

Data resampling method based on repeated editing nearest neighbor and clustering oversampling
A nearest-neighbor and resampling technology, which is applied in computing models, machine learning, computing, etc., can solve problems such as unbalanced clustering, small separation problems, and amplified data noise, so as to reduce insufficient data volume and improve classification Effect, the effect of solving the class imbalance problem
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

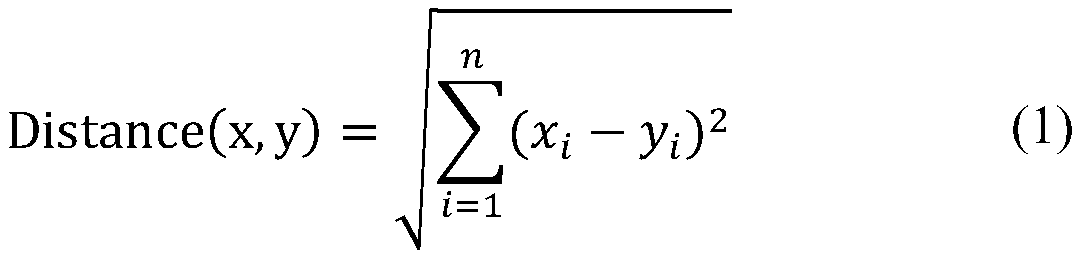
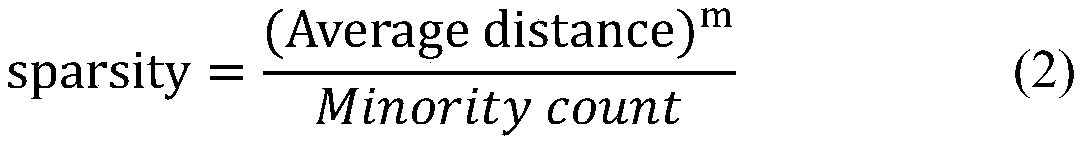
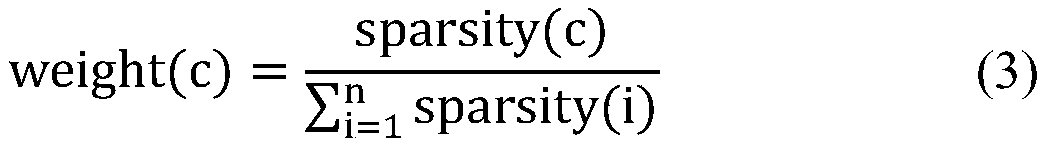
Examples
Embodiment Construction
[0020] Now in conjunction with embodiment the present invention will be further described:
[0021] The experimental data set is the JM1 data set of NASA (National Aeronautics and Space Administration) MDP (metric data program). This dataset is a public dataset provided by NASA and contains software indicators such as McCabe and Halstead. Each software module in the dataset is labeled with a defective or non-defective class label. The present invention uses datasets downloaded from related dataset websites and the open source PROMISE data repository.
[0022] Table 1 JM1 dataset
[0023]
[0024] The data set is divided into four parts: training attribute set, test attribute set, training label set, and test label set. The number of initial samples in the training attribute set is 5213, and the number of samples in the test attribute set is 2569. The method proposed by the present invention is applied to the training attribute set and the training label set. The number ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More