

Automatic video annotation method based on multi-modal private features
An automatic labeling, multi-modal technology, applied in video data retrieval, neural learning methods, video data clustering/classification, etc., to reduce the time and cost of manual labeling
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
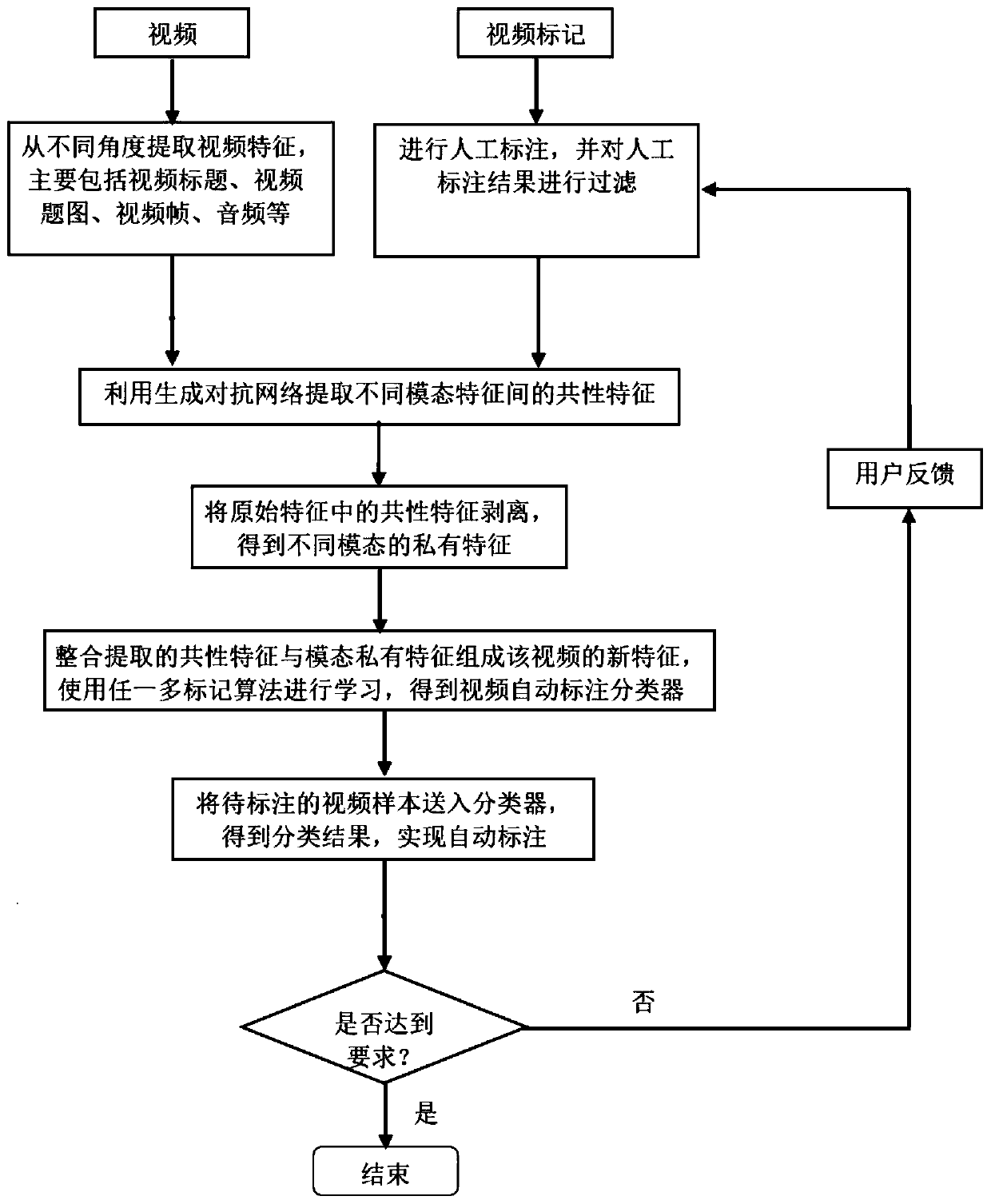
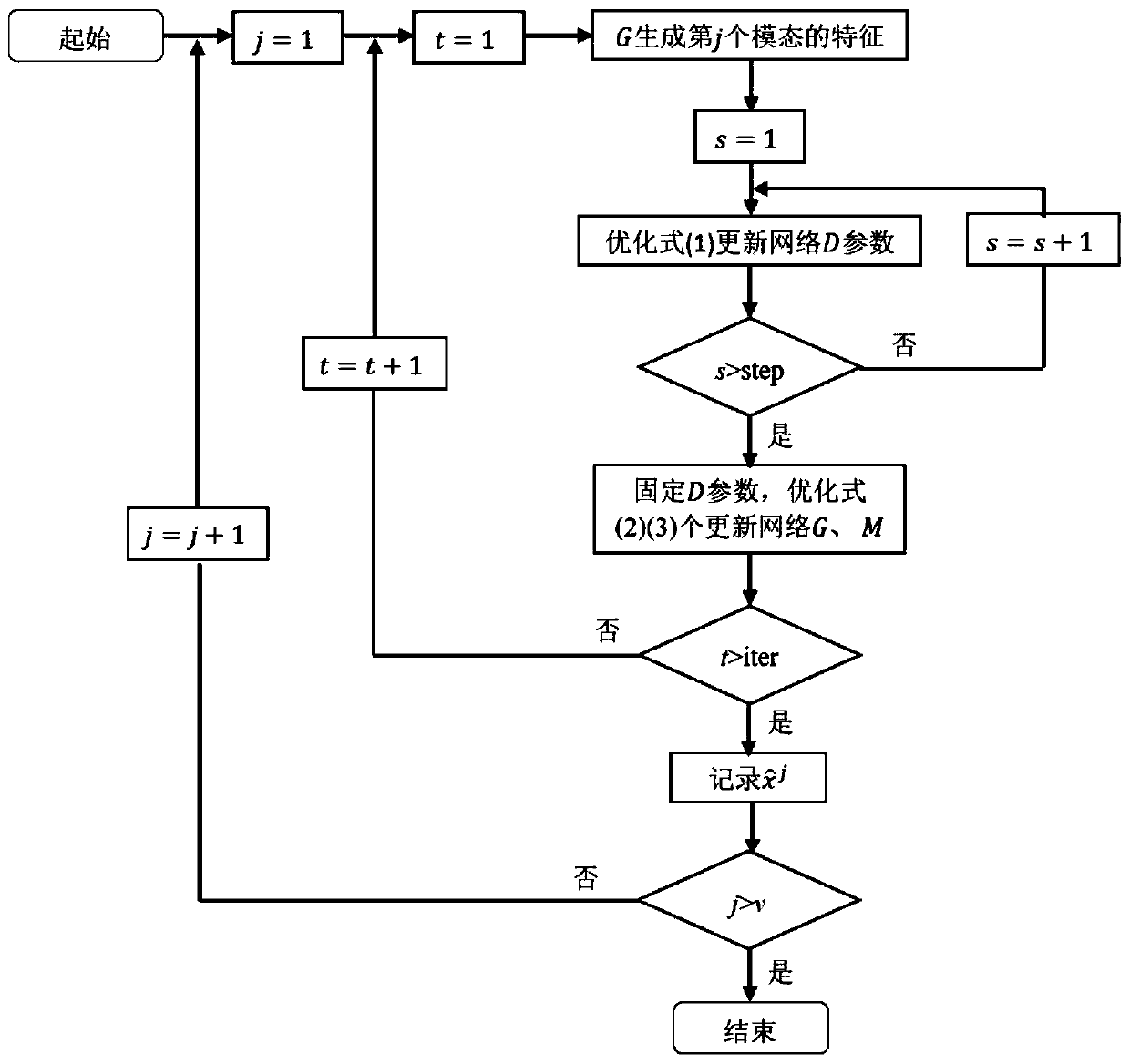
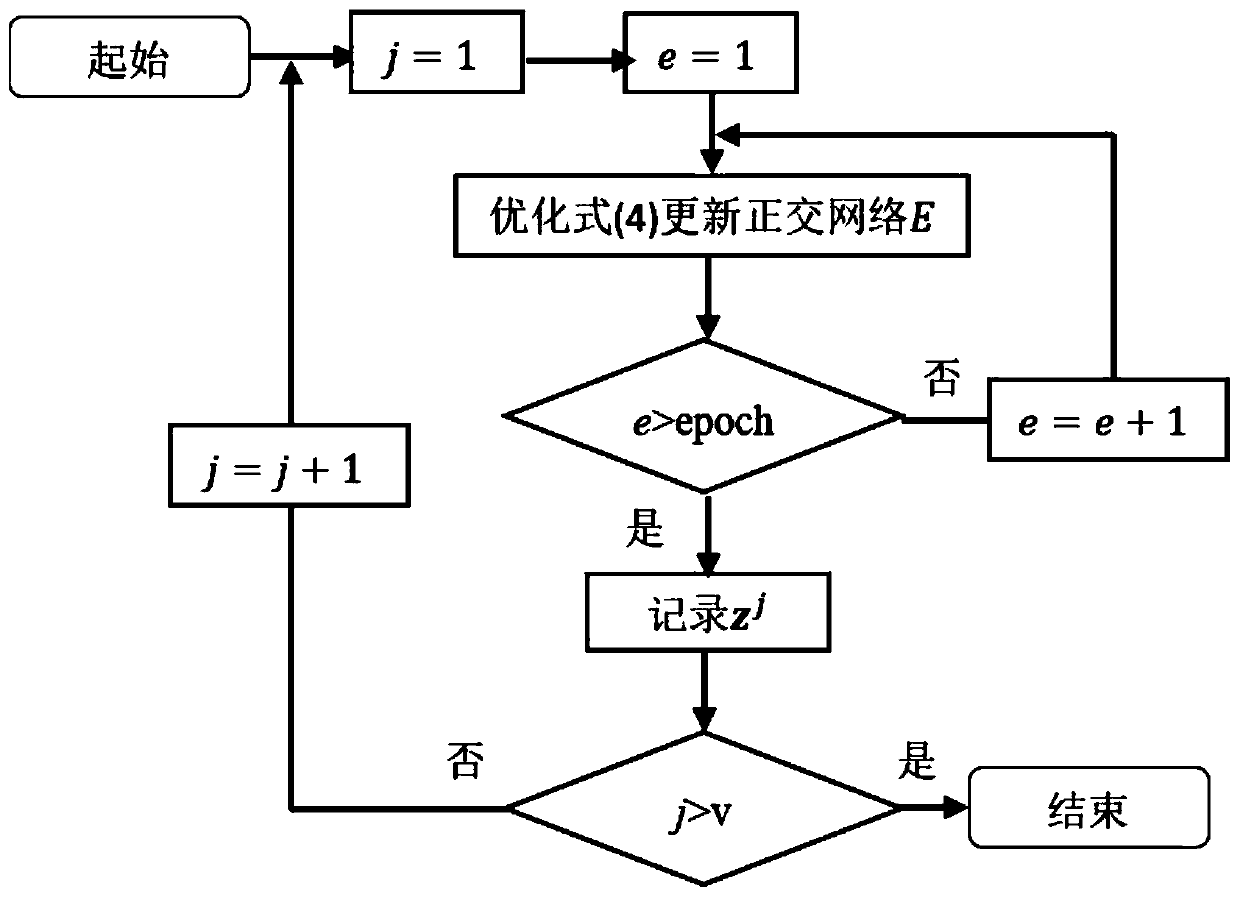
[0028] The present invention will be described in further detail below in conjunction with accompanying drawing, as figure 1 As shown, the video module and the video tagging module store the original video data and all tagging sets. For the original video, the work of feature extraction needs to be completed first. A video can be described from different angles, such as the text description of the video title, the title image expressing the main content of the video, the video frame describing the detailed content of the video, and the audio describing the video expression. to multimodal video features. For video tagging, it is first necessary to select some video samples for manual tagging. In order to prevent taggers with different expressive abilities from using similar but not identical tags for tagging, all tags should come from the tag set. Afterwards, in order to ensure that the number of videos contained in different tags is relatively balanced, it is necessary to fi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More