training method of a Chinese word segmentation model based on a neural network
A Chinese word segmentation and neural network technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve the problem of model complexity and reduce model word segmentation performance, and achieve the effect of improving word segmentation performance and expanding training corpus
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
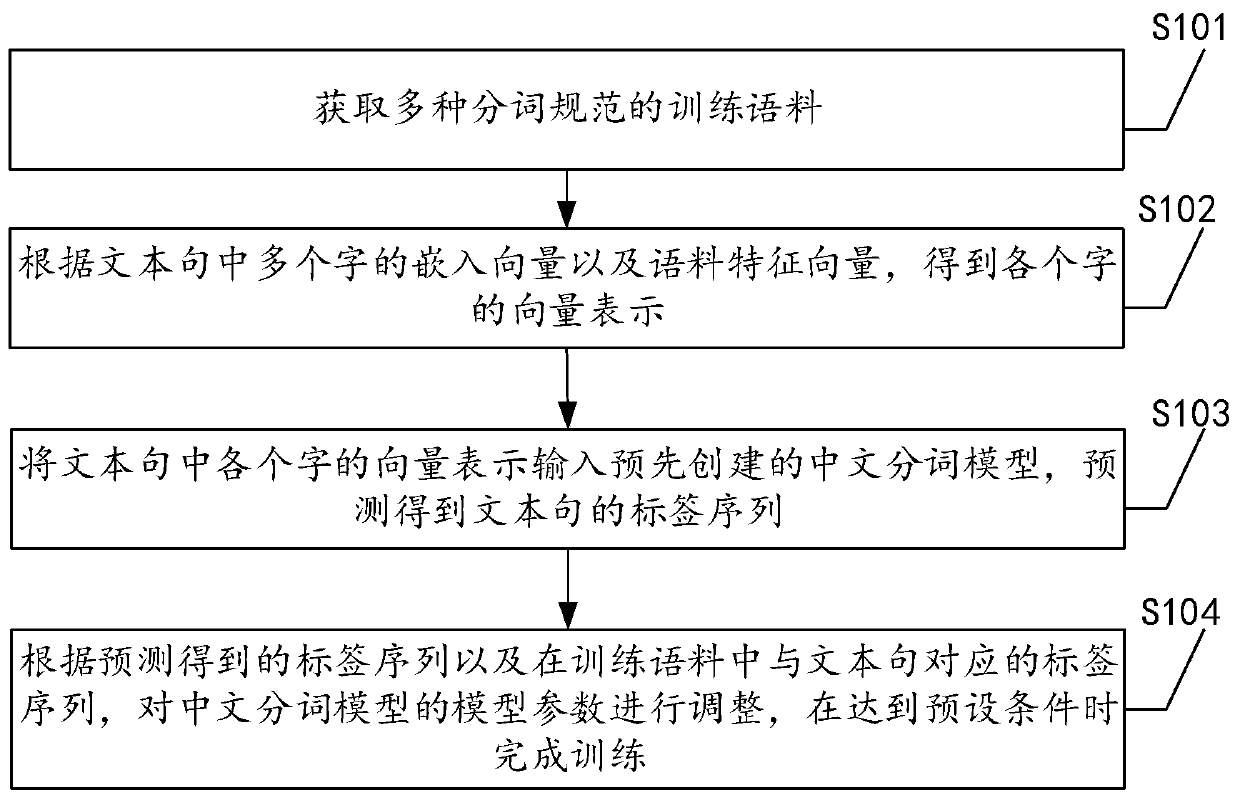
[0052] The first embodiment of the training method of a neural network-based Chinese word segmentation model provided by the present invention is introduced below, see figure 1 , embodiment one includes:
[0053] Step S101: Obtain training corpus of multiple word segmentation specifications.
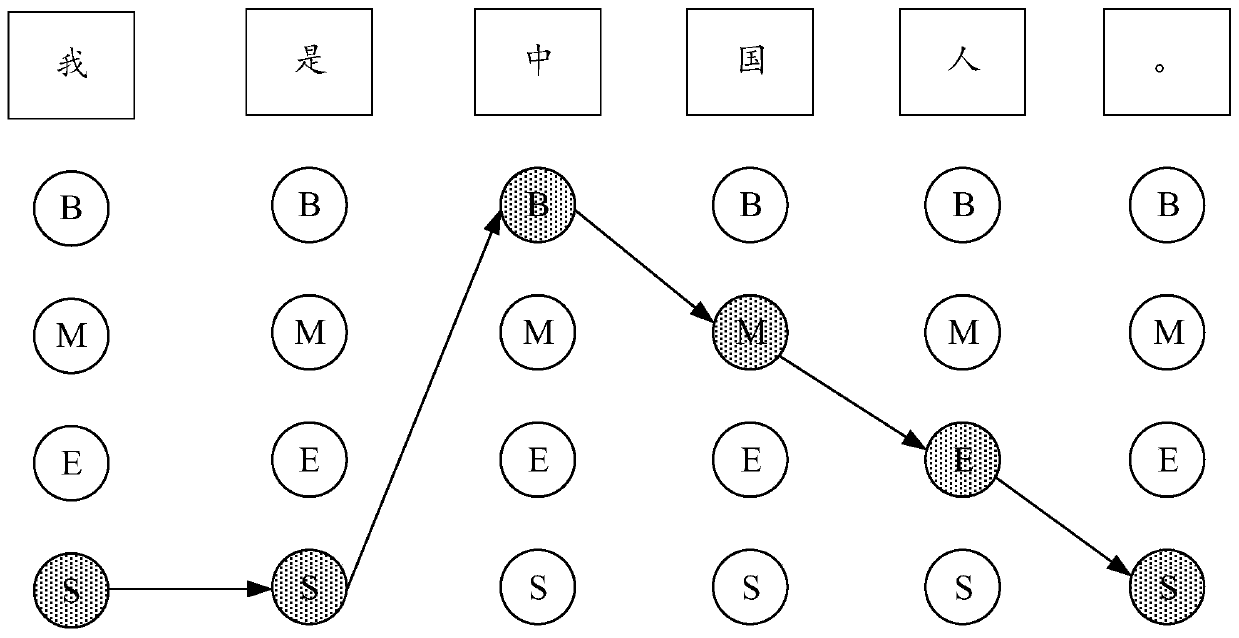
[0054] The above word segmentation specification refers to the rules and basis for word segmentation of text sentences. At present, the known word segmentation specifications include CTB, PKU, MSR, etc. Different word segmentation specifications have different but reasonable word segmentation methods for the same text sentence. As shown in Table 1, according to different word segmentation norms, "all parts of the country" can be segmented into various word sequences such as "all parts of the country", "all parts of the country", and "all / country / each place".
[0055] Table 1
[0056] participle specification
word segmentation result
CTB
Whole|Country|Each|Distri...
Embodiment 2
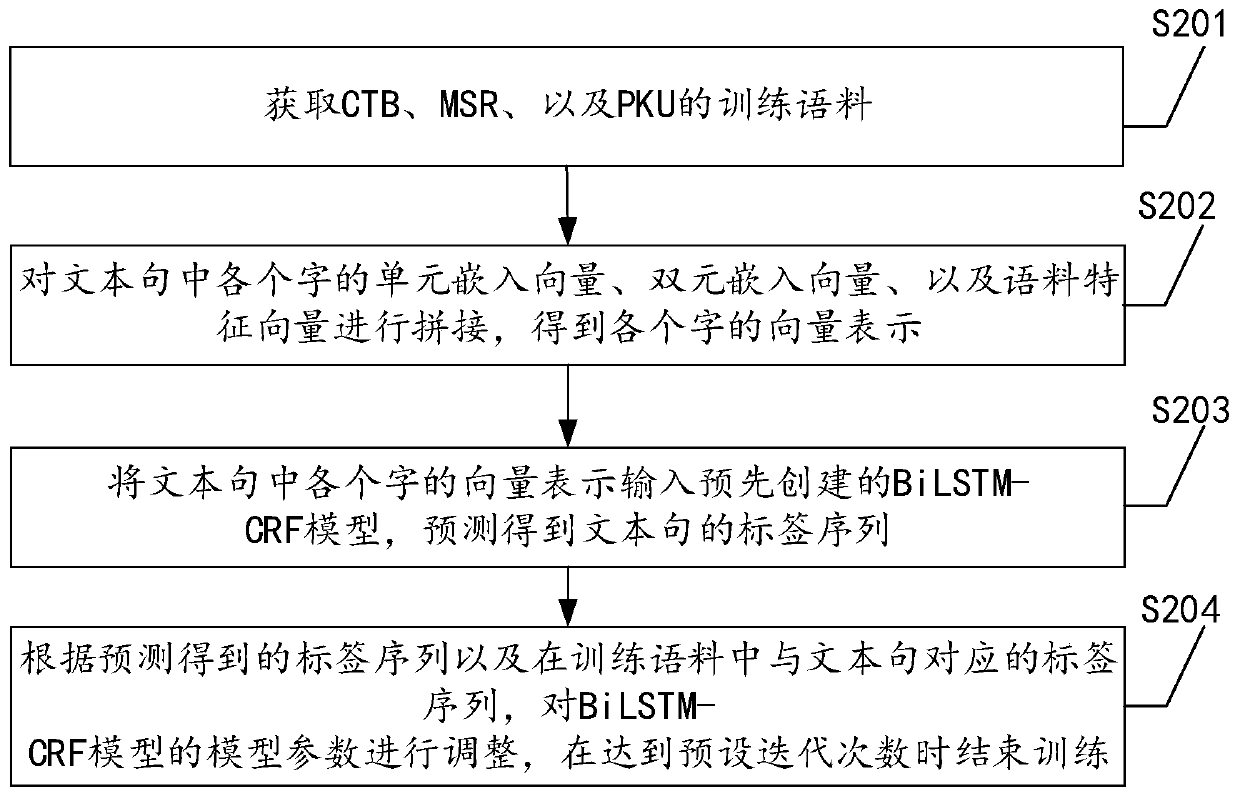
[0071] Embodiment two is carried out as a specific implementation mode. In embodiment two, for the word segmentation specification, three kinds of word segmentation specifications are selected to train the model, which are respectively CTB, MSR, and PKU; in terms of word vector representation, selected The unit embedding vector and the binary embedding vector of the word are used to form the vector representation of the word; on the Chinese word segmentation model, the BiLSTM-CRF model is selected.
[0072] see figure 2 , embodiment two specifically includes:
[0073] Step S201: Obtain training corpus of CTB, MSR, and PKU.
[0074] The above training corpus includes text sentences, and also includes label sequences corresponding to the text sentences. In the full labeling scenario, when the word segmentation specification is uniquely determined, each word and even each punctuation mark of a text sentence has a certain label. Therefore, a text sentence has only one reasonabl...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com