An image denoising neural network training architecture and a method of training the image denoising neural network
A neural network training, neural network technology, applied in the field of image denoising neural network architecture and training, can solve the problem of not considering noise variance stabilization and so on
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Method used
Image

Examples
Embodiment Construction
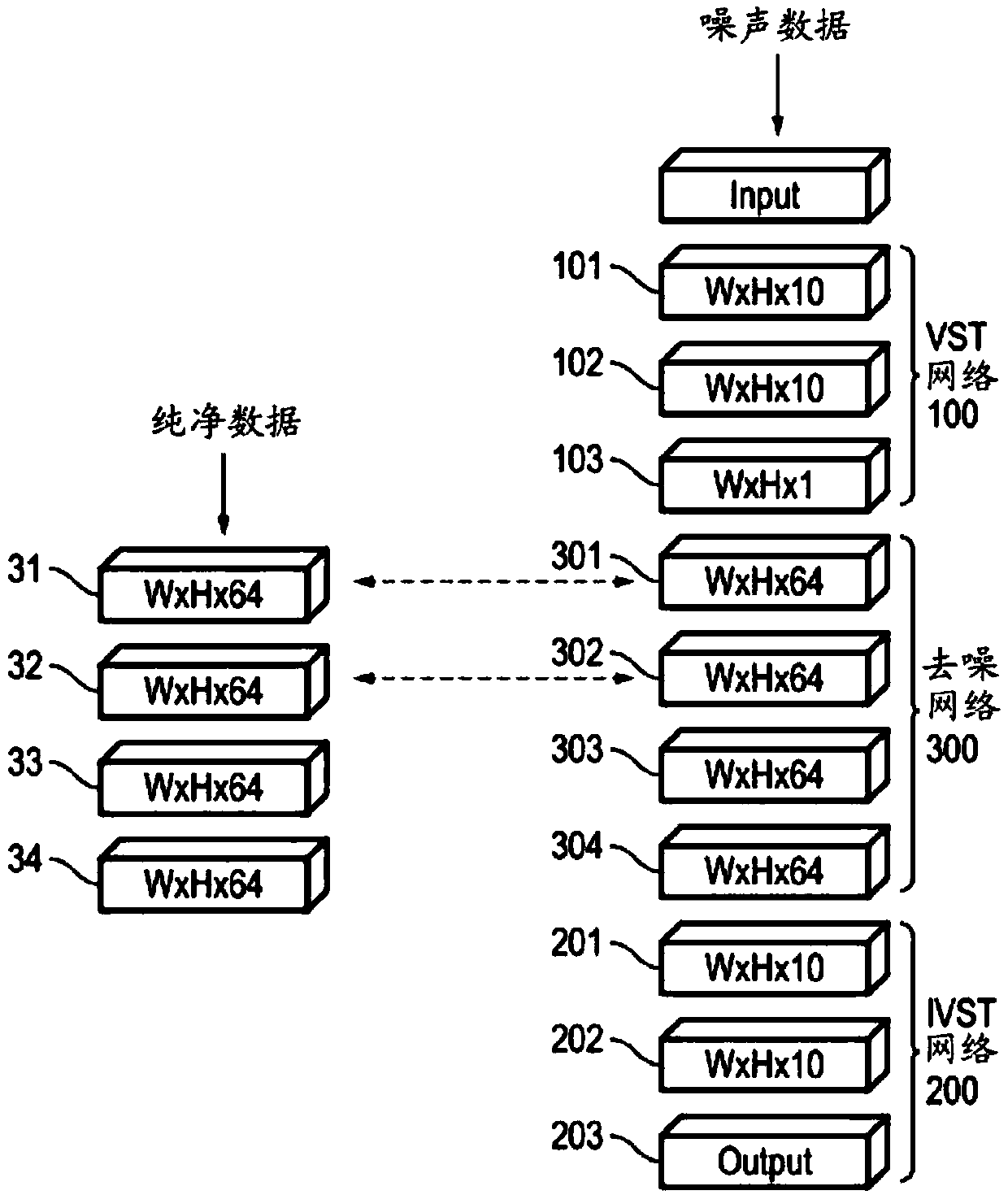
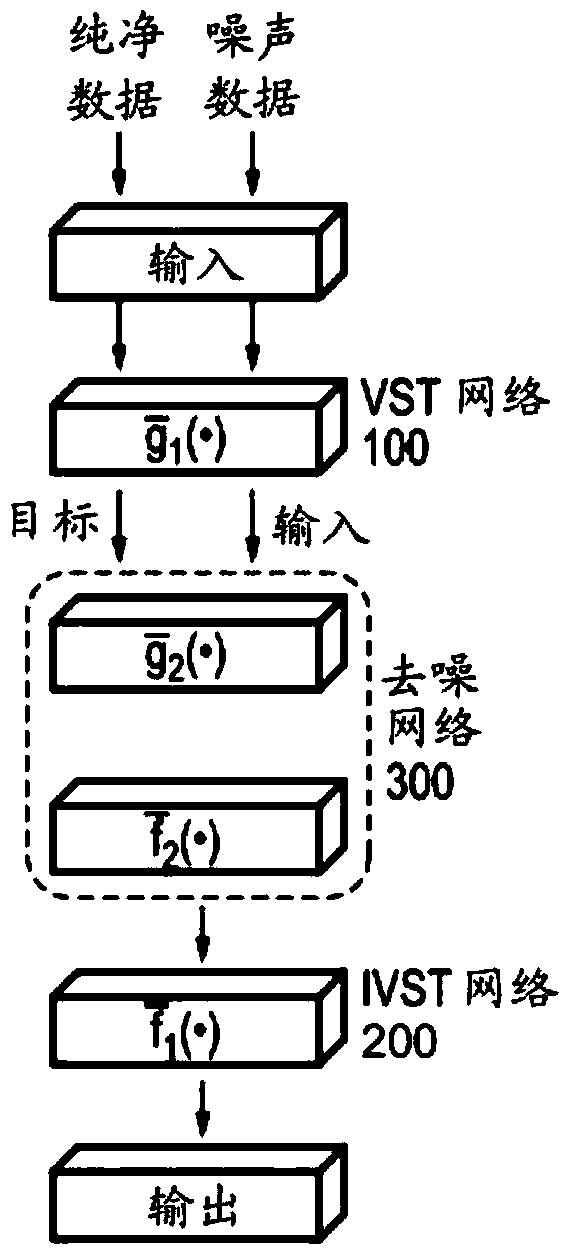
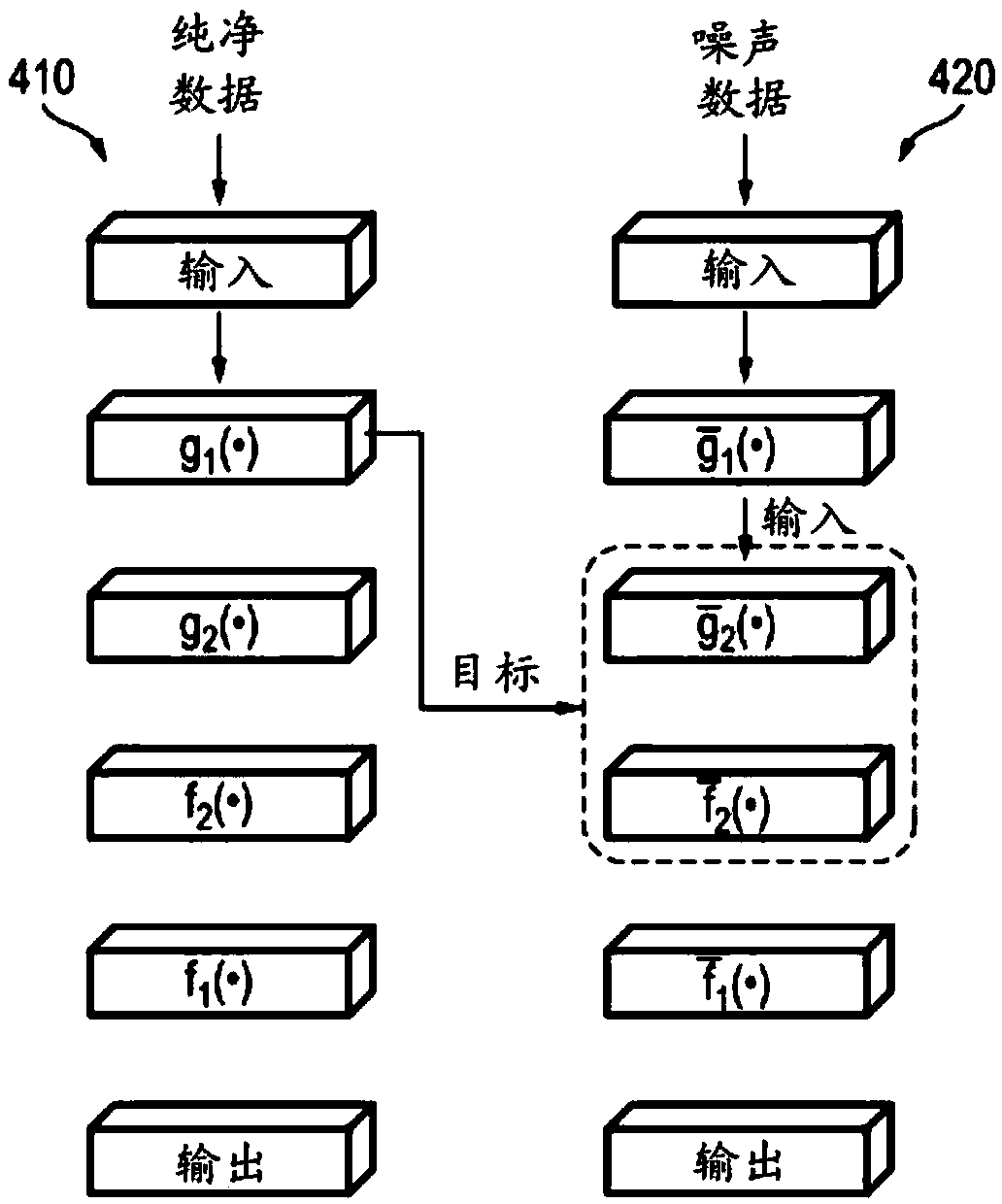
[0040] The present disclosure is directed to various embodiments of image denoising neural network architectures and methods of training image denoising neural networks. In an exemplary embodiment, the image denoising neural network training framework includes an image denoising neural network and a clean data neural network. The image denoising neural network and the clean data neural network can be configured to share information with each other. In some embodiments, the image denoising neural network may include a variance smoothing transformation (VST) network, an inverse variance smoothing transformation (IVST) network, and a denoising network between the VST network and the IVST network. The denoising network may include multiple convolutional autoencoders stacked on top of each other, and the VST network and IVST network may each include multiple filtering layers that together form a convolutional neural network.
[0041] Hereinafter, exemplary embodiments of the prese...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More