

Voice recognition and voice synthesis model training method and device and computer equipment
A speech synthesis and speech recognition technology, applied in the computer field, can solve the problems of unfavorable speech synthesis system widely popularized, high cost of construction and training of one-way mapping system, saving construction and training cost and improving training effect.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0055] In order to make the purpose, technical solution and advantages of the present application clearer, the present application will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present application, and are not intended to limit the present application.
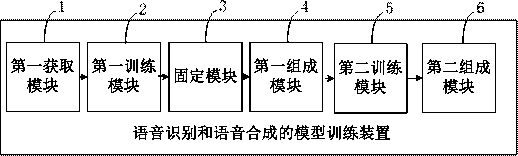
[0056] refer to figure 1 , a model training method for speech recognition and speech synthesis according to an embodiment of the present application, the model includes an audio processing network, an audio restoration network, a text processing network and a text restoration network, and the method includes:
[0057] S1: Obtain the first high-dimensional vector output after the audio processing network processes the voice data of the first data pair in the training set, and obtain the second high-dimensional vector output by the text processing network processing the text...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More