Near-repetitive image retrieval method based on consistent region deep learning features
A technology of deep learning and image retrieval, which is applied in the field of information security, can solve the problems of inapplicability to near-duplicate images and low retrieval efficiency, and achieve the effects of strong identification ability, improved accuracy, and reduced quantity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

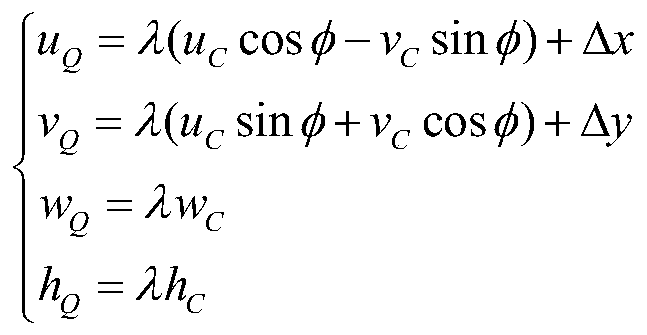
Examples
Embodiment Construction
[0035] The drawings constituting a part of the present invention are used to provide a further understanding of the present invention, and the schematic embodiments and descriptions of the present invention are used to explain the present invention, and do not constitute an improper limitation of the present invention.
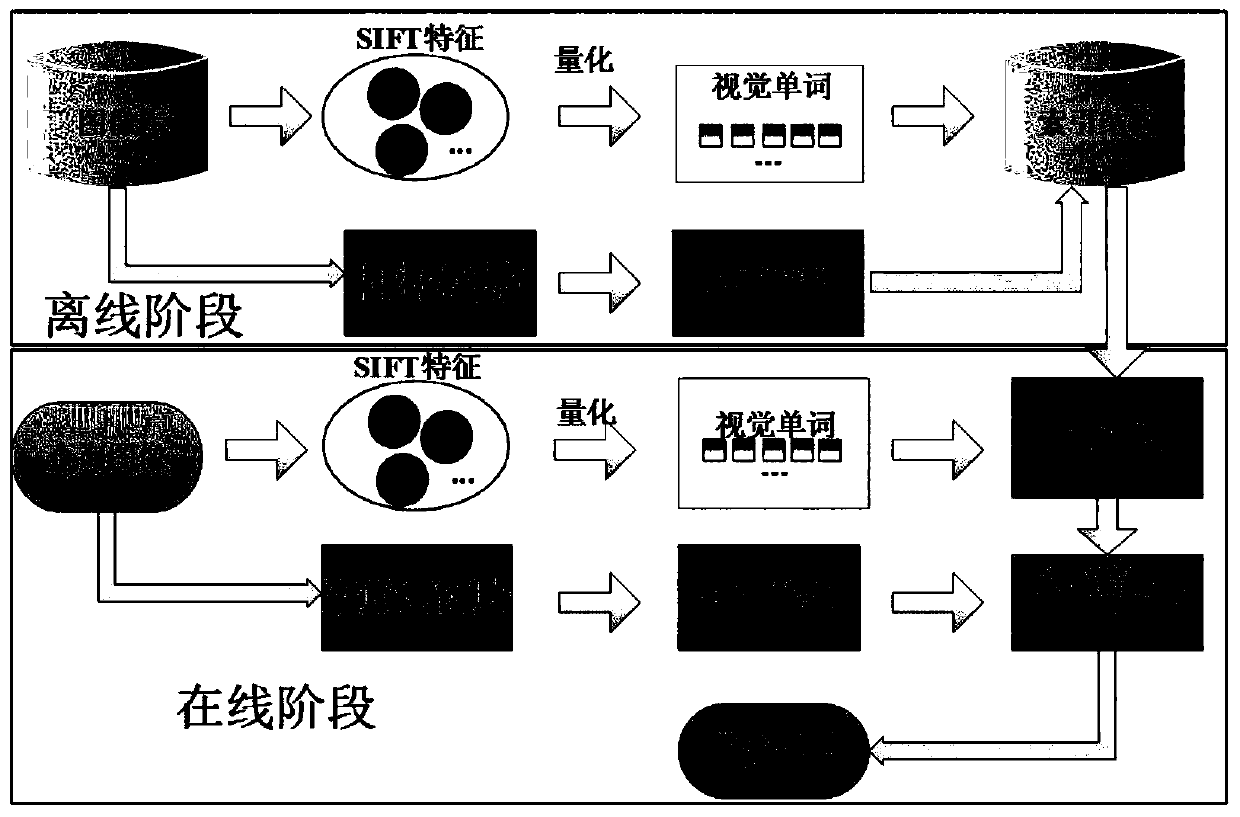
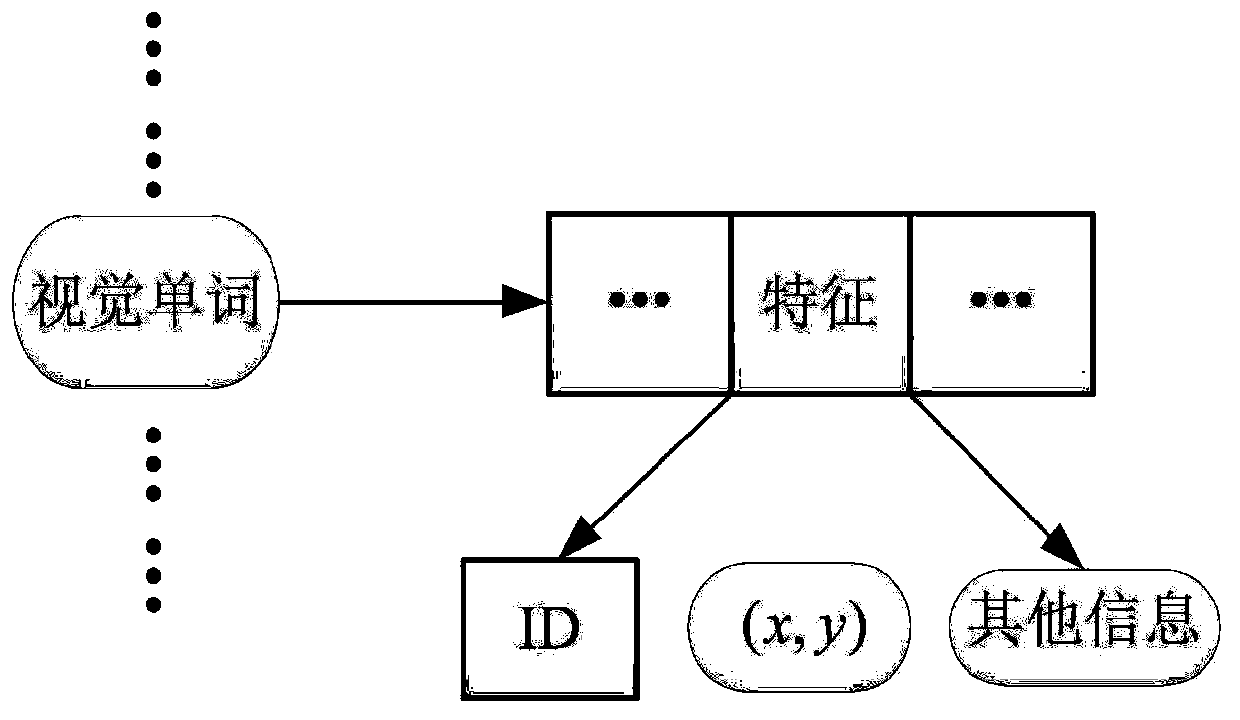
[0036] like figure 1 As shown, this embodiment provides a near-duplicate image retrieval method based on consistent region deep learning features: in the offline stage, extract SIFT features for all images in the image library, and then use the K-Means clustering method to cluster each SIFT Features are quantized into visual words and stored into the constructed inverted index file. In the online stage, use the same feature extraction and quantization method for the input query image, calculate the similarity between the quantized SIFT features and the features in the index file, sort the obtained similarity results, and output the images related to the query ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More