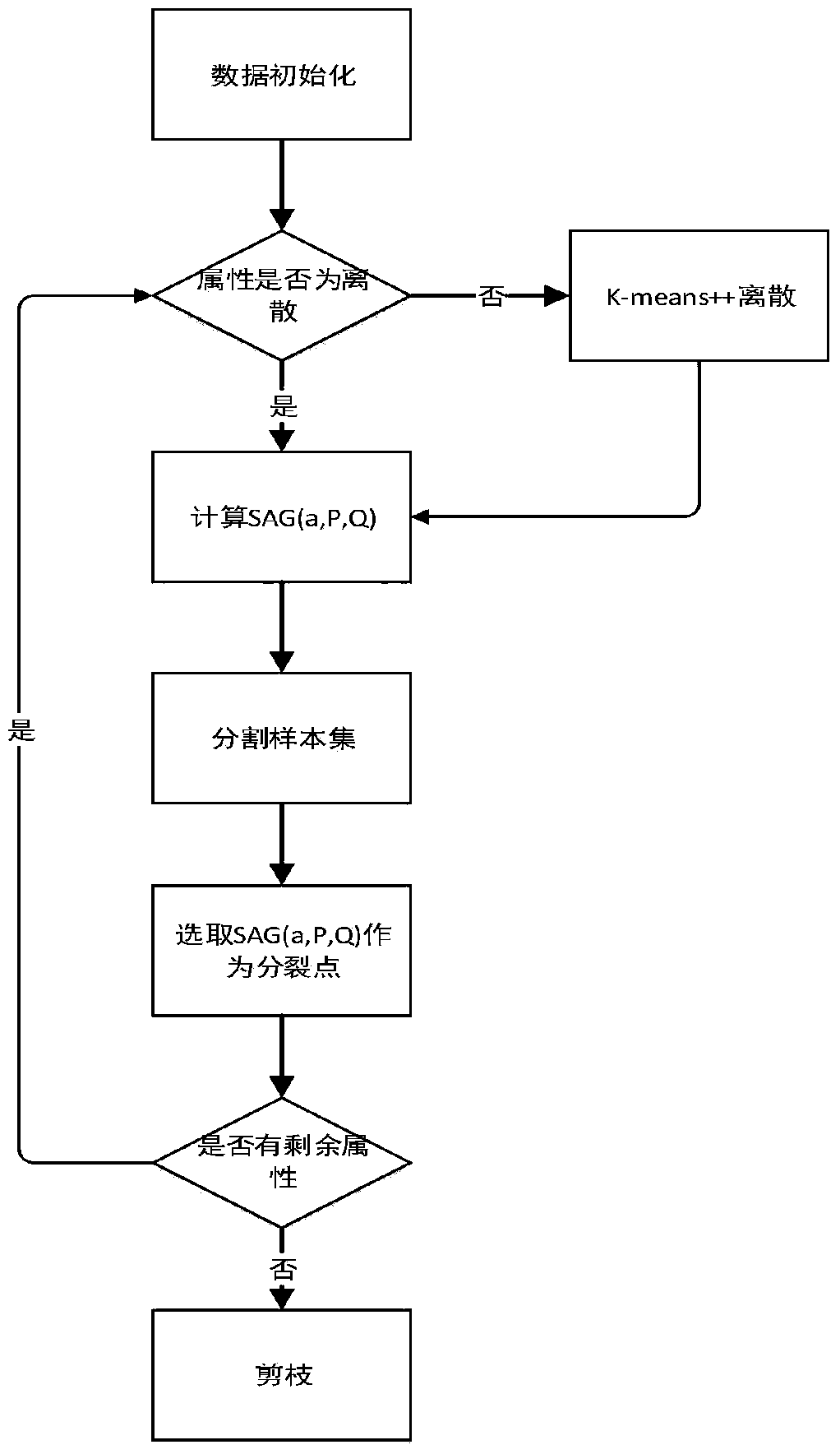
[0014] The basic idea of the present invention is: utilize K-means++ algorithm to discretize the continuous attribute values in the data set, then calculate the importance SGA (a, P, A) of each conditional attribute, and select the attribute with great importance as the split point. Iterate until all condition attributes are used as split nodes. Finally, it is pruned into a decision tree.
[0015] As shown in Figure (1), the specific steps are as follows:
[0016] 1) Data initialization, counting the number of samples in the training set, assuming that the training set D has K classes in total, and counting the number of samples in D1...Dk.
[0017] 2) Determine whether the attribute is discrete. If it is discrete, go to step 3. Otherwise, determine the number of values after discretization, apply the K-means++ algorithm to discretize, and replace the original continuous values with discrete values.
[0018] 3) Calculate the importance of active conditional attribu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More