

Voice-driven 3D virtual human expression voice and picture synchronization method and system based on deep learning
A technology of audio and video synchronization and deep learning, which is applied in the fields of speech recognition, computer graphics, computer vision, and speech synthesis to achieve good scalability.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0047] In order to make the above objects, features and advantages of the present invention more comprehensible, the present invention will be further described in detail below through specific embodiments and accompanying drawings.
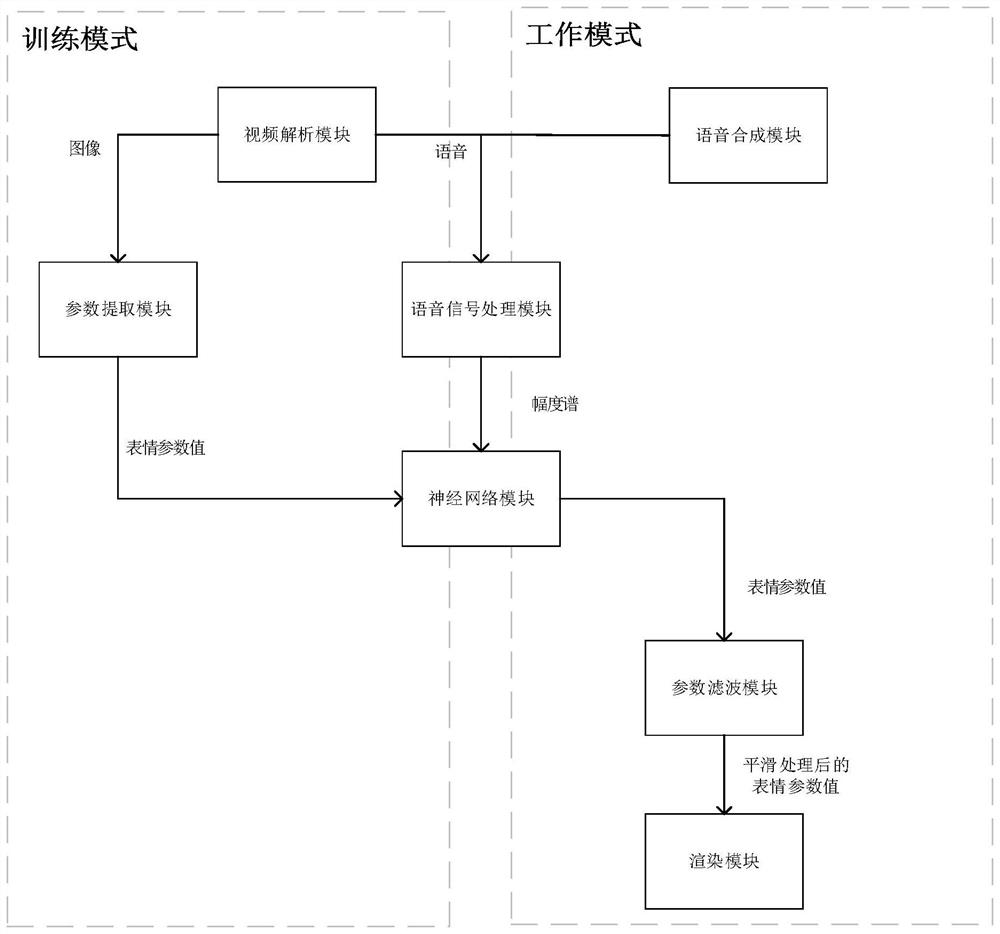
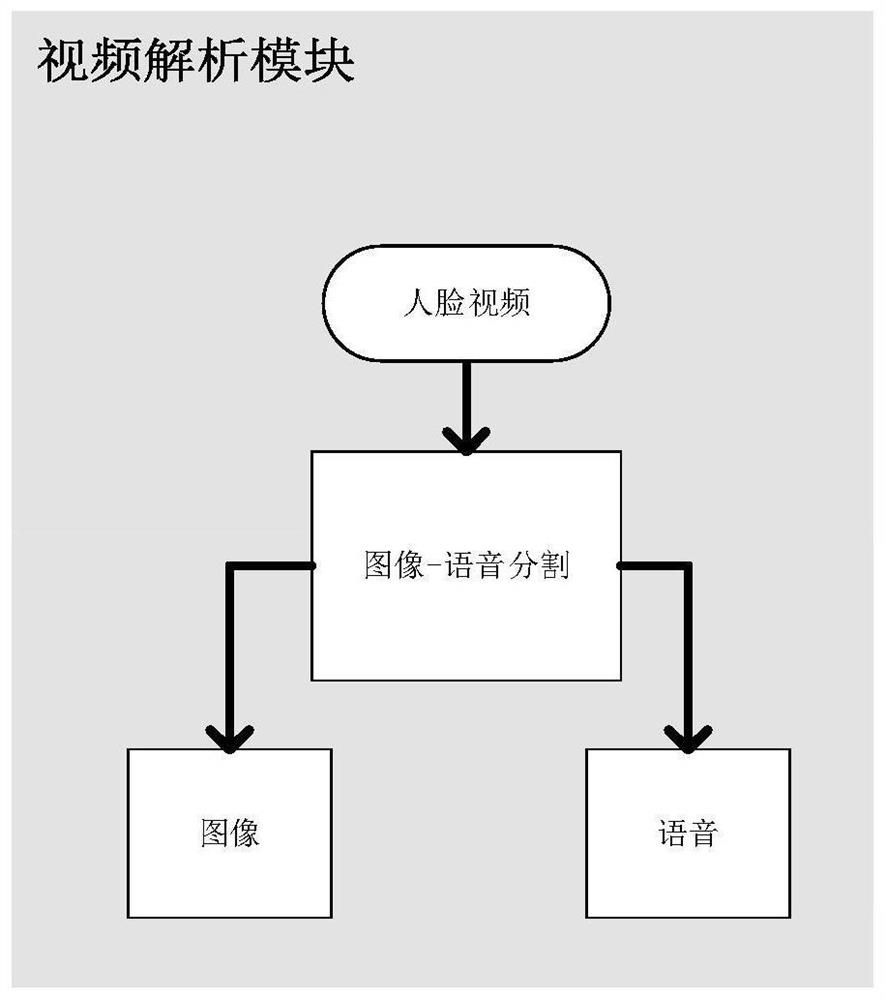
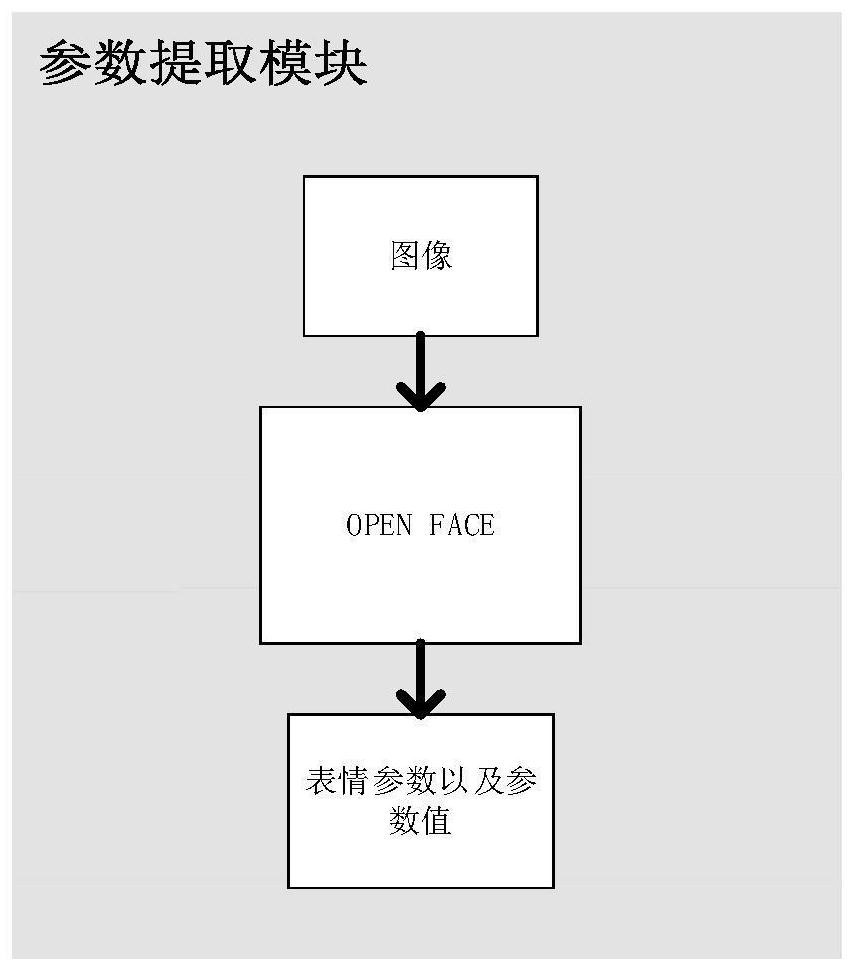
[0048] The deep learning-based voice-driven 3D virtual human facial expression audio-video synchronization system of the present invention includes a video analysis module, a parameter extraction module, a speech synthesis module, a speech signal processing module, a parameter prediction module, a parameter filtering module and a rendering module. All modules are divided into two parts, respectively in training mode and working mode. The modules used in the training mode include: video analysis module, parameter extraction module, voice signal processing module, parameter prediction module. The modules used in the working mode include: speech synthesis module, speech signal processing module, parameter prediction module, parameter filtering modul...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More