

Systems and methods for neural voice cloning with a few samples
An audio and text technology, applied in the field of computer learning systems, capable of solving complex problems
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

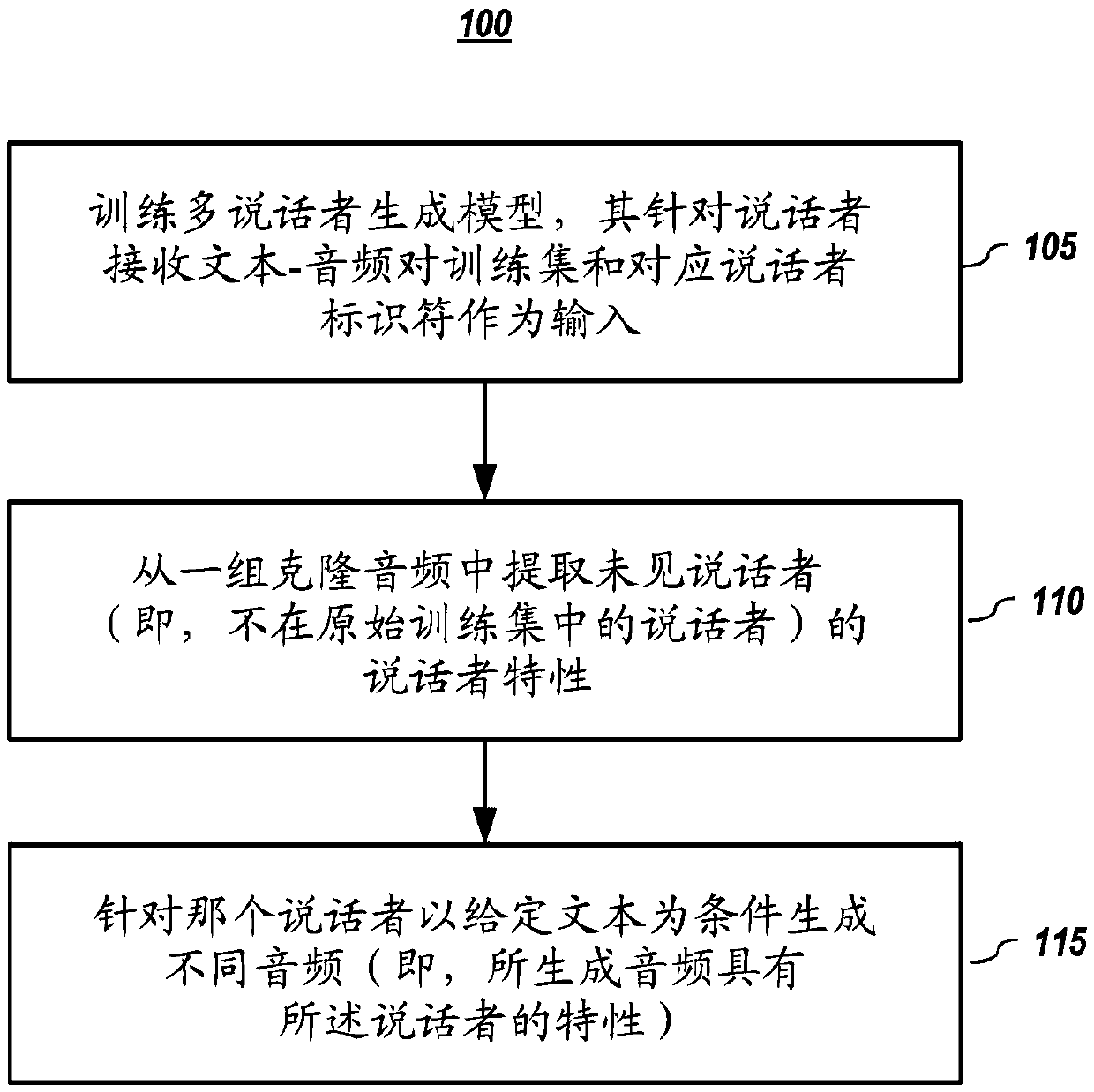
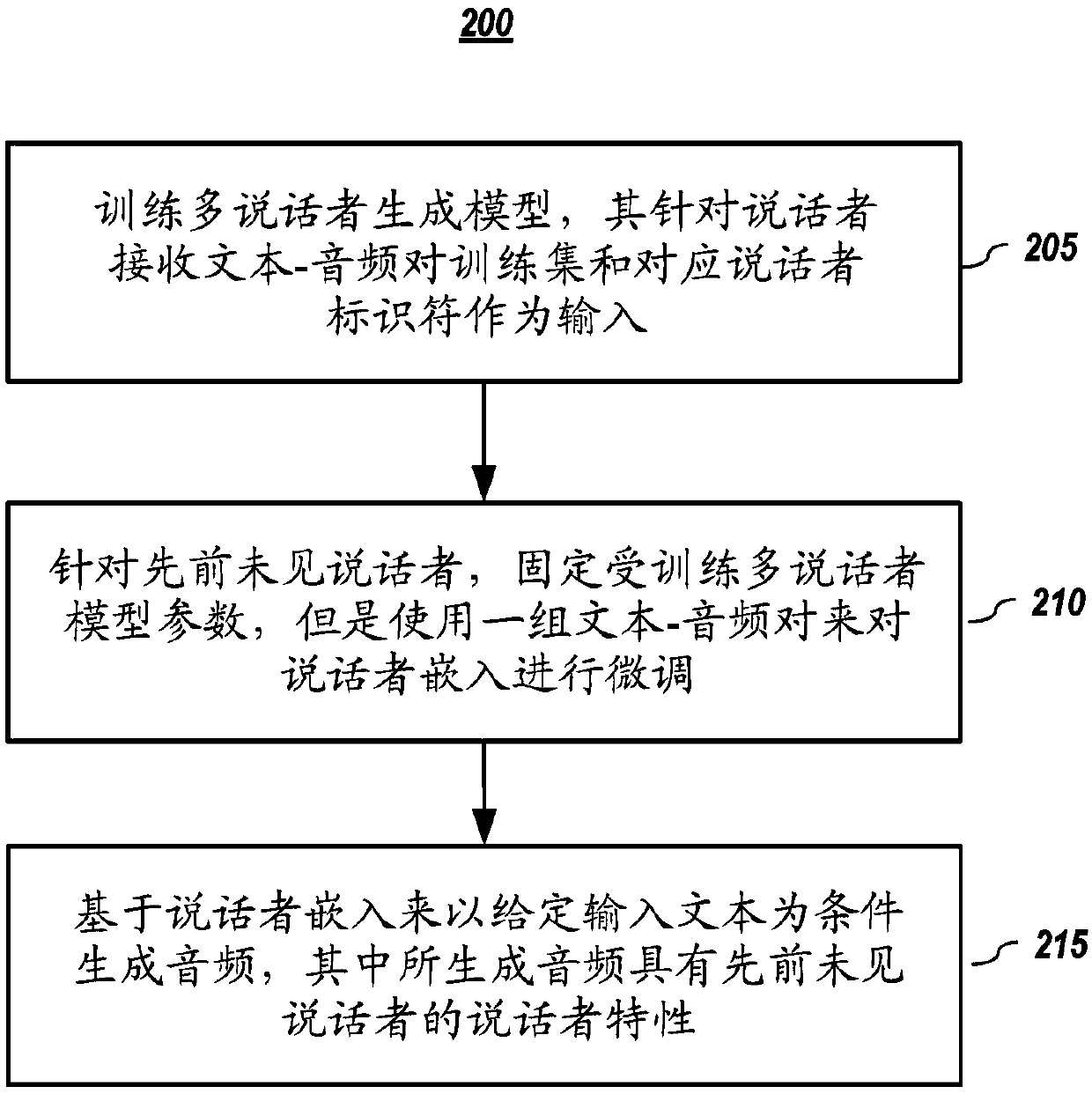
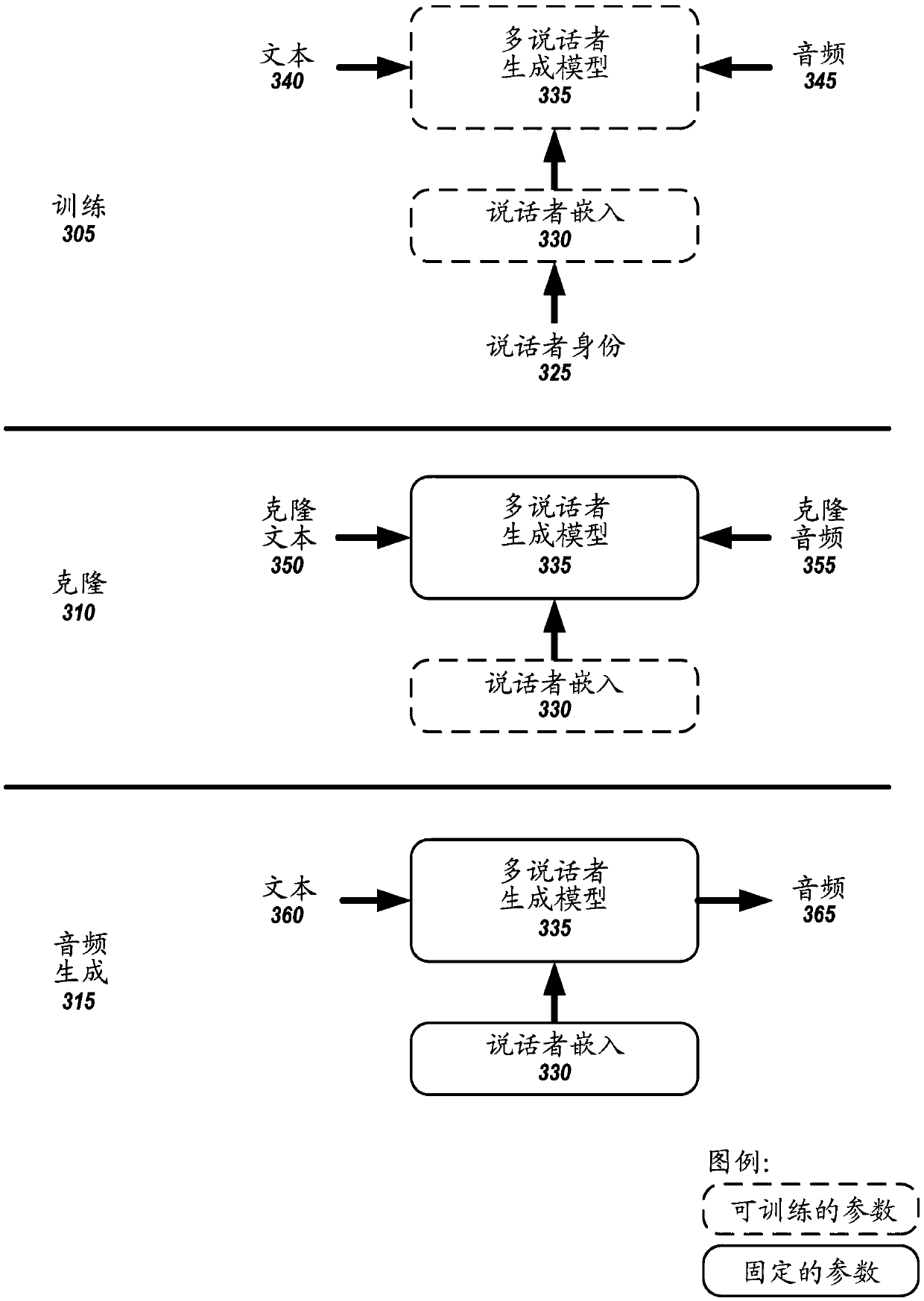
Examples
Embodiment approach
[0114] In one or more implementations, for a speaker encoder A neural network architecture consists of three parts (e.g., Figure 12 One implementation is shown in ):
[0115] (i) Spectral processing: In one or more implementations, a mel spectrogram 1205 for cloning an audio sample is computed and passed to a PreNet (pre-network) 1210, which contains Fully Connected (FC) layer of Exponential Linear Unit (ELU).
[0116] (ii) Temporal processing: In one or more embodiments, several convolutional layers 1220 with gated linear units and residual connections are used to incorporate temporal context. Next, average pooling can be applied 1225 to summarize the entire utterance.
[0117] (iii) Clone Sample Attention: Considering that different cloned audios contain different amounts of speaker information, in one or more implementations, a multi-head self-attention mechanism 1230 can be used to calculate the weights of different audios and obtain aggregated embeddings 1235 .
[0...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More